 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGuanDan: A Large-Scale Imperfect Information Game Benchmark
Jan 31, 2026The advancement of data-driven artificial intelligence (AI), particularly machine learning, heavily depends on large-scale benchmarks. Despite remarkable progress across domains ranging from pattern recognition to intelligent decision-making in recent decades, exemplified by breakthroughs in board games, card games, and electronic sports games, there remains a pressing need for more challenging benchmarks to drive further research. To this end, this paper proposes OpenGuanDan, a novel benchmark that enables both efficient simulation of GuanDan (a popular four-player, multi-round Chinese card game) and comprehensive evaluation of both learning-based and rule-based GuanDan AI agents. OpenGuanDan poses a suite of nontrivial challenges, including imperfect information, large-scale information set and action spaces, a mixed learning objective involving cooperation and competition, long-horizon decision-making, variable action spaces, and dynamic team composition. These characteristics make it a demanding testbed for existing intelligent decision-making methods. Moreover, the independent API for each player allows human-AI interactions and supports integration with large language models. Empirically, we conduct two types of evaluations: (1) pairwise competitions among all GuanDan AI agents, and (2) human-AI matchups. Experimental results demonstrate that while current learning-based agents substantially outperform rule-based counterparts, they still fall short of achieving superhuman performance, underscoring the need for continued research in multi-agent intelligent decision-making domain. The project is publicly available at https://github.com/GameAI-NJUPT/OpenGuanDan.
Bellman Error Centering
Feb 05, 2025



This paper revisits the recently proposed reward centering algorithms including simple reward centering (SRC) and value-based reward centering (VRC), and points out that SRC is indeed the reward centering, while VRC is essentially Bellman error centering (BEC). Based on BEC, we provide the centered fixpoint for tabular value functions, as well as the centered TD fixpoint for linear value function approximation. We design the on-policy CTD algorithm and the off-policy CTDC algorithm, and prove the convergence of both algorithms. Finally, we experimentally validate the stability of our proposed algorithms. Bellman error centering facilitates the extension to various reinforcement learning algorithms.
A Variance Minimization Approach to Temporal-Difference Learning
Nov 10, 2024Fast-converging algorithms are a contemporary requirement in reinforcement learning. In the context of linear function approximation, the magnitude of the smallest eigenvalue of the key matrix is a major factor reflecting the convergence speed. Traditional value-based RL algorithms focus on minimizing errors. This paper introduces a variance minimization (VM) approach for value-based RL instead of error minimization. Based on this approach, we proposed two objectives, the Variance of Bellman Error (VBE) and the Variance of Projected Bellman Error (VPBE), and derived the VMTD, VMTDC, and VMETD algorithms. We provided proofs of their convergence and optimal policy invariance of the variance minimization. Experimental studies validate the effectiveness of the proposed algorithms.
Model-based Offline Policy Optimization with Adversarial Network
Sep 05, 2023Model-based offline reinforcement learning (RL), which builds a supervised transition model with logging dataset to avoid costly interactions with the online environment, has been a promising approach for offline policy optimization. As the discrepancy between the logging data and online environment may result in a distributional shift problem, many prior works have studied how to build robust transition models conservatively and estimate the model uncertainty accurately. However, the over-conservatism can limit the exploration of the agent, and the uncertainty estimates may be unreliable. In this work, we propose a novel Model-based Offline policy optimization framework with Adversarial Network (MOAN). The key idea is to use adversarial learning to build a transition model with better generalization, where an adversary is introduced to distinguish between in-distribution and out-of-distribution samples. Moreover, the adversary can naturally provide a quantification of the model's uncertainty with theoretical guarantees. Extensive experiments showed that our approach outperforms existing state-of-the-art baselines on widely studied offline RL benchmarks. It can also generate diverse in-distribution samples, and quantify the uncertainty more accurately.
Online Attentive Kernel-Based Temporal Difference Learning
Jan 22, 2022



With rising uncertainty in the real world, online Reinforcement Learning (RL) has been receiving increasing attention due to its fast learning capability and improving data efficiency. However, online RL often suffers from complex Value Function Approximation (VFA) and catastrophic interference, creating difficulty for the deep neural network to be applied to an online RL algorithm in a fully online setting. Therefore, a simpler and more adaptive approach is introduced to evaluate value function with the kernel-based model. Sparse representations are superior at handling interference, indicating that competitive sparse representations should be learnable, non-prior, non-truncated and explicit when compared with current sparse representation methods. Moreover, in learning sparse representations, attention mechanisms are utilized to represent the degree of sparsification, and a smooth attentive function is introduced into the kernel-based VFA. In this paper, we propose an Online Attentive Kernel-Based Temporal Difference (OAKTD) algorithm using two-timescale optimization and provide convergence analysis of our proposed algorithm. Experimental evaluations showed that OAKTD outperformed several Online Kernel-based Temporal Difference (OKTD) learning algorithms in addition to the Temporal Difference (TD) learning algorithm with Tile Coding on public Mountain Car, Acrobot, CartPole and Puddle World tasks.
Multi-Agent Game Abstraction via Graph Attention Neural Network
Nov 25, 2019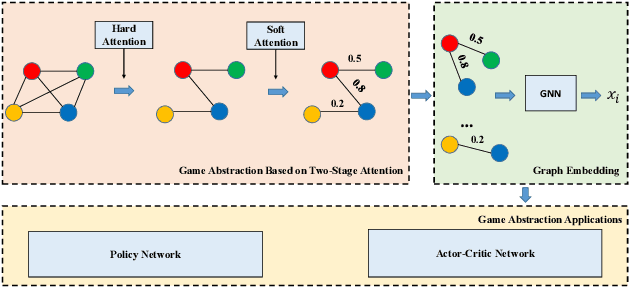

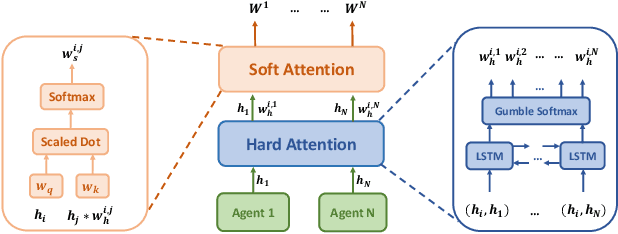
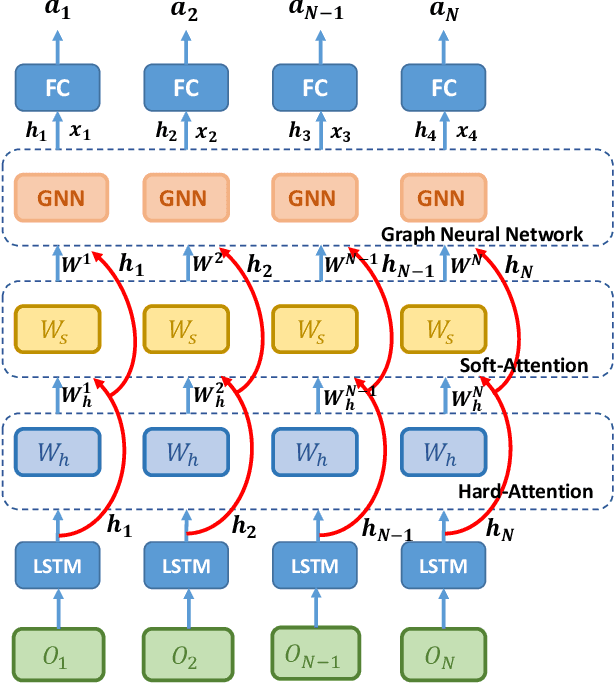
In large-scale multi-agent systems, the large number of agents and complex game relationship cause great difficulty for policy learning. Therefore, simplifying the learning process is an important research issue. In many multi-agent systems, the interactions between agents often happen locally, which means that agents neither need to coordinate with all other agents nor need to coordinate with others all the time. Traditional methods attempt to use pre-defined rules to capture the interaction relationship between agents. However, the methods cannot be directly used in a large-scale environment due to the difficulty of transforming the complex interactions between agents into rules. In this paper, we model the relationship between agents by a complete graph and propose a novel game abstraction mechanism based on two-stage attention network (G2ANet), which can indicate whether there is an interaction between two agents and the importance of the interaction. We integrate this detection mechanism into graph neural network-based multi-agent reinforcement learning for conducting game abstraction and propose two novel learning algorithms GA-Comm and GA-AC. We conduct experiments in Traffic Junction and Predator-Prey. The results indicate that the proposed methods can simplify the learning process and meanwhile get better asymptotic performance compared with state-of-the-art algorithms.