 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasia Surf
Papers and Code
A Closer Look at Geometric Temporal Dynamics for Face Anti-Spoofing
Jun 25, 2023



Face anti-spoofing (FAS) is indispensable for a face recognition system. Many texture-driven countermeasures were developed against presentation attacks (PAs), but the performance against unseen domains or unseen spoofing types is still unsatisfactory. Instead of exhaustively collecting all the spoofing variations and making binary decisions of live/spoof, we offer a new perspective on the FAS task to distinguish between normal and abnormal movements of live and spoof presentations. We propose Geometry-Aware Interaction Network (GAIN), which exploits dense facial landmarks with spatio-temporal graph convolutional network (ST-GCN) to establish a more interpretable and modularized FAS model. Additionally, with our cross-attention feature interaction mechanism, GAIN can be easily integrated with other existing methods to significantly boost performance. Our approach achieves state-of-the-art performance in the standard intra- and cross-dataset evaluations. Moreover, our model outperforms state-of-the-art methods by a large margin in the cross-dataset cross-type protocol on CASIA-SURF 3DMask (+10.26% higher AUC score), exhibiting strong robustness against domain shifts and unseen spoofing types.
Composite Fixed-Length Ordered Features for Palmprint Template Protection with Diminished Performance Loss
Nov 09, 2022



Palmprint recognition has become more and more popular due to its advantages over other biometric modalities such as fingerprint, in that it is larger in area, richer in information and able to work at a distance. However, the issue of palmprint privacy and security (especially palmprint template protection) remains under-studied. Among the very few research works, most of them only use the directional and orientation features of the palmprint with transformation processing, yielding unsatisfactory protection and identification performance. Thus, this paper proposes a palmprint template protection-oriented operator that has a fixed length and is ordered in nature, by fusing point features and orientation features. Firstly, double orientations are extracted with more accuracy based on MFRAT. Then key points of SURF are extracted and converted to be fixed-length and ordered features. Finally, composite features that fuse up the double orientations and SURF points are transformed using the irreversible transformation of IOM to generate the revocable palmprint template. Experiments show that the EER after irreversible transformation on the PolyU and CASIA databases are 0.17% and 0.19% respectively, and the absolute precision loss is 0.08% and 0.07%, respectively, which proves the advantage of our method.
3D High-Fidelity Mask Face Presentation Attack Detection Challenge
Aug 16, 2021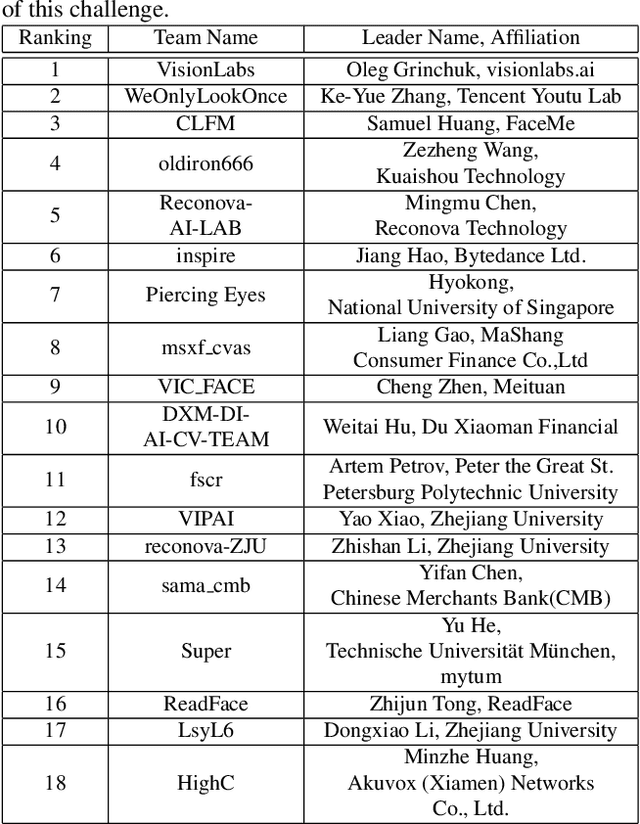
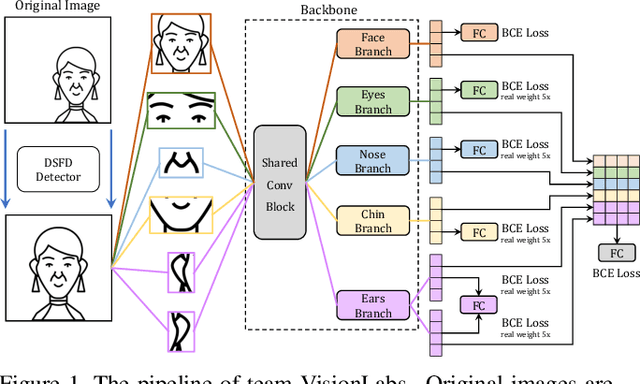
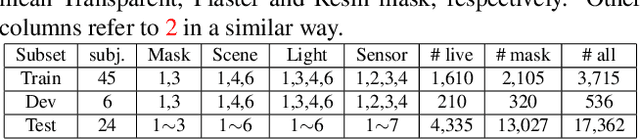
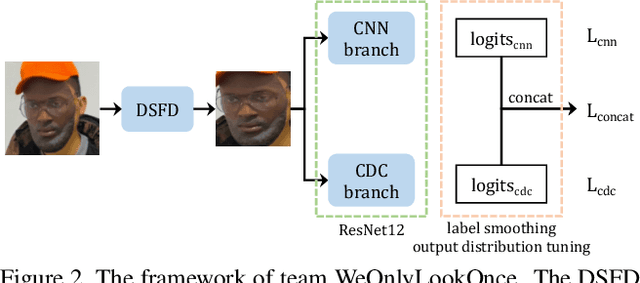
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers. To facilitate the study of the algorithms, a large-scale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask) has been collected. Specifically, it consists of a total amount of 54, 600 videos which are recorded from 75 subjects with 225 realistic masks under 7 new kinds of sensors. Based on this dataset and Protocol 3 which evaluates both the discrimination and generalization ability of the algorithm under the open set scenarios, we organized a 3D High-Fidelity Mask Face Presentation Attack Detection Challenge to boost the research of 3D mask-based attack detection. It attracted 195 teams for the development phase with a total of 18 teams qualifying for the final round. All the results were verified and re-run by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including the introduction of the dataset used, the definition of the protocol, the calculation of the evaluation criteria, and the summary and publication of the competition results. Finally, we focus on introducing and analyzing the top ranking algorithms, the conclusion summary, and the research ideas for mask attack detection provided by this competition.
Improved Detection of Face Presentation Attacks Using Image Decomposition
Mar 22, 2021



Presentation attack detection (PAD) is a critical component in secure face authentication. We present a PAD algorithm to distinguish face spoofs generated by a photograph of a subject from live images. Our method uses an image decomposition network to extract albedo and normal. The domain gap between the real and spoof face images leads to easily identifiable differences, especially between the recovered albedo maps. We enhance this domain gap by retraining existing methods using supervised contrastive loss. We present empirical and theoretical analysis that demonstrates that the contrast and lighting effects can play a significant role in PAD; these show up particularly in the recovered albedo. Finally, we demonstrate that by combining all of these methods we achieve state-of-the-art results on datasets such as CelebA-Spoof, OULU and CASIA-SURF.
A Dataset and Benchmark Towards Multi-Modal Face Anti-Spoofing Under Surveillance Scenarios
Mar 29, 2021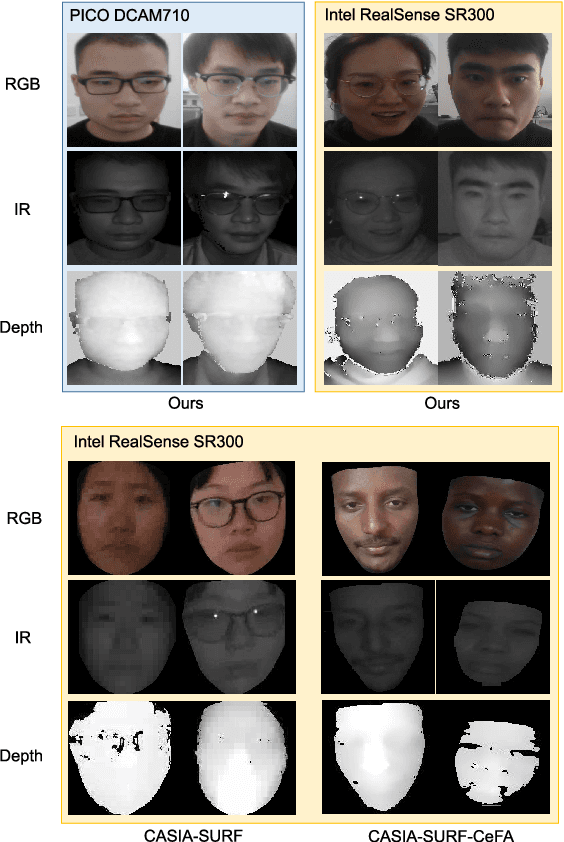


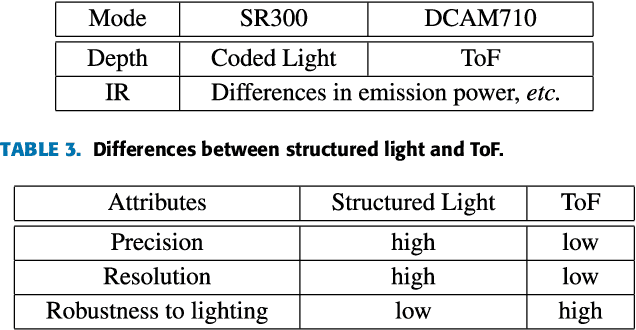
Face Anti-spoofing (FAS) is a challenging problem due to complex serving scenarios and diverse face presentation attack patterns. Especially when captured images are low-resolution, blurry, and coming from different domains, the performance of FAS will degrade significantly. The existing multi-modal FAS datasets rarely pay attention to the cross-domain problems under deployment scenarios, which is not conducive to the study of model performance. To solve these problems, we explore the fine-grained differences between multi-modal cameras and construct a cross-domain multi-modal FAS dataset under surveillance scenarios called GREAT-FASD-S. Besides, we propose an Attention based Face Anti-spoofing network with Feature Augment (AFA) to solve the FAS towards low-quality face images. It consists of the depthwise separable attention module (DAM) and the multi-modal based feature augment module (MFAM). Our model can achieve state-of-the-art performance on the CASIA-SURF dataset and our proposed GREAT-FASD-S dataset.
* Published in: IEEE Access
Contrastive Context-Aware Learning for 3D High-Fidelity Mask Face Presentation Attack Detection
Apr 13, 2021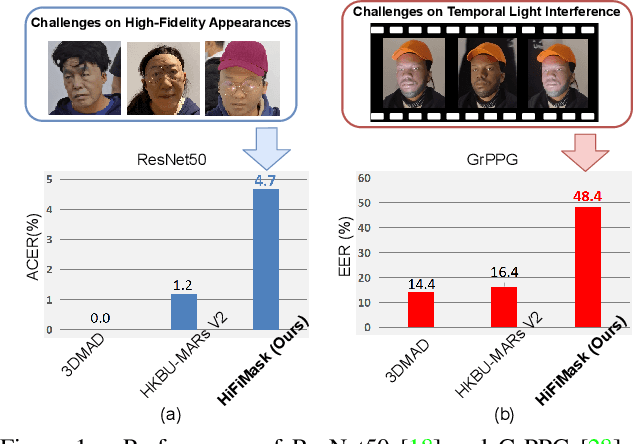
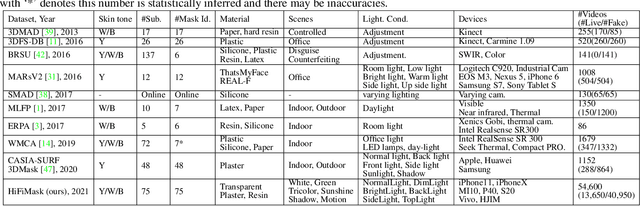

Face presentation attack detection (PAD) is essential to secure face recognition systems primarily from high-fidelity mask attacks. Most existing 3D mask PAD benchmarks suffer from several drawbacks: 1) a limited number of mask identities, types of sensors, and a total number of videos; 2) low-fidelity quality of facial masks. Basic deep models and remote photoplethysmography (rPPG) methods achieved acceptable performance on these benchmarks but still far from the needs of practical scenarios. To bridge the gap to real-world applications, we introduce a largescale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask). Specifically, a total amount of 54,600 videos are recorded from 75 subjects with 225 realistic masks by 7 new kinds of sensors. Together with the dataset, we propose a novel Contrastive Context-aware Learning framework, namely CCL. CCL is a new training methodology for supervised PAD tasks, which is able to learn by leveraging rich contexts accurately (e.g., subjects, mask material and lighting) among pairs of live faces and high-fidelity mask attacks. Extensive experimental evaluations on HiFiMask and three additional 3D mask datasets demonstrate the effectiveness of our method.
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
Mar 11, 2020
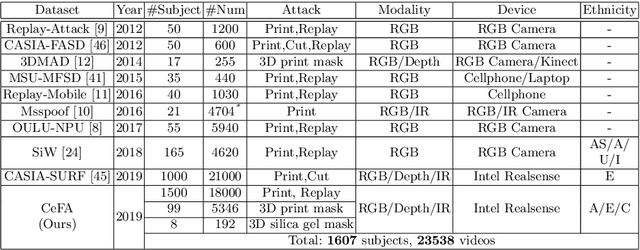
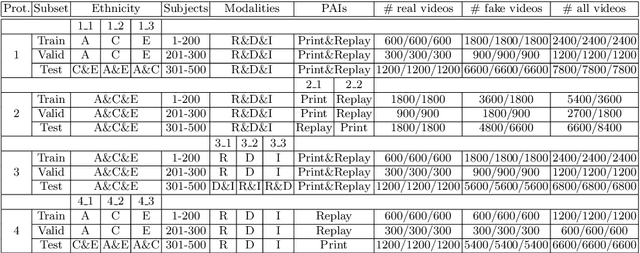
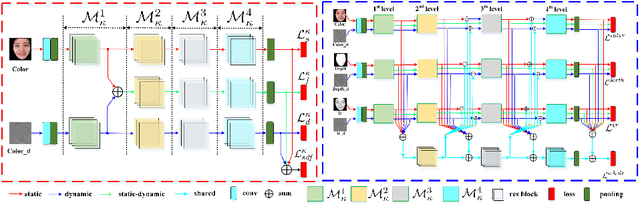
Ethnic bias has proven to negatively affect the performance of face recognition systems, and it remains an open research problem in face anti-spoofing. In order to study the ethnic bias for face anti-spoofing, we introduce the largest up to date CASIA-SURF Cross-ethnicity Face Anti-spoofing (CeFA) dataset (briefly named CeFA), covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, and 2D plus 3D attack types. Four protocols are introduced to measure the affect under varied evaluation conditions, such as cross-ethnicity, unknown spoofs or both of them. To the best of our knowledge, CeFA is the first dataset including explicit ethnic labels in current published/released datasets for face anti-spoofing. Then, we propose a novel multi-modal fusion method as a strong baseline to alleviate these bias, namely, the static-dynamic fusion mechanism applied in each modality (i.e., RGB, Depth and infrared image). Later, a partially shared fusion strategy is proposed to learn complementary information from multiple modalities. Extensive experiments demonstrate that the proposed method achieves state-of-the-art results on the CASIA-SURF, OULU-NPU, SiW and the CeFA dataset.
NAS-FAS: Static-Dynamic Central Difference Network Search for Face Anti-Spoofing
Nov 03, 2020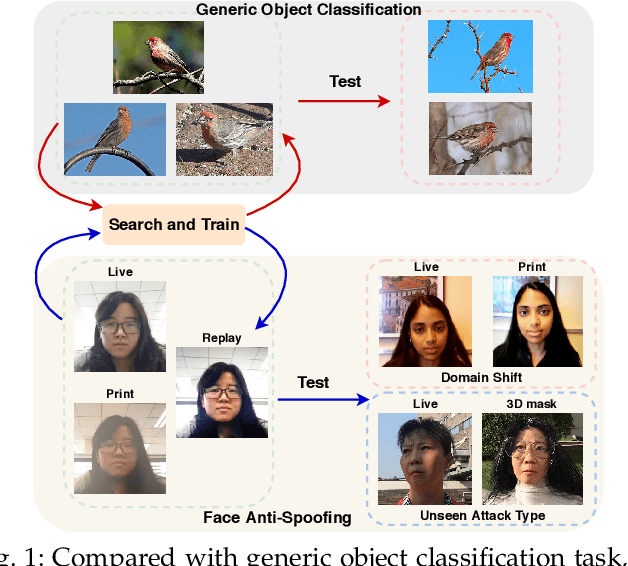
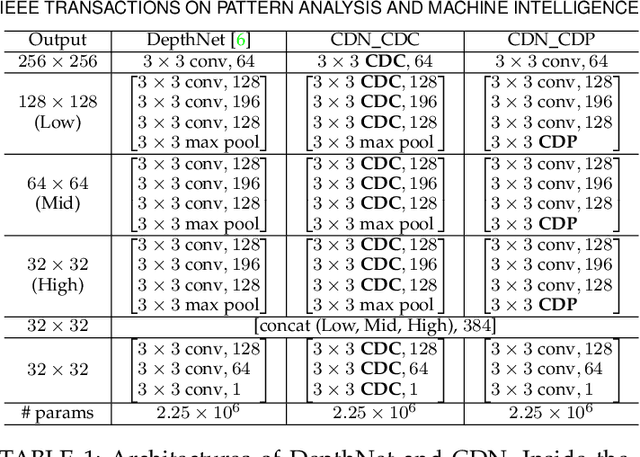
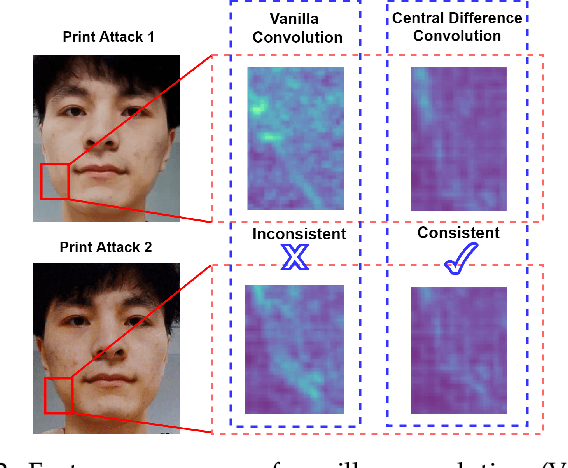
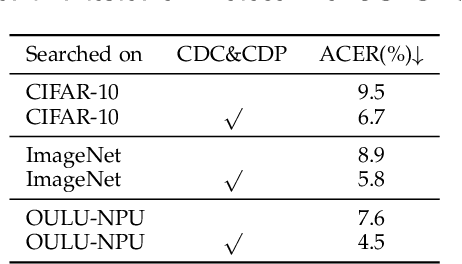
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems. Existing methods heavily rely on the expert-designed networks, which may lead to a sub-optimal solution for FAS task. Here we propose the first FAS method based on neural architecture search (NAS), called NAS-FAS, to discover the well-suited task-aware networks. Unlike previous NAS works mainly focus on developing efficient search strategies in generic object classification, we pay more attention to study the search spaces for FAS task. The challenges of utilizing NAS for FAS are in two folds: the networks searched on 1) a specific acquisition condition might perform poorly in unseen conditions, and 2) particular spoofing attacks might generalize badly for unseen attacks. To overcome these two issues, we develop a novel search space consisting of central difference convolution and pooling operators. Moreover, an efficient static-dynamic representation is exploited for fully mining the FAS-aware spatio-temporal discrepancy. Besides, we propose Domain/Type-aware Meta-NAS, which leverages cross-domain/type knowledge for robust searching. Finally, in order to evaluate the NAS transferability for cross datasets and unknown attack types, we release a large-scale 3D mask dataset, namely CASIA-SURF 3DMask, for supporting the new 'cross-dataset cross-type' testing protocol. Experiments demonstrate that the proposed NAS-FAS achieves state-of-the-art performance on nine FAS benchmark datasets with four testing protocols.
Creating Artificial Modalities to Solve RGB Liveness
Jun 29, 2020



Special cameras that provide useful features for face anti-spoofing are desirable, but not always an option. In this work we propose a method to utilize the difference in dynamic appearance between bona fide and spoof samples by creating artificial modalities from RGB videos. We introduce two types of artificial transforms: rank pooling and optical flow, combined in end-to-end pipeline for spoof detection. We demonstrate that using intermediate representations that contain less identity and fine-grained features increase model robustness to unseen attacks as well as to unseen ethnicities. The proposed method achieves state-of-the-art on the largest cross-ethnicity face anti-spoofing dataset CASIA-SURF CeFA (RGB).
PipeNet: Selective Modal Pipeline of Fusion Network for Multi-Modal Face Anti-Spoofing
Apr 24, 2020


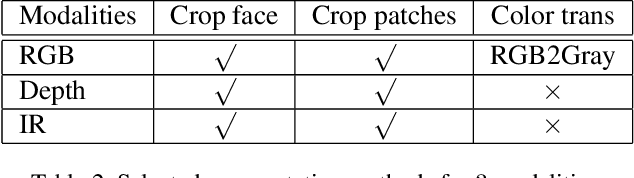
Face anti-spoofing has become an increasingly important and critical security feature for authentication systems, due to rampant and easily launchable presentation attacks. Addressing the shortage of multi-modal face dataset, CASIA recently released the largest up-to-date CASIA-SURF Cross-ethnicity Face Anti-spoofing(CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types in four protocols, and focusing on the challenge of improving the generalization capability of face anti-spoofing in cross-ethnicity and multi-modal continuous data. In this paper, we propose a novel pipeline-based multi-stream CNN architecture called PipeNet for multi-modal face anti-spoofing. Unlike previous works, Selective Modal Pipeline (SMP) is designed to enable a customized pipeline for each data modality to take full advantage of multi-modal data. Limited Frame Vote (LFV) is designed to ensure stable and accurate prediction for video classification. The proposed method wins the third place in the final ranking of Chalearn Multi-modal Cross-ethnicity Face Anti-spoofing Recognition Challenge@CVPR2020. Our final submission achieves the Average Classification Error Rate (ACER) of 2.21 with Standard Deviation of 1.26 on the test set.