 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Transformer for Ultra-sparse Sampled Video Compressive Sensing
Sep 10, 2025Digital cameras consume ~0.1 microjoule per pixel to capture and encode video, resulting in a power usage of ~20W for a 4K sensor operating at 30 fps. Imagining gigapixel cameras operating at 100-1000 fps, the current processing model is unsustainable. To address this, physical layer compressive measurement has been proposed to reduce power consumption per pixel by 10-100X. Video Snapshot Compressive Imaging (SCI) introduces high frequency modulation in the optical sensor layer to increase effective frame rate. A commonly used sampling strategy of video SCI is Random Sampling (RS) where each mask element value is randomly set to be 0 or 1. Similarly, image inpainting (I2P) has demonstrated that images can be recovered from a fraction of the image pixels. Inspired by I2P, we propose Ultra-Sparse Sampling (USS) regime, where at each spatial location, only one sub-frame is set to 1 and all others are set to 0. We then build a Digital Micro-mirror Device (DMD) encoding system to verify the effectiveness of our USS strategy. Ideally, we can decompose the USS measurement into sub-measurements for which we can utilize I2P algorithms to recover high-speed frames. However, due to the mismatch between the DMD and CCD, the USS measurement cannot be perfectly decomposed. To this end, we propose BSTFormer, a sparse TransFormer that utilizes local Block attention, global Sparse attention, and global Temporal attention to exploit the sparsity of the USS measurement. Extensive results on both simulated and real-world data show that our method significantly outperforms all previous state-of-the-art algorithms. Additionally, an essential advantage of the USS strategy is its higher dynamic range than that of the RS strategy. Finally, from the application perspective, the USS strategy is a good choice to implement a complete video SCI system on chip due to its fixed exposure time.
Proximal Algorithm Unrolling: Flexible and Efficient Reconstruction Networks for Single-Pixel Imaging
May 29, 2025Deep-unrolling and plug-and-play (PnP) approaches have become the de-facto standard solvers for single-pixel imaging (SPI) inverse problem. PnP approaches, a class of iterative algorithms where regularization is implicitly performed by an off-the-shelf deep denoiser, are flexible for varying compression ratios (CRs) but are limited in reconstruction accuracy and speed. Conversely, unrolling approaches, a class of multi-stage neural networks where a truncated iterative optimization process is transformed into an end-to-end trainable network, typically achieve better accuracy with faster inference but require fine-tuning or even retraining when CR changes. In this paper, we address the challenge of integrating the strengths of both classes of solvers. To this end, we design an efficient deep image restorer (DIR) for the unrolling of HQS (half quadratic splitting) and ADMM (alternating direction method of multipliers). More importantly, a general proximal trajectory (PT) loss function is proposed to train HQS/ADMM-unrolling networks such that learned DIR approximates the proximal operator of an ideal explicit restoration regularizer. Extensive experiments demonstrate that, the resulting proximal unrolling networks can not only flexibly handle varying CRs with a single model like PnP algorithms, but also outperform previous CR-specific unrolling networks in both reconstruction accuracy and speed. Source codes and models are available at https://github.com/pwangcs/ProxUnroll.
Towards Real-time Video Compressive Sensing on Mobile Devices
Aug 14, 2024



Video Snapshot Compressive Imaging (SCI) uses a low-speed 2D camera to capture high-speed scenes as snapshot compressed measurements, followed by a reconstruction algorithm to retrieve the high-speed video frames. The fast evolving mobile devices and existing high-performance video SCI reconstruction algorithms motivate us to develop mobile reconstruction methods for real-world applications. Yet, it is still challenging to deploy previous reconstruction algorithms on mobile devices due to the complex inference process, let alone real-time mobile reconstruction. To the best of our knowledge, there is no video SCI reconstruction model designed to run on the mobile devices. Towards this end, in this paper, we present an effective approach for video SCI reconstruction, dubbed MobileSCI, which can run at real-time speed on the mobile devices for the first time. Specifically, we first build a U-shaped 2D convolution-based architecture, which is much more efficient and mobile-friendly than previous state-of-the-art reconstruction methods. Besides, an efficient feature mixing block, based on the channel splitting and shuffling mechanisms, is introduced as a novel bottleneck block of our proposed MobileSCI to alleviate the computational burden. Finally, a customized knowledge distillation strategy is utilized to further improve the reconstruction quality. Extensive results on both simulated and real data show that our proposed MobileSCI can achieve superior reconstruction quality with high efficiency on the mobile devices. Particularly, we can reconstruct a 256 X 256 X 8 snapshot compressed measurement with real-time performance (about 35 FPS) on an iPhone 15. Code is available at https://github.com/mcao92/MobileSCI.
A Simple Low-bit Quantization Framework for Video Snapshot Compressive Imaging
Jul 31, 2024



Video Snapshot Compressive Imaging (SCI) aims to use a low-speed 2D camera to capture high-speed scene as snapshot compressed measurements, followed by a reconstruction algorithm to reconstruct the high-speed video frames. State-of-the-art (SOTA) deep learning-based algorithms have achieved impressive performance, yet with heavy computational workload. Network quantization is a promising way to reduce computational cost. However, a direct low-bit quantization will bring large performance drop. To address this challenge, in this paper, we propose a simple low-bit quantization framework (dubbed Q-SCI) for the end-to-end deep learning-based video SCI reconstruction methods which usually consist of a feature extraction, feature enhancement, and video reconstruction module. Specifically, we first design a high-quality feature extraction module and a precise video reconstruction module to extract and propagate high-quality features in the low-bit quantized model. In addition, to alleviate the information distortion of the Transformer branch in the quantized feature enhancement module, we introduce a shift operation on the query and key distributions to further bridge the performance gap. Comprehensive experimental results manifest that our Q-SCI framework can achieve superior performance, e.g., 4-bit quantized EfficientSCI-S derived by our Q-SCI framework can theoretically accelerate the real-valued EfficientSCI-S by 7.8X with only 2.3% performance gap on the simulation testing datasets. Code is available at https://github.com/mcao92/QuantizedSCI.
Hierarchical Separable Video Transformer for Snapshot Compressive Imaging
Jul 16, 2024



Transformers have achieved the state-of-the-art performance on solving the inverse problem of Snapshot Compressive Imaging (SCI) for video, whose ill-posedness is rooted in the mixed degradation of spatial masking and temporal aliasing. However, previous Transformers lack an insight into the degradation and thus have limited performance and efficiency. In this work, we tailor an efficient reconstruction architecture without temporal aggregation in early layers and Hierarchical Separable Video Transformer (HiSViT) as building block. HiSViT is built by multiple groups of Cross-Scale Separable Multi-head Self-Attention (CSS-MSA) and Gated Self-Modulated Feed-Forward Network (GSM-FFN) with dense connections, each of which is conducted within a separate channel portions at a different scale, for multi-scale interactions and long-range modeling. By separating spatial operations from temporal ones, CSS-MSA introduces an inductive bias of paying more attention within frames instead of between frames while saving computational overheads. GSM-FFN is design to enhance the locality via gated mechanism and factorized spatial-temporal convolutions. Extensive experiments demonstrate that our method outperforms previous methods by $>\!0.5$ dB with comparable or fewer complexity and parameters. The source codes and pretrained models are released at https://github.com/pwangcs/HiSViT.
Coarse-Fine Spectral-Aware Deformable Convolution For Hyperspectral Image Reconstruction
Jun 18, 2024



We study the inverse problem of Coded Aperture Snapshot Spectral Imaging (CASSI), which captures a spatial-spectral data cube using snapshot 2D measurements and uses algorithms to reconstruct 3D hyperspectral images (HSI). However, current methods based on Convolutional Neural Networks (CNNs) struggle to capture long-range dependencies and non-local similarities. The recently popular Transformer-based methods are poorly deployed on downstream tasks due to the high computational cost caused by self-attention. In this paper, we propose Coarse-Fine Spectral-Aware Deformable Convolution Network (CFSDCN), applying deformable convolutional networks (DCN) to this task for the first time. Considering the sparsity of HSI, we design a deformable convolution module that exploits its deformability to capture long-range dependencies and non-local similarities. In addition, we propose a new spectral information interaction module that considers both coarse-grained and fine-grained spectral similarities. Extensive experiments demonstrate that our CFSDCN significantly outperforms previous state-of-the-art (SOTA) methods on both simulated and real HSI datasets.
Deep Optics for Video Snapshot Compressive Imaging
Apr 08, 2024



Video snapshot compressive imaging (SCI) aims to capture a sequence of video frames with only a single shot of a 2D detector, whose backbones rest in optical modulation patterns (also known as masks) and a computational reconstruction algorithm. Advanced deep learning algorithms and mature hardware are putting video SCI into practical applications. Yet, there are two clouds in the sunshine of SCI: i) low dynamic range as a victim of high temporal multiplexing, and ii) existing deep learning algorithms' degradation on real system. To address these challenges, this paper presents a deep optics framework to jointly optimize masks and a reconstruction network. Specifically, we first propose a new type of structural mask to realize motion-aware and full-dynamic-range measurement. Considering the motion awareness property in measurement domain, we develop an efficient network for video SCI reconstruction using Transformer to capture long-term temporal dependencies, dubbed Res2former. Moreover, sensor response is introduced into the forward model of video SCI to guarantee end-to-end model training close to real system. Finally, we implement the learned structural masks on a digital micro-mirror device. Experimental results on synthetic and real data validate the effectiveness of the proposed framework. We believe this is a milestone for real-world video SCI. The source code and data are available at https://github.com/pwangcs/DeepOpticsSCI.
EfficientSCI: Densely Connected Network with Space-time Factorization for Large-scale Video Snapshot Compressive Imaging
May 18, 2023Video snapshot compressive imaging (SCI) uses a two-dimensional detector to capture consecutive video frames during a single exposure time. Following this, an efficient reconstruction algorithm needs to be designed to reconstruct the desired video frames. Although recent deep learning-based state-of-the-art (SOTA) reconstruction algorithms have achieved good results in most tasks, they still face the following challenges due to excessive model complexity and GPU memory limitations: 1) these models need high computational cost, and 2) they are usually unable to reconstruct large-scale video frames at high compression ratios. To address these issues, we develop an efficient network for video SCI by using dense connections and space-time factorization mechanism within a single residual block, dubbed EfficientSCI. The EfficientSCI network can well establish spatial-temporal correlation by using convolution in the spatial domain and Transformer in the temporal domain, respectively. We are the first time to show that an UHD color video with high compression ratio can be reconstructed from a snapshot 2D measurement using a single end-to-end deep learning model with PSNR above 32 dB. Extensive results on both simulation and real data show that our method significantly outperforms all previous SOTA algorithms with better real-time performance. The code is at https://github.com/ucaswangls/EfficientSCI.git.
Spatial-Temporal Transformer for Video Snapshot Compressive Imaging
Sep 08, 2022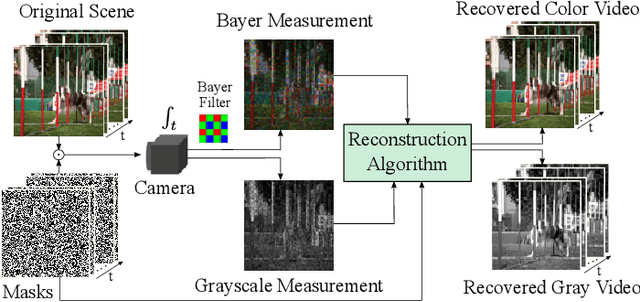
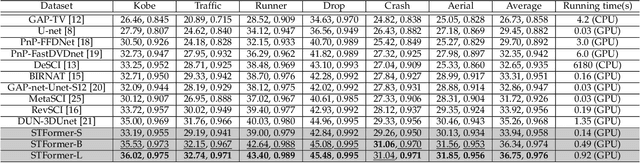
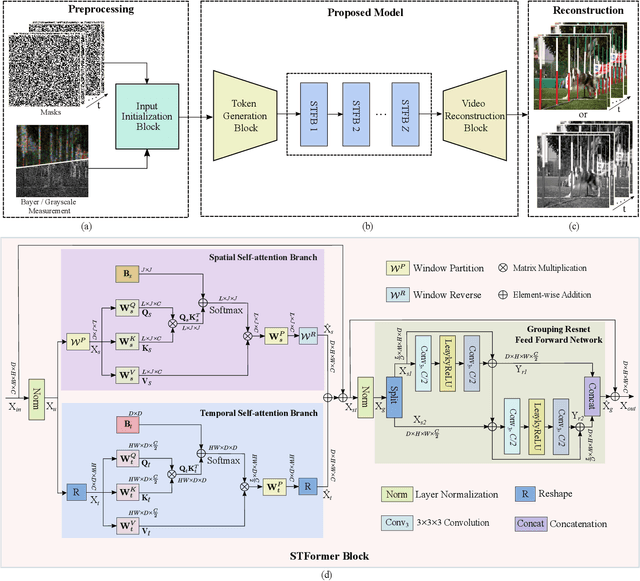
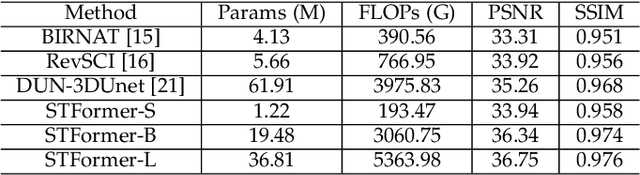
Video snapshot compressive imaging (SCI) captures multiple sequential video frames by a single measurement using the idea of computational imaging. The underlying principle is to modulate high-speed frames through different masks and these modulated frames are summed to a single measurement captured by a low-speed 2D sensor (dubbed optical encoder); following this, algorithms are employed to reconstruct the desired high-speed frames (dubbed software decoder) if needed. In this paper, we consider the reconstruction algorithm in video SCI, i.e., recovering a series of video frames from a compressed measurement. Specifically, we propose a Spatial-Temporal transFormer (STFormer) to exploit the correlation in both spatial and temporal domains. STFormer network is composed of a token generation block, a video reconstruction block, and these two blocks are connected by a series of STFormer blocks. Each STFormer block consists of a spatial self-attention branch, a temporal self-attention branch and the outputs of these two branches are integrated by a fusion network. Extensive results on both simulated and real data demonstrate the state-of-the-art performance of STFormer. The code and models are publicly available at https://github.com/ucaswangls/STFormer.git
Spectral Compressive Imaging Reconstruction Using Convolution and Spectral Contextual Transformer
Jan 15, 2022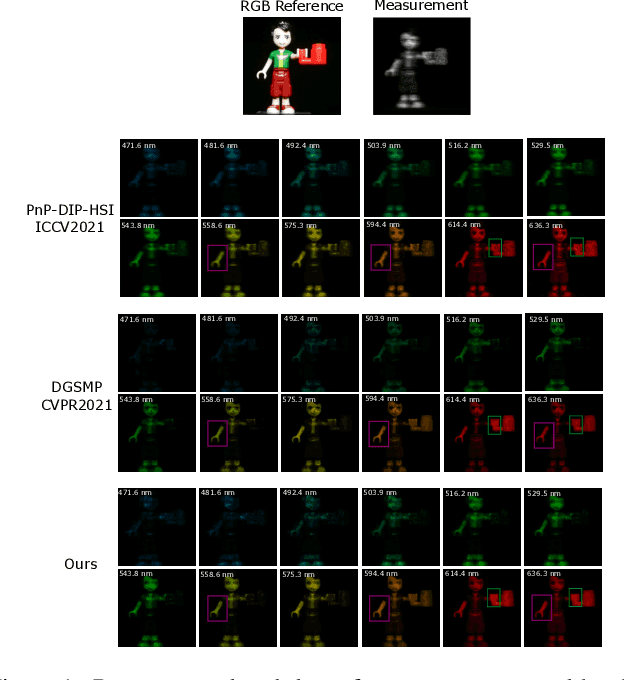
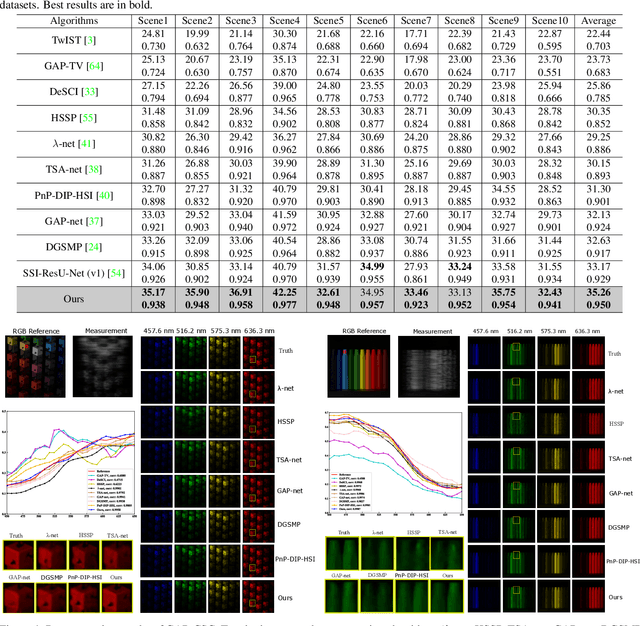
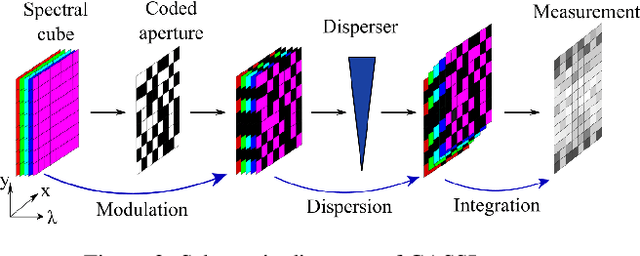

Spectral compressive imaging (SCI) is able to encode the high-dimensional hyperspectral image to a 2D measurement, and then uses algorithms to reconstruct the spatio-spectral data-cube. At present, the main bottleneck of SCI is the reconstruction algorithm, and the state-of-the-art (SOTA) reconstruction methods generally face the problem of long reconstruction time and/or poor detail recovery. In this paper, we propose a novel hybrid network module, namely CSCoT (Convolution and Spectral Contextual Transformer) block, which can acquire the local perception of convolution and the global perception of transformer simultaneously, and is conducive to improving the quality of reconstruction to restore fine details. We integrate the proposed CSCoT block into deep unfolding framework based on the generalized alternating projection algorithm, and further propose the GAP-CSCoT network. Finally, we apply the GAP-CSCoT algorithm to SCI reconstruction. Through the experiments of extensive synthetic and real data, our proposed model achieves higher reconstruction quality ($>$2dB in PSNR on simulated benchmark datasets) and shorter running time than existing SOTA algorithms by a large margin. The code and models will be released to the public.