 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Overlooked Role of Graded Relevance Thresholds in Multilingual Dense Retrieval
Jan 07, 2026Dense retrieval models are typically fine-tuned with contrastive learning objectives that require binary relevance judgments, even though relevance is inherently graded. We analyze how graded relevance scores and the threshold used to convert them into binary labels affect multilingual dense retrieval. Using a multilingual dataset with LLM-annotated relevance scores, we examine monolingual, multilingual mixture, and cross-lingual retrieval scenarios. Our findings show that the optimal threshold varies systematically across languages and tasks, often reflecting differences in resource level. A well-chosen threshold can improve effectiveness, reduce the amount of fine-tuning data required, and mitigate annotation noise, whereas a poorly chosen one can degrade performance. We argue that graded relevance is a valuable but underutilized signal for dense retrieval, and that threshold calibration should be treated as a principled component of the fine-tuning pipeline.
Consensus or Conflict? Fine-Grained Evaluation of Conflicting Answers in Question-Answering
Aug 17, 2025Large Language Models (LLMs) have demonstrated strong performance in question answering (QA) tasks. However, Multi-Answer Question Answering (MAQA), where a question may have several valid answers, remains challenging. Traditional QA settings often assume consistency across evidences, but MAQA can involve conflicting answers. Constructing datasets that reflect such conflicts is costly and labor-intensive, while existing benchmarks often rely on synthetic data, restrict the task to yes/no questions, or apply unverified automated annotation. To advance research in this area, we extend the conflict-aware MAQA setting to require models not only to identify all valid answers, but also to detect specific conflicting answer pairs, if any. To support this task, we introduce a novel cost-effective methodology for leveraging fact-checking datasets to construct NATCONFQA, a new benchmark for realistic, conflict-aware MAQA, enriched with detailed conflict labels, for all answer pairs. We evaluate eight high-end LLMs on NATCONFQA, revealing their fragility in handling various types of conflicts and the flawed strategies they employ to resolve them.
A Unifying Scheme for Extractive Content Selection Tasks
Jul 22, 2025A broad range of NLP tasks involve selecting relevant text spans from given source texts. Despite this shared objective, such \textit{content selection} tasks have traditionally been studied in isolation, each with its own modeling approaches, datasets, and evaluation metrics. In this work, we propose \textit{instruction-guided content selection (IGCS)} as a beneficial unified framework for such settings, where the task definition and any instance-specific request are encapsulated as instructions to a language model. To promote this framework, we introduce \igcsbench{}, the first unified benchmark covering diverse content selection tasks. Further, we create a large generic synthetic dataset that can be leveraged for diverse content selection tasks, and show that transfer learning with these datasets often boosts performance, whether dedicated training for the targeted task is available or not. Finally, we address generic inference time issues that arise in LLM-based modeling of content selection, assess a generic evaluation metric, and overall propose the utility of our resources and methods for future content selection models. Models and datasets available at https://github.com/shmuelamar/igcs.
Information Types in Product Reviews
Feb 20, 2025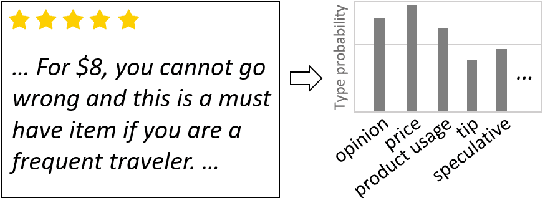
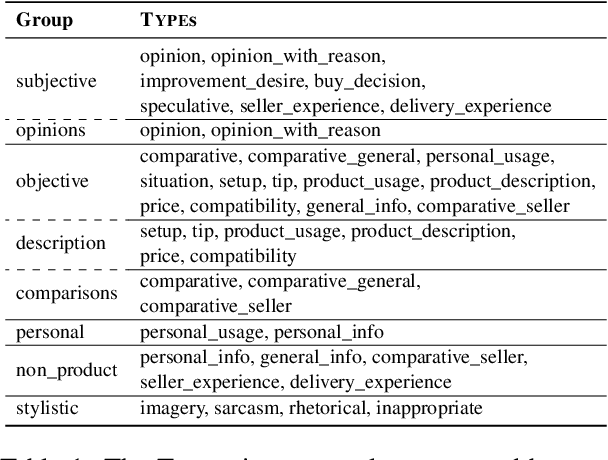
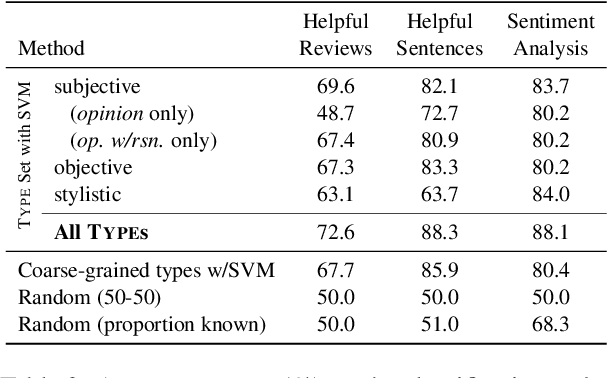
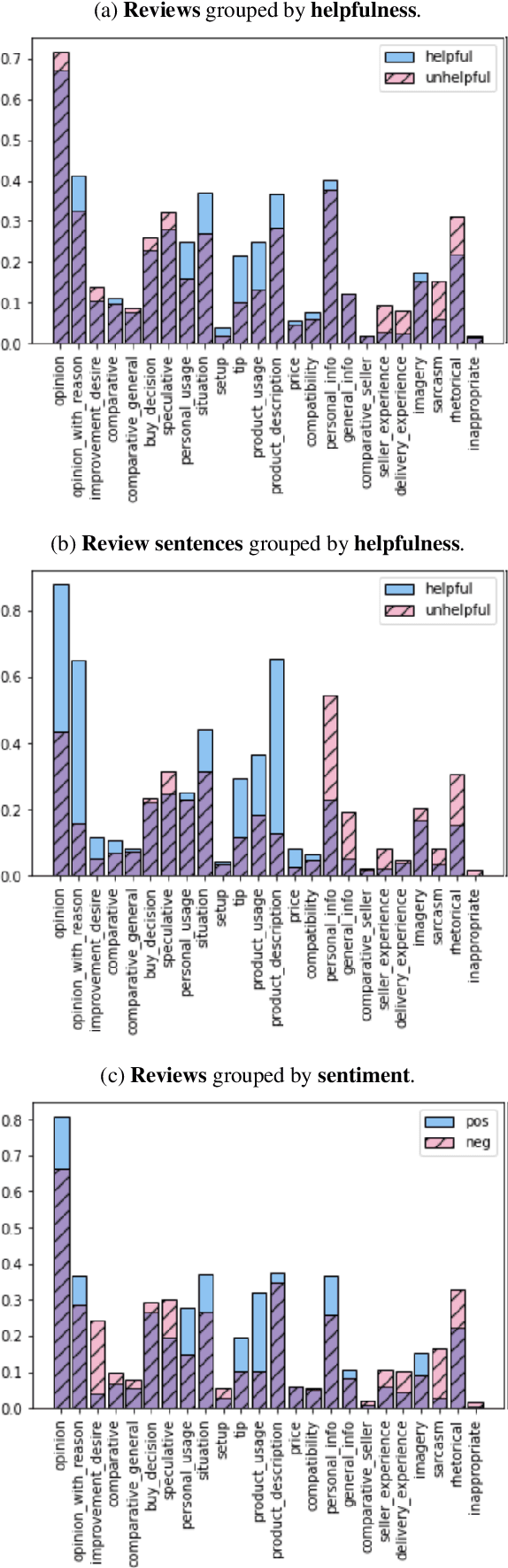
Information in text is communicated in a way that supports a goal for its reader. Product reviews, for example, contain opinions, tips, product descriptions, and many other types of information that provide both direct insights, as well as unexpected signals for downstream applications. We devise a typology of 24 communicative goals in sentences from the product review domain, and employ a zero-shot multi-label classifier that facilitates large-scale analyses of review data. In our experiments, we find that the combination of classes in the typology forecasts helpfulness and sentiment of reviews, while supplying explanations for these decisions. In addition, our typology enables analysis of review intent, effectiveness and rhetorical structure. Characterizing the types of information in reviews unlocks many opportunities for more effective consumption of this genre.
Measuring the Effect of Transcription Noise on Downstream Language Understanding Tasks
Feb 19, 2025With the increasing prevalence of recorded human speech, spoken language understanding (SLU) is essential for its efficient processing. In order to process the speech, it is commonly transcribed using automatic speech recognition technology. This speech-to-text transition introduces errors into the transcripts, which subsequently propagate to downstream NLP tasks, such as dialogue summarization. While it is known that transcript noise affects downstream tasks, a systematic approach to analyzing its effects across different noise severities and types has not been addressed. We propose a configurable framework for assessing task models in diverse noisy settings, and for examining the impact of transcript-cleaning techniques. The framework facilitates the investigation of task model behavior, which can in turn support the development of effective SLU solutions. We exemplify the utility of our framework on three SLU tasks and four task models, offering insights regarding the effect of transcript noise on tasks in general and models in particular. For instance, we find that task models can tolerate a certain level of noise, and are affected differently by the types of errors in the transcript.
Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs
Sep 26, 2024



Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs to use external tools. The first approach uses intuitive, human-defined correctness criteria. The second approach uses a model-driven assessment with in-context evaluation. We conduct a thorough evaluation of data quality on two popular benchmarks, followed by an extrinsic evaluation that showcases the impact of data quality on model performance. Our results demonstrate that models trained on high-quality data outperform those trained on unvalidated data, even when trained with a smaller quantity of data. These findings empirically support the significance of assessing and ensuring the reliability of training data for tool-using LLMs.
SEAM: A Stochastic Benchmark for Multi-Document Tasks
Jun 23, 2024



Various tasks, such as summarization, multi-hop question answering, or coreference resolution, are naturally phrased over collections of real-world documents. Such tasks present a unique set of challenges, revolving around the lack of coherent narrative structure across documents, which often leads to contradiction, omission, or repetition of information. Despite their real-world application and challenging properties, there is currently no benchmark which specifically measures the abilities of large language models (LLMs) on multi-document tasks. To bridge this gap, we present SEAM (a Stochastic Evaluation Approach for Multi-document tasks), a conglomerate benchmark over a diverse set of multi-document datasets, setting conventional evaluation criteria, input-output formats, and evaluation protocols. In particular, SEAM addresses the sensitivity of LLMs to minor prompt variations through repeated evaluations, where in each evaluation we sample uniformly at random the values of arbitrary factors (e.g., the order of documents). We evaluate different LLMs on SEAM finding that multi-document tasks pose a significant challenge for LLMs, even for state-of-the-art models with 70B parameters. In addition, we show that the stochastic approach uncovers underlying statistical trends which cannot be observed in a static benchmark. We hope that SEAM will spur progress via consistent and meaningful evaluation of multi-document tasks.
The Power of Summary-Source Alignments
Jun 02, 2024Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by text generation. In this context, alignment of corresponding sentences between a reference summary and its source documents has been leveraged to generate training data for some of the component tasks. Yet, this enabling alignment step has usually been applied heuristically on the sentence level on a limited number of subtasks. In this paper, we propose extending the summary-source alignment framework by (1) applying it at the more fine-grained proposition span level, (2) annotating alignment manually in a multi-document setup, and (3) revealing the great potential of summary-source alignments to yield several datasets for at least six different tasks. Specifically, for each of the tasks, we release a manually annotated test set that was derived automatically from the alignment annotation. We also release development and train sets in the same way, but from automatically derived alignments. Using the datasets, each task is demonstrated with baseline models and corresponding evaluation metrics to spur future research on this broad challenge.
Multi-Review Fusion-in-Context
Mar 31, 2024



Grounded text generation, encompassing tasks such as long-form question-answering and summarization, necessitates both content selection and content consolidation. Current end-to-end methods are difficult to control and interpret due to their opaqueness. Accordingly, recent works have proposed a modular approach, with separate components for each step. Specifically, we focus on the second subtask, of generating coherent text given pre-selected content in a multi-document setting. Concretely, we formalize Fusion-in-Context (FiC) as a standalone task, whose input consists of source texts with highlighted spans of targeted content. A model then needs to generate a coherent passage that includes all and only the target information. Our work includes the development of a curated dataset of 1000 instances in the reviews domain, alongside a novel evaluation framework for assessing the faithfulness and coverage of highlights, which strongly correlate to human judgment. Several baseline models exhibit promising outcomes and provide insightful analyses. This study lays the groundwork for further exploration of modular text generation in the multi-document setting, offering potential improvements in the quality and reliability of generated content. Our benchmark, FuseReviews, including the dataset, evaluation framework, and designated leaderboard, can be found at https://fusereviews.github.io/.
OpenAsp: A Benchmark for Multi-document Open Aspect-based Summarization
Dec 07, 2023



The performance of automatic summarization models has improved dramatically in recent years. Yet, there is still a gap in meeting specific information needs of users in real-world scenarios, particularly when a targeted summary is sought, such as in the useful aspect-based summarization setting targeted in this paper. Previous datasets and studies for this setting have predominantly concentrated on a limited set of pre-defined aspects, focused solely on single document inputs, or relied on synthetic data. To advance research on more realistic scenarios, we introduce OpenAsp, a benchmark for multi-document \textit{open} aspect-based summarization. This benchmark is created using a novel and cost-effective annotation protocol, by which an open aspect dataset is derived from existing generic multi-document summarization datasets. We analyze the properties of OpenAsp showcasing its high-quality content. Further, we show that the realistic open-aspect setting realized in OpenAsp poses a challenge for current state-of-the-art summarization models, as well as for large language models.