 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredict and Resist: Long-Term Accident Anticipation under Sensor Noise
Nov 10, 2025Accident anticipation is essential for proactive and safe autonomous driving, where even a brief advance warning can enable critical evasive actions. However, two key challenges hinder real-world deployment: (1) noisy or degraded sensory inputs from weather, motion blur, or hardware limitations, and (2) the need to issue timely yet reliable predictions that balance early alerts with false-alarm suppression. We propose a unified framework that integrates diffusion-based denoising with a time-aware actor-critic model to address these challenges. The diffusion module reconstructs noise-resilient image and object features through iterative refinement, preserving critical motion and interaction cues under sensor degradation. In parallel, the actor-critic architecture leverages long-horizon temporal reasoning and time-weighted rewards to determine the optimal moment to raise an alert, aligning early detection with reliability. Experiments on three benchmark datasets (DAD, CCD, A3D) demonstrate state-of-the-art accuracy and significant gains in mean time-to-accident, while maintaining robust performance under Gaussian and impulse noise. Qualitative analyses further show that our model produces earlier, more stable, and human-aligned predictions in both routine and highly complex traffic scenarios, highlighting its potential for real-world, safety-critical deployment.
ROAR: Robust Accident Recognition and Anticipation for Autonomous Driving
Nov 09, 2025
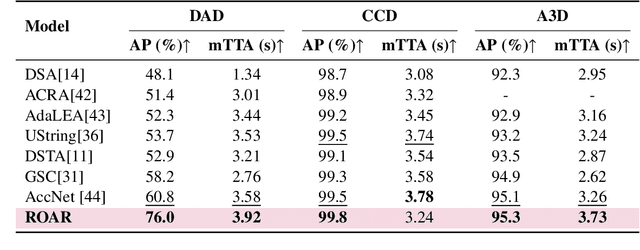
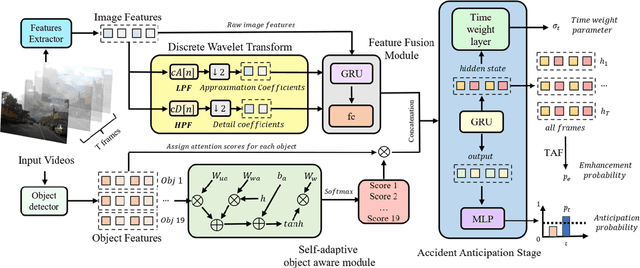
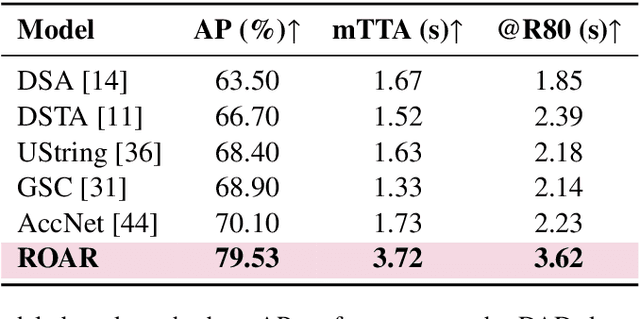
Accurate accident anticipation is essential for enhancing the safety of autonomous vehicles (AVs). However, existing methods often assume ideal conditions, overlooking challenges such as sensor failures, environmental disturbances, and data imperfections, which can significantly degrade prediction accuracy. Additionally, previous models have not adequately addressed the considerable variability in driver behavior and accident rates across different vehicle types. To overcome these limitations, this study introduces ROAR, a novel approach for accident detection and prediction. ROAR combines Discrete Wavelet Transform (DWT), a self adaptive object aware module, and dynamic focal loss to tackle these challenges. The DWT effectively extracts features from noisy and incomplete data, while the object aware module improves accident prediction by focusing on high-risk vehicles and modeling the spatial temporal relationships among traffic agents. Moreover, dynamic focal loss mitigates the impact of class imbalance between positive and negative samples. Evaluated on three widely used datasets, Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), our model consistently outperforms existing baselines in key metrics such as Average Precision (AP) and mean Time to Accident (mTTA). These results demonstrate the model's robustness in real-world conditions, particularly in handling sensor degradation, environmental noise, and imbalanced data distributions. This work offers a promising solution for reliable and accurate accident anticipation in complex traffic environments.