 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Evolving Reason-Reflect-Rectify for Reflective Visual Generation
May 19, 2026Text-to-Image (T2I) models and Unified Multimodal Models (UMMs) have achieved remarkable progress in visual generation. However, their reliance on a single-pass generation paradigm limits their ability to handle complex prompts requiring iterative refinement. To enable multi-round Reflective Visual Generation (RVG), we formalize the Reason-Reflect-Rectify (R^3) loop as a core framework and introduce R^3-Bench, a benchmark of over 600 expert-annotated instances that quantifies iterative reasoning and rectification capabilities. Evaluation on R^3-Bench reveals a critical gap: while state-of-the-art models can identify generation errors, they fail to generate actionable rectification instructions. To bridge this gap, we propose R^3-Refiner, a dual-stage framework leveraging Group Relative Policy Optimization (GRPO) and a Hierarchical Reward Mechanism (HRM) to better align rectification with reflective reasoning. Experiments show that R^3-Refiner achieves significant improvements on R^3-Bench (+12.0% in Reflective Verdict Score, +9.0% in Rectification Score), and can be seamlessly integrated with various MLLMs to enhance the generation quality of different T2I models on GenEval++ and T2I-CompBench. Code is available at https://github.com/xiaomoguhz/R3-Bench.
Code World Models for General Game Playing
Oct 06, 2025



Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
Improving Transformer World Models for Data-Efficient RL
Feb 03, 2025



We present an approach to model-based RL that achieves a new state of the art performance on the challenging Craftax-classic benchmark, an open-world 2D survival game that requires agents to exhibit a wide range of general abilities -- such as strong generalization, deep exploration, and long-term reasoning. With a series of careful design choices aimed at improving sample efficiency, our MBRL algorithm achieves a reward of 67.4% after only 1M environment steps, significantly outperforming DreamerV3, which achieves 53.2%, and, for the first time, exceeds human performance of 65.0%. Our method starts by constructing a SOTA model-free baseline, using a novel policy architecture that combines CNNs and RNNs. We then add three improvements to the standard MBRL setup: (a) "Dyna with warmup", which trains the policy on real and imaginary data, (b) "nearest neighbor tokenizer" on image patches, which improves the scheme to create the transformer world model (TWM) inputs, and (c) "block teacher forcing", which allows the TWM to reason jointly about the future tokens of the next timestep.
Model Predictive Simulation Using Structured Graphical Models and Transformers
Jun 28, 2024We propose an approach to simulating trajectories of multiple interacting agents (road users) based on transformers and probabilistic graphical models (PGMs), and apply it to the Waymo SimAgents challenge. The transformer baseline is based on the MTR model, which predicts multiple future trajectories conditioned on the past trajectories and static road layout features. We then improve upon these generated trajectories using a PGM, which contains factors which encode prior knowledge, such as a preference for smooth trajectories, and avoidance of collisions with static obstacles and other moving agents. We perform (approximate) MAP inference in this PGM using the Gauss-Newton method. Finally we sample $K=32$ trajectories for each of the $N \sim 100$ agents for the next $T=8 \Delta$ time steps, where $\Delta=10$ is the sampling rate per second. Following the Model Predictive Control (MPC) paradigm, we only return the first element of our forecasted trajectories at each step, and then we replan, so that the simulation can constantly adapt to its changing environment. We therefore call our approach "Model Predictive Simulation" or MPS. We show that MPS improves upon the MTR baseline, especially in safety critical metrics such as collision rate. Furthermore, our approach is compatible with any underlying forecasting model, and does not require extra training, so we believe it is a valuable contribution to the community.
PushWorld: A benchmark for manipulation planning with tools and movable obstacles
Feb 01, 2023



While recent advances in artificial intelligence have achieved human-level performance in environments like Starcraft and Go, many physical reasoning tasks remain challenging for modern algorithms. To date, few algorithms have been evaluated on physical tasks that involve manipulating objects when movable obstacles are present and when tools must be used to perform the manipulation. To promote research on such tasks, we introduce PushWorld, an environment with simplistic physics that requires manipulation planning with both movable obstacles and tools. We provide a benchmark of more than 200 PushWorld puzzles in PDDL and in an OpenAI Gym environment. We evaluate state-of-the-art classical planning and reinforcement learning algorithms on this benchmark, and we find that these baseline results are below human-level performance. We then provide a new classical planning heuristic that solves the most puzzles among the baselines, and although it is 40 times faster than the best baseline planner, it remains below human-level performance.
Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics
Aug 17, 2017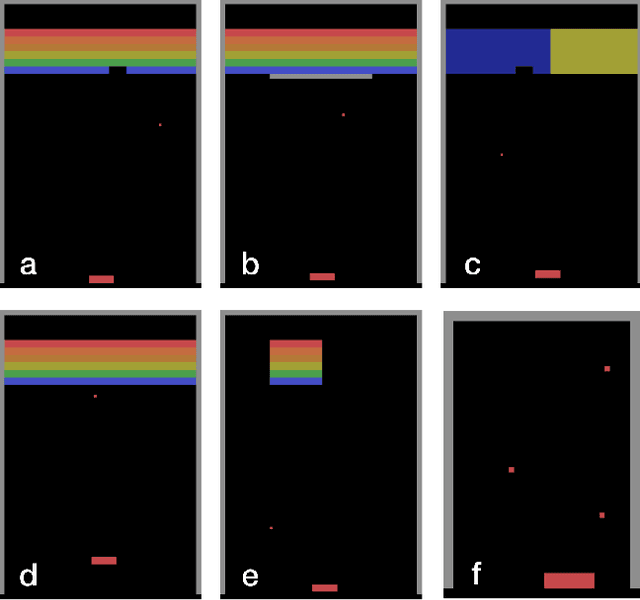

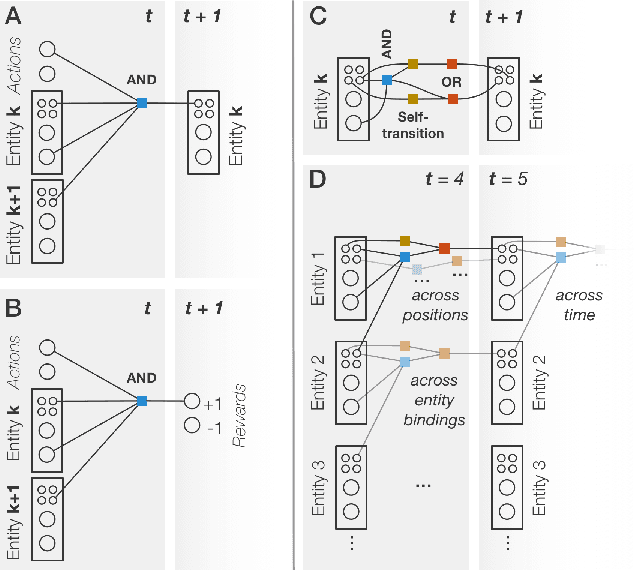
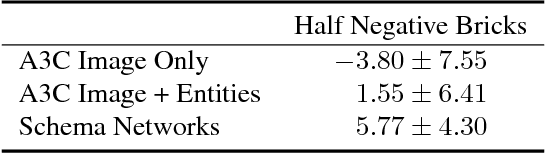
The recent adaptation of deep neural network-based methods to reinforcement learning and planning domains has yielded remarkable progress on individual tasks. Nonetheless, progress on task-to-task transfer remains limited. In pursuit of efficient and robust generalization, we introduce the Schema Network, an object-oriented generative physics simulator capable of disentangling multiple causes of events and reasoning backward through causes to achieve goals. The richly structured architecture of the Schema Network can learn the dynamics of an environment directly from data. We compare Schema Networks with Asynchronous Advantage Actor-Critic and Progressive Networks on a suite of Breakout variations, reporting results on training efficiency and zero-shot generalization, consistently demonstrating faster, more robust learning and better transfer. We argue that generalizing from limited data and learning causal relationships are essential abilities on the path toward generally intelligent systems.
Generative Shape Models: Joint Text Recognition and Segmentation with Very Little Training Data
Nov 09, 2016
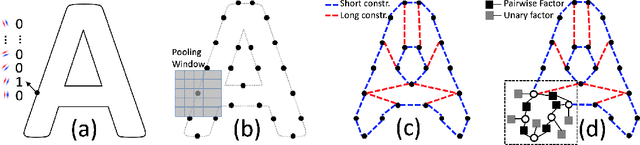
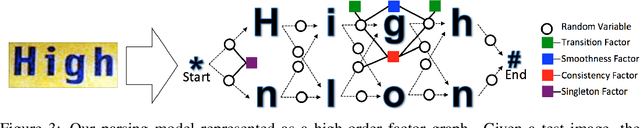

We demonstrate that a generative model for object shapes can achieve state of the art results on challenging scene text recognition tasks, and with orders of magnitude fewer training images than required for competing discriminative methods. In addition to transcribing text from challenging images, our method performs fine-grained instance segmentation of characters. We show that our model is more robust to both affine transformations and non-affine deformations compared to previous approaches.
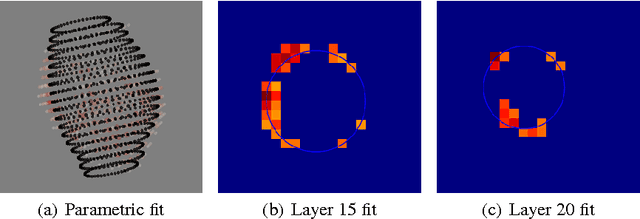
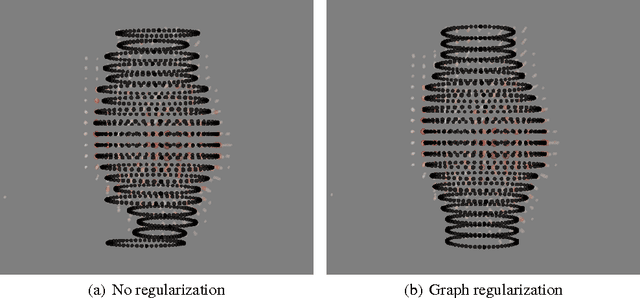
GRED: Graph-Regularized 3D Shape Reconstruction from Highly Anisotropic and Noisy Images
Sep 17, 2013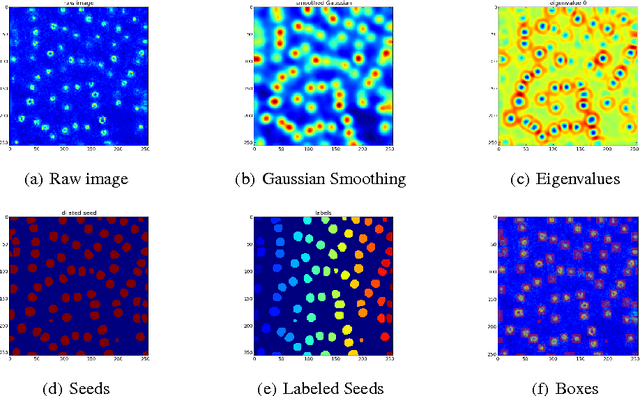

Analysis of microscopy images can provide insight into many biological processes. One particularly challenging problem is cell nuclear segmentation in highly anisotropic and noisy 3D image data. Manually localizing and segmenting each and every cell nuclei is very time consuming, which remains a bottleneck in large scale biological experiments. In this work we present a tool for automated segmentation of cell nuclei from 3D fluorescent microscopic data. Our tool is based on state-of-the-art image processing and machine learning techniques and supports a friendly graphical user interface (GUI). We show that our tool is as accurate as manual annotation but greatly reduces the time for the registration.
Structured Learning from Partial Annotations
Jun 27, 2012
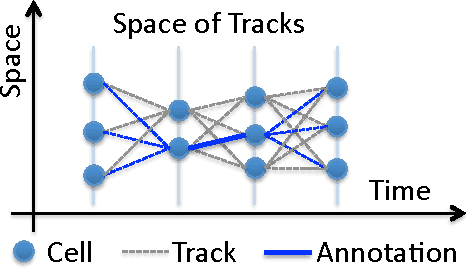

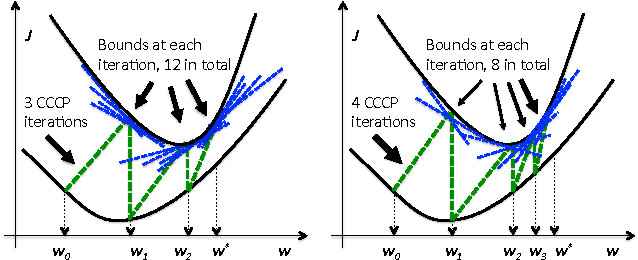
Structured learning is appropriate when predicting structured outputs such as trees, graphs, or sequences. Most prior work requires the training set to consist of complete trees, graphs or sequences. Specifying such detailed ground truth can be tedious or infeasible for large outputs. Our main contribution is a large margin formulation that makes structured learning from only partially annotated data possible. The resulting optimization problem is non-convex, yet can be efficiently solve by concave-convex procedure (CCCP) with novel speedup strategies. We apply our method to a challenging tracking-by-assignment problem of a variable number of divisible objects. On this benchmark, using only 25% of a full annotation we achieve a performance comparable to a model learned with a full annotation. Finally, we offer a unifying perspective of previous work using the hinge, ramp, or max loss for structured learning, followed by an empirical comparison on their practical performance.