 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCard Games
Papers and Code
OpenGuanDan: A Large-Scale Imperfect Information Game Benchmark
Jan 31, 2026The advancement of data-driven artificial intelligence (AI), particularly machine learning, heavily depends on large-scale benchmarks. Despite remarkable progress across domains ranging from pattern recognition to intelligent decision-making in recent decades, exemplified by breakthroughs in board games, card games, and electronic sports games, there remains a pressing need for more challenging benchmarks to drive further research. To this end, this paper proposes OpenGuanDan, a novel benchmark that enables both efficient simulation of GuanDan (a popular four-player, multi-round Chinese card game) and comprehensive evaluation of both learning-based and rule-based GuanDan AI agents. OpenGuanDan poses a suite of nontrivial challenges, including imperfect information, large-scale information set and action spaces, a mixed learning objective involving cooperation and competition, long-horizon decision-making, variable action spaces, and dynamic team composition. These characteristics make it a demanding testbed for existing intelligent decision-making methods. Moreover, the independent API for each player allows human-AI interactions and supports integration with large language models. Empirically, we conduct two types of evaluations: (1) pairwise competitions among all GuanDan AI agents, and (2) human-AI matchups. Experimental results demonstrate that while current learning-based agents substantially outperform rule-based counterparts, they still fall short of achieving superhuman performance, underscoring the need for continued research in multi-agent intelligent decision-making domain. The project is publicly available at https://github.com/GameAI-NJUPT/OpenGuanDan.
Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
Jan 26, 2026Cooperative reasoning under incomplete information remains challenging for both humans and multi-agent systems. The card game Hanabi embodies this challenge, requiring theory-of-mind reasoning and strategic communication. We benchmark 17 state-of-the-art LLM agents in 2-5 player games and study the impact of context engineering across model scales (4B to 600B+) to understand persistent coordination failures and robustness to scaffolding: from a minimal prompt with only explicit card details (Watson setting), to scaffolding with programmatic, Bayesian-motivated deductions (Sherlock setting), to multi-turn state tracking via working memory (Mycroft setting). We show that (1) agents can maintain an internal working memory for state tracking and (2) cross-play performance between different LLMs smoothly interpolates with model strength. In the Sherlock setting, the strongest reasoning models exceed 15 points on average across player counts, yet still trail experienced humans and specialist Hanabi agents, both consistently scoring above 20. We release the first public Hanabi datasets with annotated trajectories and move utilities: (1) HanabiLogs, containing 1,520 full game logs for instruction tuning, and (2) HanabiRewards, containing 560 games with dense move-level value annotations for all candidate moves. Supervised and RL finetuning of a 4B open-weight model (Qwen3-Instruct) on our datasets improves cooperative Hanabi play by 21% and 156% respectively, bringing performance to within ~3 points of a strong proprietary reasoning model (o4-mini) and surpassing the best non-reasoning model (GPT-4.1) by 52%. The HanabiRewards RL-finetuned model further generalizes beyond Hanabi, improving performance on a cooperative group-guessing benchmark by 11%, temporal reasoning on EventQA by 6.4%, instruction-following on IFBench-800K by 1.7 Pass@10, and matching AIME 2025 mathematical reasoning Pass@10.
Outer-Learning Framework for Playing Multi-Player Trick-Taking Card Games: A Case Study in Skat
Dec 17, 2025In multi-player card games such as Skat or Bridge, the early stages of the game, such as bidding, game selection, and initial card selection, are often more critical to the success of the play than refined middle- and end-game play. At the current limits of computation, such early decision-making resorts to using statistical information derived from a large corpus of human expert games. In this paper, we derive and evaluate a general bootstrapping outer-learning framework that improves prediction accuracy by expanding the database of human games with millions of self-playing AI games to generate and merge statistics. We implement perfect feature hash functions to address compacted tables, producing a self-improving card game engine, where newly inferred knowledge is continuously improved during self-learning. The case study in Skat shows that the automated approach can be used to support various decisions in the game.
Quantitative Rule-Based Strategy modeling in Classic Indian Rummy: A Metric Optimization Approach
Dec 26, 2025The 13-card variant of Classic Indian Rummy is a sequential game of incomplete information that requires probabilistic reasoning and combinatorial decision-making. This paper proposes a rule-based framework for strategic play, driven by a new hand-evaluation metric termed MinDist. The metric modifies the MinScore metric by quantifying the edit distance between a hand and the nearest valid configuration, thereby capturing structural proximity to completion. We design a computationally efficient algorithm derived from the MinScore algorithm, leveraging dynamic pruning and pattern caching to exactly calculate this metric during play. Opponent hand-modeling is also incorporated within a two-player zero-sum simulation framework, and the resulting strategies are evaluated using statistical hypothesis testing. Empirical results show significant improvement in win rates for MinDist-based agents over traditional heuristics, providing a formal and interpretable step toward algorithmic Rummy strategy design.
LLMQ: Efficient Lower-Precision Pretraining for Consumer GPUs
Dec 17, 2025We present LLMQ, an end-to-end CUDA/C++ implementation for medium-sized language-model training, e.g. 3B to 32B parameters, on affordable, commodity GPUs. These devices are characterized by low memory availability and slow communication compared to datacentre-grade GPUs. Consequently, we showcase a range of optimizations that target these bottlenecks, including activation checkpointing, offloading, and copy-engine based collectives. LLMQ is able to train or fine-tune a 7B model on a single 16GB mid-range gaming card, or a 32B model on a workstation equipped with 4 RTX 4090s. This is achieved while executing a standard 8-bit training pipeline, without additional algorithmic approximations, and maintaining FLOP utilization of around 50%. The efficiency of LLMQ rivals that of production-scale systems on much more expensive cloud-grade GPUs.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025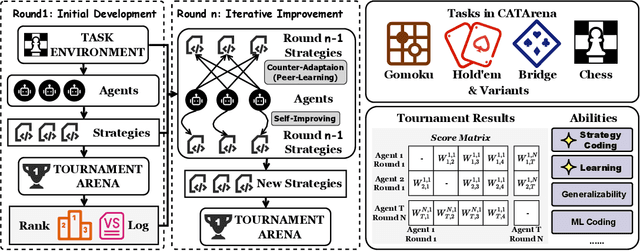
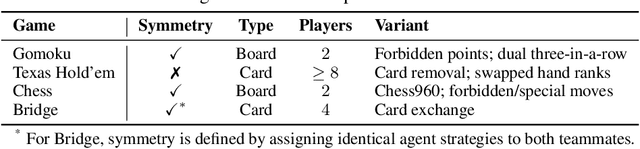
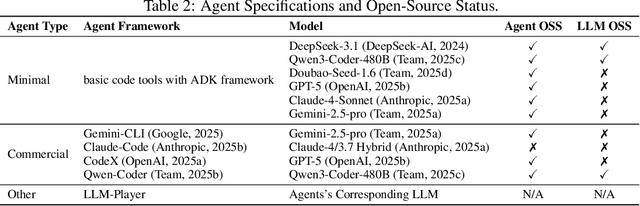
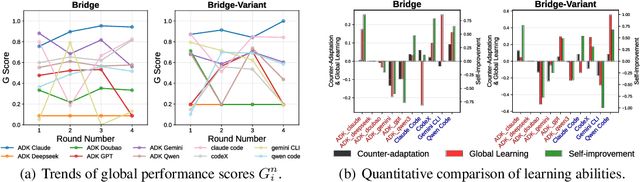
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
Pseudo-MDPs: A Novel Framework for Efficiently Optimizing Last Revealer Seed Manipulations in Blockchains
Oct 08, 2025This study tackles the computational challenges of solving Markov Decision Processes (MDPs) for a restricted class of problems. It is motivated by the Last Revealer Attack (LRA), which undermines fairness in some Proof-of-Stake (PoS) blockchains such as Ethereum (\$400B market capitalization). We introduce pseudo-MDPs (pMDPs) a framework that naturally models such problems and propose two distinct problem reductions to standard MDPs. One problem reduction provides a novel, counter-intuitive perspective, and combining the two problem reductions enables significant improvements in dynamic programming algorithms such as value iteration. In the case of the LRA which size is parameterized by $\kappa$ (in Ethereum's case $\kappa$= 325), we reduce the computational complexity from $O(2^\kappa \kappa^{2^{\kappa+2}})$ to $O(\kappa^4)$ (per iteration). This solution also provide the usual benefits from Dynamic Programming solutions: exponentially fast convergence toward the optimal solution is guaranteed. The dual perspective also simplifies policy extraction, making the approach well-suited for resource-constrained agents who can operate with very limited memory and computation once the problem has been solved. Furthermore, we generalize those results to a broader class of MDPs, enhancing their applicability. The framework is validated through two case studies: a fictional card game and the LRA on the Ethereum random seed consensus protocol. These applications demonstrate the framework's ability to solve large-scale problems effectively while offering actionable insights into optimal strategies. This work advances the study of MDPs and contributes to understanding security vulnerabilities in blockchain systems.
Code World Models for General Game Playing
Oct 06, 2025



Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
Rule Synergy Analysis using LLMs: State of the Art and Implications
Aug 27, 2025Large language models (LLMs) have demonstrated strong performance across a variety of domains, including logical reasoning, mathematics, and more. In this paper, we investigate how well LLMs understand and reason about complex rule interactions in dynamic environments, such as card games. We introduce a dataset of card synergies from the game Slay the Spire, where pairs of cards are classified based on their positive, negative, or neutral interactions. Our evaluation shows that while LLMs excel at identifying non-synergistic pairs, they struggle with detecting positive and, particularly, negative synergies. We categorize common error types, including issues with timing, defining game states, and following game rules. Our findings suggest directions for future research to improve model performance in predicting the effect of rules and their interactions.
UrzaGPT: LoRA-Tuned Large Language Models for Card Selection in Collectible Card Games
Aug 11, 2025Collectible card games (CCGs) are a difficult genre for AI due to their partial observability, long-term decision-making, and evolving card sets. Due to this, current AI models perform vastly worse than human players at CCG tasks such as deckbuilding and gameplay. In this work, we introduce UrzaGPT, a domain-adapted large language model that recommends real-time drafting decisions in Magic: The Gathering. Starting from an open-weight LLM, we use Low-Rank Adaptation fine-tuning on a dataset of annotated draft logs. With this, we leverage the language modeling capabilities of LLM, and can quickly adapt to different expansions of the game. We benchmark UrzaGPT in comparison to zero-shot LLMs and the state-of-the-art domain-specific model. Untuned, small LLMs like Llama-3-8B are completely unable to draft, but the larger GPT-4o achieves a zero-shot performance of 43%. Using UrzaGPT to fine-tune smaller models, we achieve an accuracy of 66.2% using only 10,000 steps. Despite this not reaching the capability of domain-specific models, we show that solely using LLMs to draft is possible and conclude that using LLMs can enable performant, general, and update-friendly drafting AIs in the future.