 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Visual-Spatial Reasoning via R1-Zero-Like Training
Apr 01, 2025Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
3D High-Fidelity Mask Face Presentation Attack Detection Challenge
Aug 16, 2021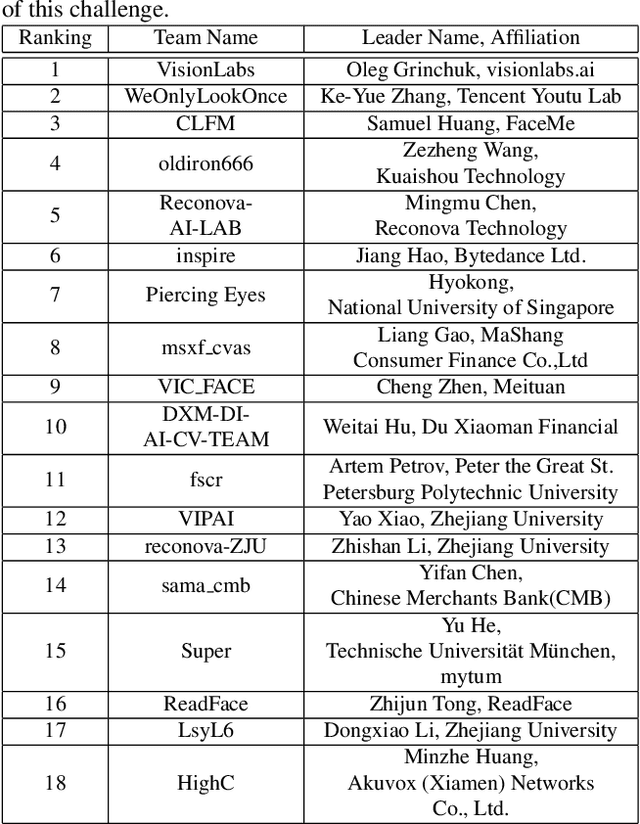
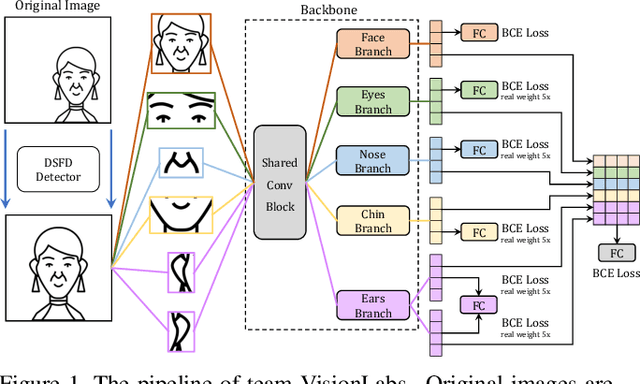
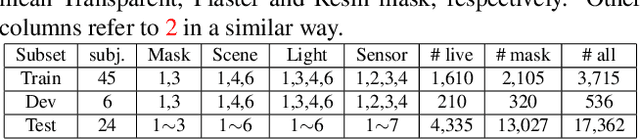
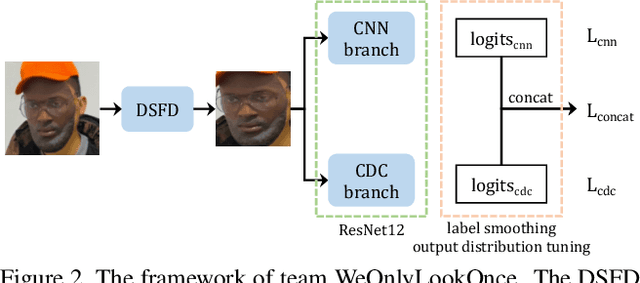
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers. To facilitate the study of the algorithms, a large-scale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask) has been collected. Specifically, it consists of a total amount of 54, 600 videos which are recorded from 75 subjects with 225 realistic masks under 7 new kinds of sensors. Based on this dataset and Protocol 3 which evaluates both the discrimination and generalization ability of the algorithm under the open set scenarios, we organized a 3D High-Fidelity Mask Face Presentation Attack Detection Challenge to boost the research of 3D mask-based attack detection. It attracted 195 teams for the development phase with a total of 18 teams qualifying for the final round. All the results were verified and re-run by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including the introduction of the dataset used, the definition of the protocol, the calculation of the evaluation criteria, and the summary and publication of the competition results. Finally, we focus on introducing and analyzing the top ranking algorithms, the conclusion summary, and the research ideas for mask attack detection provided by this competition.