 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoscaling
Papers and Code
SAIR: Cost-Efficient Multi-Stage ML Pipeline Autoscaling via In-Context Reinforcement Learning
Jan 29, 2026Multi-stage ML inference pipelines are difficult to autoscale due to heterogeneous resources, cross-stage coupling, and dynamic bottleneck migration. We present SAIR, an autoscaling framework that uses an LLM as an in-context reinforcement learning controller, improving its policy online from reward-labeled interaction histories without gradient updates. SAIR combines Pareto-dominance reward shaping with a provable separation margin, surprisal-guided experience retrieval for context efficiency, and fine-grained GPU rate control via user-space CUDA interception. We provide regret analysis decomposing error into retrieval coverage and LLM selection components. On four ML serving pipelines under three workload patterns, SAIR achieves the best or tied-best P99 latency and effective resource cost among deployed baselines, improving P99 by up to 50% and reducing effective cost by up to 97% (under GPU rate-control assumptions), with 86% bottleneck detection accuracy and no offline training.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025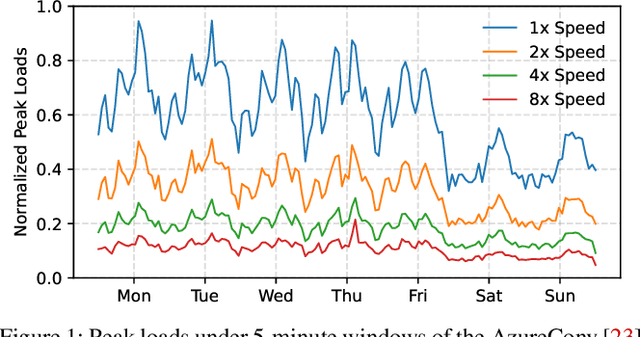
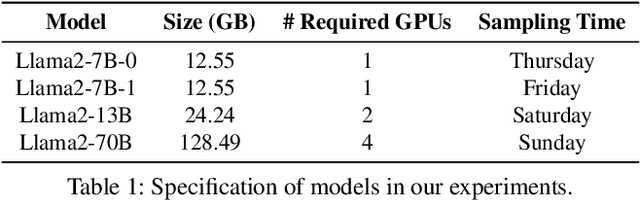
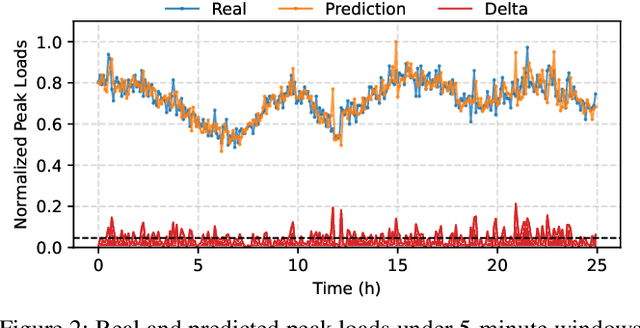
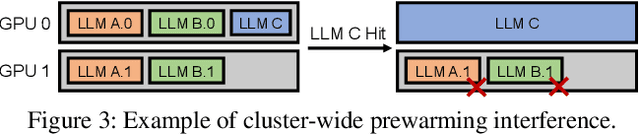
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
Multi-Dimensional Autoscaling of Stream Processing Services on Edge Devices
Oct 08, 2025



Edge devices have limited resources, which inevitably leads to situations where stream processing services cannot satisfy their needs. While existing autoscaling mechanisms focus entirely on resource scaling, Edge devices require alternative ways to sustain the Service Level Objectives (SLOs) of competing services. To address these issues, we introduce a Multi-dimensional Autoscaling Platform (MUDAP) that supports fine-grained vertical scaling across both service- and resource-level dimensions. MUDAP supports service-specific scaling tailored to available parameters, e.g., scale data quality or model size for a particular service. To optimize the execution across services, we present a scaling agent based on Regression Analysis of Structural Knowledge (RASK). The RASK agent efficiently explores the solution space and learns a continuous regression model of the processing environment for inferring optimal scaling actions. We compared our approach with two autoscalers, the Kubernetes VPA and a reinforcement learning agent, for scaling up to 9 services on a single Edge device. Our results showed that RASK can infer an accurate regression model in merely 20 iterations (i.e., observe 200s of processing). By increasingly adding elasticity dimensions, RASK sustained the highest request load with 28% less SLO violations, compared to baselines.
Insights from Gradient Dynamics: Gradient Autoscaled Normalization
Sep 03, 2025Gradient dynamics play a central role in determining the stability and generalization of deep neural networks. In this work, we provide an empirical analysis of how variance and standard deviation of gradients evolve during training, showing consistent changes across layers and at the global scale in convolutional networks. Motivated by these observations, we propose a hyperparameter-free gradient normalization method that aligns gradient scaling with their natural evolution. This approach prevents unintended amplification, stabilizes optimization, and preserves convergence guarantees. Experiments on the challenging CIFAR-100 benchmark with ResNet-20, ResNet-56, and VGG-16-BN demonstrate that our method maintains or improves test accuracy even under strong generalization. Beyond practical performance, our study highlights the importance of directly tracking gradient dynamics, aiming to bridge the gap between theoretical expectations and empirical behaviors, and to provide insights for future optimization research.
Taming the Chaos: Coordinated Autoscaling for Heterogeneous and Disaggregated LLM Inference
Aug 27, 2025



Serving Large Language Models (LLMs) is a GPU-intensive task where traditional autoscalers fall short, particularly for modern Prefill-Decode (P/D) disaggregated architectures. This architectural shift, while powerful, introduces significant operational challenges, including inefficient use of heterogeneous hardware, network bottlenecks, and critical imbalances between prefill and decode stages. We introduce HeteroScale, a coordinated autoscaling framework that addresses the core challenges of P/D disaggregated serving. HeteroScale combines a topology-aware scheduler that adapts to heterogeneous hardware and network constraints with a novel metric-driven policy derived from the first large-scale empirical study of autoscaling signals in production. By leveraging a single, robust metric to jointly scale prefill and decode pools, HeteroScale maintains architectural balance while ensuring efficient, adaptive resource management. Deployed in a massive production environment on tens of thousands of GPUs, HeteroScale has proven its effectiveness, increasing average GPU utilization by a significant 26.6 percentage points and saving hundreds of thousands of GPU-hours daily, all while upholding stringent service level objectives.
Multi-dimensional Autoscaling of Processing Services: A Comparison of Agent-based Methods
Jun 12, 2025Edge computing breaks with traditional autoscaling due to strict resource constraints, thus, motivating more flexible scaling behaviors using multiple elasticity dimensions. This work introduces an agent-based autoscaling framework that dynamically adjusts both hardware resources and internal service configurations to maximize requirements fulfillment in constrained environments. We compare four types of scaling agents: Active Inference, Deep Q Network, Analysis of Structural Knowledge, and Deep Active Inference, using two real-world processing services running in parallel: YOLOv8 for visual recognition and OpenCV for QR code detection. Results show all agents achieve acceptable SLO performance with varying convergence patterns. While the Deep Q Network benefits from pre-training, the structural analysis converges quickly, and the deep active inference agent combines theoretical foundations with practical scalability advantages. Our findings provide evidence for the viability of multi-dimensional agent-based autoscaling for edge environments and encourage future work in this research direction.
Streamlining Resilient Kubernetes Autoscaling with Multi-Agent Systems via an Automated Online Design Framework
May 26, 2025In cloud-native systems, Kubernetes clusters with interdependent services often face challenges to their operational resilience due to poor workload management issues such as resource blocking, bottlenecks, or continuous pod crashes. These vulnerabilities are further amplified in adversarial scenarios, such as Distributed Denial-of-Service attacks (DDoS). Conventional Horizontal Pod Autoscaling (HPA) approaches struggle to address such dynamic conditions, while reinforcement learning-based methods, though more adaptable, typically optimize single goals like latency or resource usage, neglecting broader failure scenarios. We propose decomposing the overarching goal of maintaining operational resilience into failure-specific sub-goals delegated to collaborative agents, collectively forming an HPA Multi-Agent System (MAS). We introduce an automated, four-phase online framework for HPA MAS design: 1) modeling a digital twin built from cluster traces; 2) training agents in simulation using roles and missions tailored to failure contexts; 3) analyzing agent behaviors for explainability; and 4) transferring learned policies to the real cluster. Experimental results demonstrate that the generated HPA MASs outperform three state-of-the-art HPA systems in sustaining operational resilience under various adversarial conditions in a proposed complex cluster.
Learning in Chaos: Efficient Autoscaling and Self-healing for Distributed Training at the Edge
May 19, 2025Frequent node and link changes in edge AI clusters disrupt distributed training, while traditional checkpoint-based recovery and cloud-centric autoscaling are too slow for scale-out and ill-suited to chaotic and self-governed edge. This paper proposes Chaos, a resilient and scalable edge distributed training system with built-in self-healing and autoscaling. It speeds up scale-out by using multi-neighbor replication with fast shard scheduling, allowing a new node to pull the latest training state from nearby neighbors in parallel while balancing the traffic load between them. It also uses a cluster monitor to track resource and topology changes to assist scheduler decisions, and handles scaling events through peer negotiation protocols, enabling fully self-governed autoscaling without a central admin. Extensive experiments show that Chaos consistently achieves much lower scale-out delays than Pollux, EDL, and Autoscaling, and handles scale-in, connect-link, and disconnect-link events within 1 millisecond, making it smoother to handle node joins, exits, and failures. It also delivers the lowest idle time, showing superior resource use and scalability as the cluster grows.
Scalability Optimization in Cloud-Based AI Inference Services: Strategies for Real-Time Load Balancing and Automated Scaling
Apr 16, 2025The rapid expansion of AI inference services in the cloud necessitates a robust scalability solution to manage dynamic workloads and maintain high performance. This study proposes a comprehensive scalability optimization framework for cloud AI inference services, focusing on real-time load balancing and autoscaling strategies. The proposed model is a hybrid approach that combines reinforcement learning for adaptive load distribution and deep neural networks for accurate demand forecasting. This multi-layered approach enables the system to anticipate workload fluctuations and proactively adjust resources, ensuring maximum resource utilisation and minimising latency. Furthermore, the incorporation of a decentralised decision-making process within the model serves to enhance fault tolerance and reduce response time in scaling operations. Experimental results demonstrate that the proposed model enhances load balancing efficiency by 35\ and reduces response delay by 28\, thereby exhibiting a substantial optimization effect in comparison with conventional scalability solutions.
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.