 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCcd
Papers and Code
Denoising the Deep Sky: Physics-Based CCD Noise Formation for Astronomical Imaging
Jan 30, 2026Astronomical imaging remains noise-limited under practical observing constraints, while standard calibration pipelines mainly remove structured artifacts and leave stochastic noise largely unresolved. Learning-based denoising is promising, yet progress is hindered by scarce paired training data and the need for physically interpretable and reproducible models in scientific workflows. We propose a physics-based noise synthesis framework tailored to CCD noise formation. The pipeline models photon shot noise, photo-response non-uniformity, dark-current noise, readout effects, and localized outliers arising from cosmic-ray hits and hot pixels. To obtain low-noise inputs for synthesis, we average multiple unregistered exposures to produce high-SNR bases. Realistic noisy counterparts synthesized from these bases using our noise model enable the construction of abundant paired datasets for supervised learning. We further introduce a real-world dataset across multi-bands acquired with two twin ground-based telescopes, providing paired raw frames and instrument-pipeline calibrated frames, together with calibration data and stacked high-SNR bases for real-world evaluation.
Predict and Resist: Long-Term Accident Anticipation under Sensor Noise
Nov 10, 2025Accident anticipation is essential for proactive and safe autonomous driving, where even a brief advance warning can enable critical evasive actions. However, two key challenges hinder real-world deployment: (1) noisy or degraded sensory inputs from weather, motion blur, or hardware limitations, and (2) the need to issue timely yet reliable predictions that balance early alerts with false-alarm suppression. We propose a unified framework that integrates diffusion-based denoising with a time-aware actor-critic model to address these challenges. The diffusion module reconstructs noise-resilient image and object features through iterative refinement, preserving critical motion and interaction cues under sensor degradation. In parallel, the actor-critic architecture leverages long-horizon temporal reasoning and time-weighted rewards to determine the optimal moment to raise an alert, aligning early detection with reliability. Experiments on three benchmark datasets (DAD, CCD, A3D) demonstrate state-of-the-art accuracy and significant gains in mean time-to-accident, while maintaining robust performance under Gaussian and impulse noise. Qualitative analyses further show that our model produces earlier, more stable, and human-aligned predictions in both routine and highly complex traffic scenarios, highlighting its potential for real-world, safety-critical deployment.
ROAR: Robust Accident Recognition and Anticipation for Autonomous Driving
Nov 09, 2025
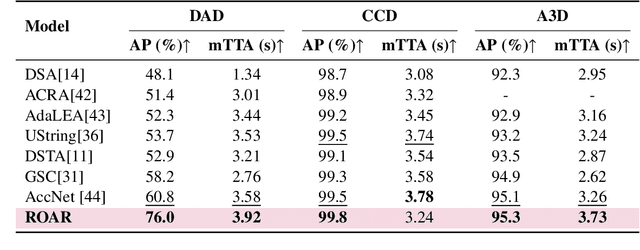
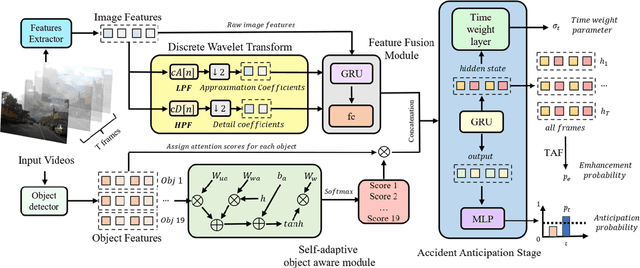
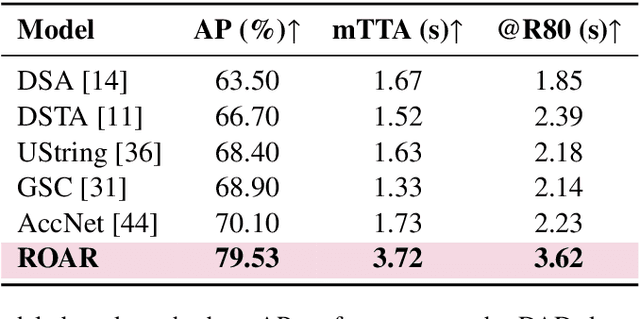
Accurate accident anticipation is essential for enhancing the safety of autonomous vehicles (AVs). However, existing methods often assume ideal conditions, overlooking challenges such as sensor failures, environmental disturbances, and data imperfections, which can significantly degrade prediction accuracy. Additionally, previous models have not adequately addressed the considerable variability in driver behavior and accident rates across different vehicle types. To overcome these limitations, this study introduces ROAR, a novel approach for accident detection and prediction. ROAR combines Discrete Wavelet Transform (DWT), a self adaptive object aware module, and dynamic focal loss to tackle these challenges. The DWT effectively extracts features from noisy and incomplete data, while the object aware module improves accident prediction by focusing on high-risk vehicles and modeling the spatial temporal relationships among traffic agents. Moreover, dynamic focal loss mitigates the impact of class imbalance between positive and negative samples. Evaluated on three widely used datasets, Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), our model consistently outperforms existing baselines in key metrics such as Average Precision (AP) and mean Time to Accident (mTTA). These results demonstrate the model's robustness in real-world conditions, particularly in handling sensor degradation, environmental noise, and imbalanced data distributions. This work offers a promising solution for reliable and accurate accident anticipation in complex traffic environments.
Generative diffusion modeling protocols for improving the Kikuchi pattern indexing in electron back-scatter diffraction
Nov 03, 2025Electron back-scatter diffraction (EBSD) has traditionally relied upon methods such as the Hough transform and dictionary Indexing to interpret diffraction patterns and extract crystallographic orientation. However, these methods encounter significant limitations, particularly when operating at high scanning speeds, where the exposure time per pattern is decreased beyond the operating sensitivity of CCD camera. Hence the signal to noise ratio decreases for the observed pattern which makes the pattern noisy, leading to reduced indexing accuracy. This research work aims to develop generative machine learning models for the post-processing or on-the-fly processing of Kikuchi patterns which are capable of restoring noisy EBSD patterns obtained at high scan speeds. These restored patterns can be used for the determination of crystal orientations to provide reliable indexing results. We compare the performance of such generative models in enhancing the quality of patterns captured at short exposure times (high scan speeds). An interesting observation is that the methodology is not data-hungry as typical machine learning methods.
Sparse Transformer for Ultra-sparse Sampled Video Compressive Sensing
Sep 10, 2025Digital cameras consume ~0.1 microjoule per pixel to capture and encode video, resulting in a power usage of ~20W for a 4K sensor operating at 30 fps. Imagining gigapixel cameras operating at 100-1000 fps, the current processing model is unsustainable. To address this, physical layer compressive measurement has been proposed to reduce power consumption per pixel by 10-100X. Video Snapshot Compressive Imaging (SCI) introduces high frequency modulation in the optical sensor layer to increase effective frame rate. A commonly used sampling strategy of video SCI is Random Sampling (RS) where each mask element value is randomly set to be 0 or 1. Similarly, image inpainting (I2P) has demonstrated that images can be recovered from a fraction of the image pixels. Inspired by I2P, we propose Ultra-Sparse Sampling (USS) regime, where at each spatial location, only one sub-frame is set to 1 and all others are set to 0. We then build a Digital Micro-mirror Device (DMD) encoding system to verify the effectiveness of our USS strategy. Ideally, we can decompose the USS measurement into sub-measurements for which we can utilize I2P algorithms to recover high-speed frames. However, due to the mismatch between the DMD and CCD, the USS measurement cannot be perfectly decomposed. To this end, we propose BSTFormer, a sparse TransFormer that utilizes local Block attention, global Sparse attention, and global Temporal attention to exploit the sparsity of the USS measurement. Extensive results on both simulated and real-world data show that our method significantly outperforms all previous state-of-the-art algorithms. Additionally, an essential advantage of the USS strategy is its higher dynamic range than that of the RS strategy. Finally, from the application perspective, the USS strategy is a good choice to implement a complete video SCI system on chip due to its fixed exposure time.
Active InSAR monitoring of building damage in Gaza during the Israel-Hamas War
Jun 17, 2025Aerial bombardment of the Gaza Strip beginning October 7, 2023 is one of the most intense bombing campaigns of the twenty-first century, driving widespread urban damage. Characterizing damage over a geographically dynamic and protracted armed conflict requires active monitoring. Synthetic aperture radar (SAR) has precedence for mapping disaster-induced damage with bi-temporal methods but applications to active monitoring during sustained crises are limited. Using interferometric SAR data from Sentinel-1, we apply a long temporal-arc coherent change detection (LT-CCD) approach to track weekly damage trends over the first year of the 2023- Israel-Hamas War. We detect 92.5% of damage labels in reference data from the United Nations with a negligible (1.2%) false positive rate. The temporal fidelity of our approach reveals rapidly increasing damage during the first three months of the war focused in northern Gaza, a notable pause in damage during a temporary ceasefire, and surges of new damage as conflict hot-spots shift from north to south. Three-fifths (191,263) of all buildings are damaged or destroyed by the end of the study. With massive need for timely data on damage in armed conflict zones, our low-cost and low-latency approach enables rapid uptake of damage information at humanitarian and journalistic organizations.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025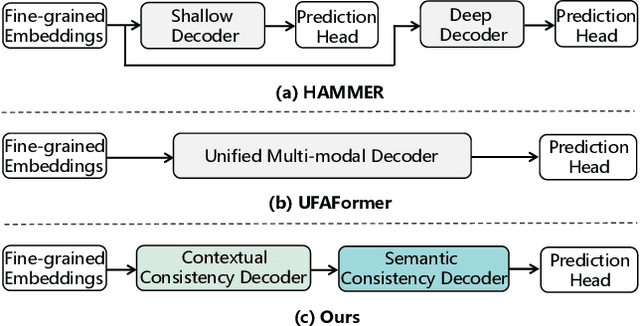
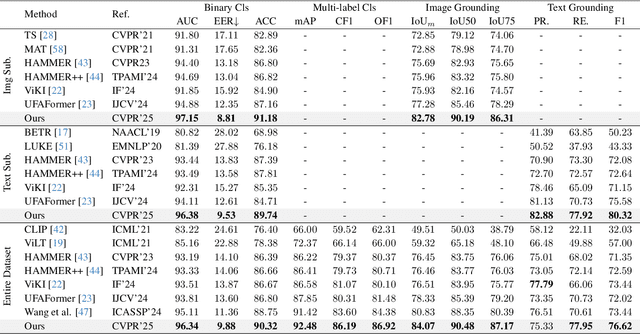
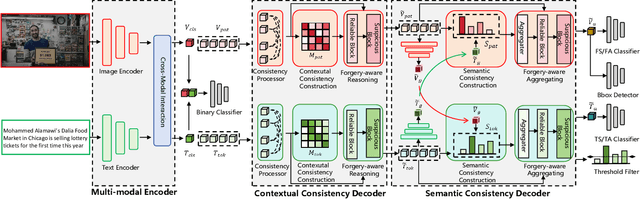
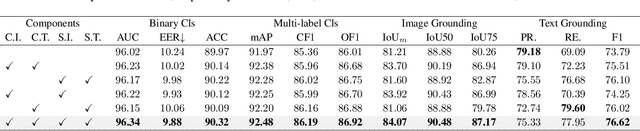
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
Real-time Traffic Accident Anticipation with Feature Reuse
May 23, 2025This paper addresses the problem of anticipating traffic accidents, which aims to forecast potential accidents before they happen. Real-time anticipation is crucial for safe autonomous driving, yet most methods rely on computationally heavy modules like optical flow and intermediate feature extractors, making real-world deployment challenging. In this paper, we thus introduce RARE (Real-time Accident anticipation with Reused Embeddings), a lightweight framework that capitalizes on intermediate features from a single pre-trained object detector. By eliminating additional feature-extraction pipelines, RARE significantly reduces latency. Furthermore, we introduce a novel Attention Score Ranking Loss, which prioritizes higher attention on accident-related objects over non-relevant ones. This loss enhances both accuracy and interpretability. RARE demonstrates a 4-8 times speedup over existing approaches on the DAD and CCD benchmarks, achieving a latency of 13.6ms per frame (73.3 FPS) on an RTX 6000. Moreover, despite its reduced complexity, it attains state-of-the-art Average Precision and reliably anticipates imminent collisions in real time. These results highlight RARE's potential for safety-critical applications where timely and explainable anticipation is essential.
How can Diffusion Models Evolve into Continual Generators?
May 17, 2025While diffusion models have achieved remarkable success in static data generation, their deployment in streaming or continual learning (CL) scenarios faces a major challenge: catastrophic forgetting (CF), where newly acquired generative capabilities overwrite previously learned ones. To systematically address this, we introduce a formal Continual Diffusion Generation (CDG) paradigm that characterizes and redefines CL in the context of generative diffusion models. Prior efforts often adapt heuristic strategies from continual classification tasks but lack alignment with the underlying diffusion process. In this work, we develop the first theoretical framework for CDG by analyzing cross-task dynamics in diffusion-based generative modeling. Our analysis reveals that the retention and stability of generative knowledge across tasks are governed by three key consistency criteria: inter-task knowledge consistency (IKC), unconditional knowledge consistency (UKC), and label knowledge consistency (LKC). Building on these insights, we propose Continual Consistency Diffusion (CCD), a principled framework that integrates these consistency objectives into training via hierarchical loss terms $\mathcal{L}_{IKC}$, $\mathcal{L}_{UKC}$, and $\mathcal{L}_{LKC}$. This promotes effective knowledge retention while enabling the assimilation of new generative capabilities. Extensive experiments on four benchmark datasets demonstrate that CCD achieves state-of-the-art performance under continual settings, with substantial gains in Mean Fidelity (MF) and Incremental Mean Fidelity (IMF), particularly in tasks with rich cross-task knowledge overlap.
VeriContaminated: Assessing LLM-Driven Verilog Coding for Data Contamination
Mar 17, 2025Large Language Models (LLMs) have revolutionized code generation, achieving exceptional results on various established benchmarking frameworks. However, concerns about data contamination - where benchmark data inadvertently leaks into pre-training or fine-tuning datasets - raise questions about the validity of these evaluations. While this issue is known, limiting the industrial adoption of LLM-driven software engineering, hardware coding has received little to no attention regarding these risks. For the first time, we analyze state-of-the-art (SOTA) evaluation frameworks for Verilog code generation (VerilogEval and RTLLM), using established methods for contamination detection (CCD and Min-K% Prob). We cover SOTA commercial and open-source LLMs (CodeGen2.5, Minitron 4b, Mistral 7b, phi-4 mini, LLaMA-{1,2,3.1}, GPT-{2,3.5,4o}, Deepseek-Coder, and CodeQwen 1.5), in baseline and fine-tuned models (RTLCoder and Verigen). Our study confirms that data contamination is a critical concern. We explore mitigations and the resulting trade-offs for code quality vs fairness (i.e., reducing contamination toward unbiased benchmarking).