 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Clustering
Sep 21, 2020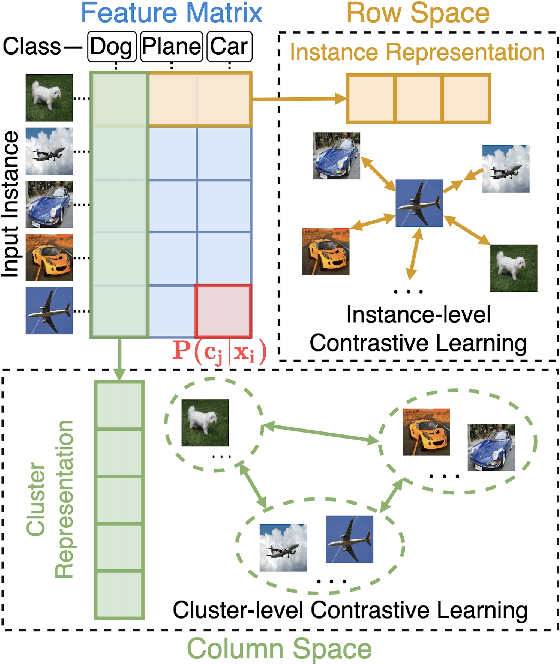
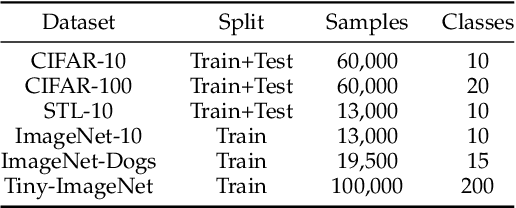
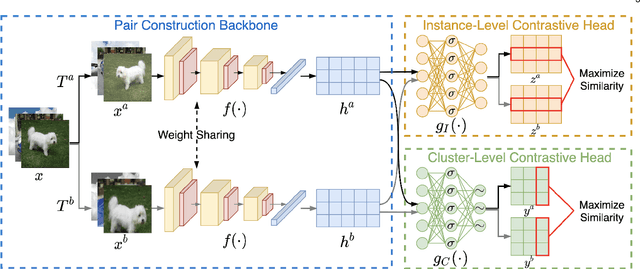
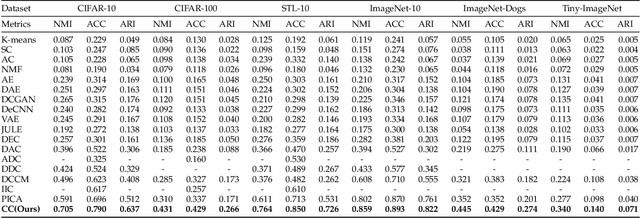
In this paper, we propose a one-stage online clustering method called Contrastive Clustering (CC) which explicitly performs the instance- and cluster-level contrastive learning. To be specific, for a given dataset, the positive and negative instance pairs are constructed through data augmentations and then projected into a feature space. Therein, the instance- and cluster-level contrastive learning are respectively conducted in the row and column space by maximizing the similarities of positive pairs while minimizing those of negative ones. Our key observation is that the rows of the feature matrix could be regarded as soft labels of instances, and accordingly the columns could be further regarded as cluster representations. By simultaneously optimizing the instance- and cluster-level contrastive loss, the model jointly learns representations and cluster assignments in an end-to-end manner. Extensive experimental results show that CC remarkably outperforms 17 competitive clustering methods on six challenging image benchmarks. In particular, CC achieves an NMI of 0.705 (0.431) on the CIFAR-10 (CIFAR-100) dataset, which is an up to 19\% (39\%) performance improvement compared with the best baseline.
Self-supervised Learning on Graphs: Deep Insights and New Direction
Jun 17, 2020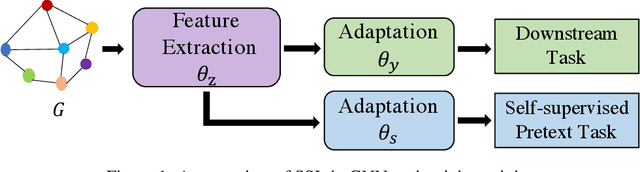

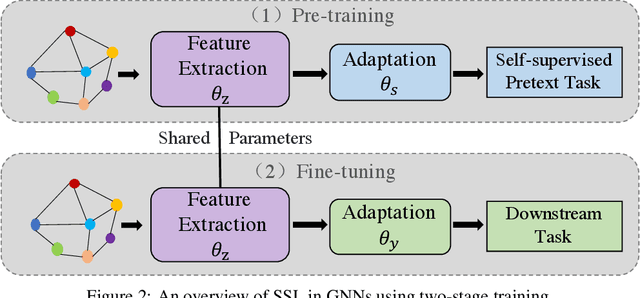
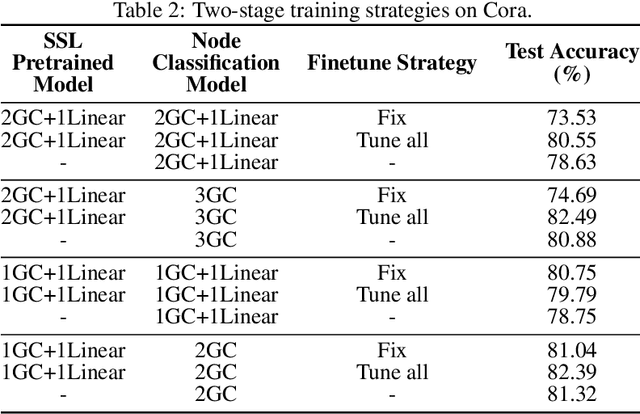
The success of deep learning notoriously requires larger amounts of costly annotated data. This has led to the development of self-supervised learning (SSL) that aims to alleviate this limitation by creating domain specific pretext tasks on unlabeled data. Simultaneously, there are increasing interests in generalizing deep learning to the graph domain in the form of graph neural networks (GNNs). GNNs can naturally utilize unlabeled nodes through the simple neighborhood aggregation that is unable to thoroughly make use of unlabeled nodes. Thus, we seek to harness SSL for GNNs to fully exploit the unlabeled data. Different from data instances in the image and text domains, nodes in graphs present unique structure information and they are inherently linked indicating not independent and identically distributed (or i.i.d.). Such complexity is a double-edged sword for SSL on graphs. On the one hand, it determines that it is challenging to adopt solutions from the image and text domains to graphs and dedicated efforts are desired. On the other hand, it provides rich information that enables us to build SSL from a variety of perspectives. Thus, in this paper, we first deepen our understandings on when, why, and which strategies of SSL work with GNNs by empirically studying numerous basic SSL pretext tasks on graphs. Inspired by deep insights from the empirical studies, we propose a new direction SelfTask to build advanced pretext tasks that are able to achieve state-of-the-art performance on various real-world datasets. The specific experimental settings to reproduce our results can be found in \url{https://github.com/ChandlerBang/SelfTask-GNN}.
Neural Multi-Task Learning for Teacher Question Detection in Online Classrooms
May 16, 2020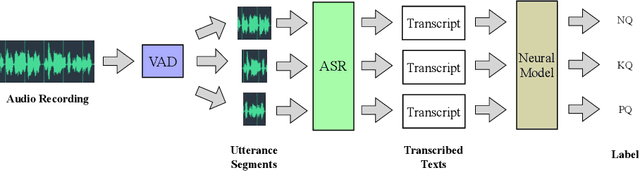

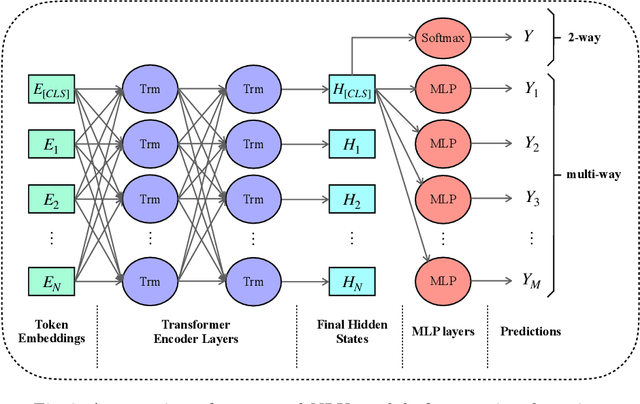
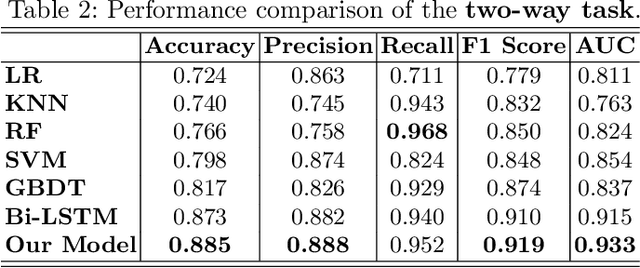
Asking questions is one of the most crucial pedagogical techniques used by teachers in class. It not only offers open-ended discussions between teachers and students to exchange ideas but also provokes deeper student thought and critical analysis. Providing teachers with such pedagogical feedback will remarkably help teachers improve their overall teaching quality over time in classrooms. Therefore, in this work, we build an end-to-end neural framework that automatically detects questions from teachers' audio recordings. Compared with traditional methods, our approach not only avoids cumbersome feature engineering, but also adapts to the task of multi-class question detection in real education scenarios. By incorporating multi-task learning techniques, we are able to strengthen the understanding of semantic relations among different types of questions. We conducted extensive experiments on the question detection tasks in a real-world online classroom dataset and the results demonstrate the superiority of our model in terms of various evaluation metrics.
Automatic Dialogic Instruction Detection for K-12 Online One-on-one Classes
May 16, 2020
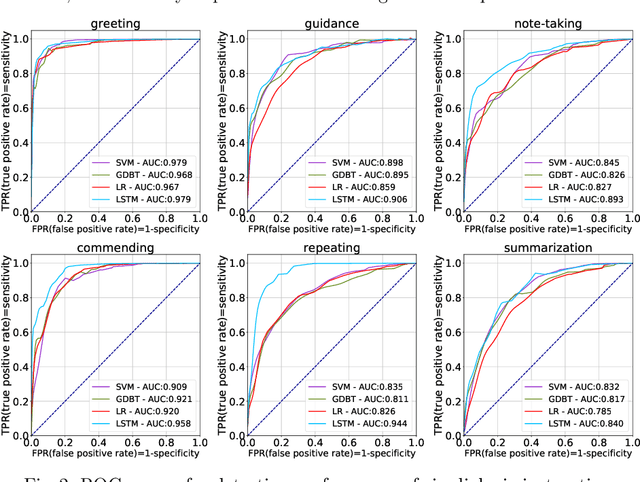
Online one-on-one class is created for highly interactive and immersive learning experience. It demands a large number of qualified online instructors. In this work, we develop six dialogic instructions and help teachers achieve the benefits of one-on-one learning paradigm. Moreover, we utilize neural language models, i.e., long short-term memory (LSTM), to detect above six instructions automatically. Experiments demonstrate that the LSTM approach achieves AUC scores from 0.840 to 0.979 among all six types of instructions on our real-world educational dataset.
Siamese Neural Networks for Class Activity Detection
May 15, 2020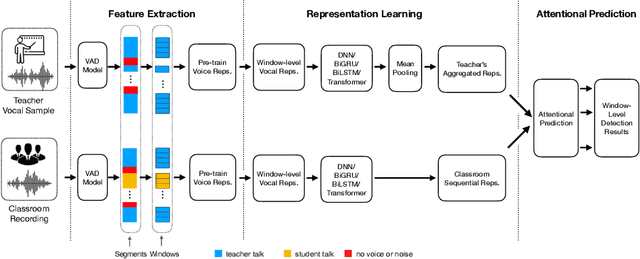
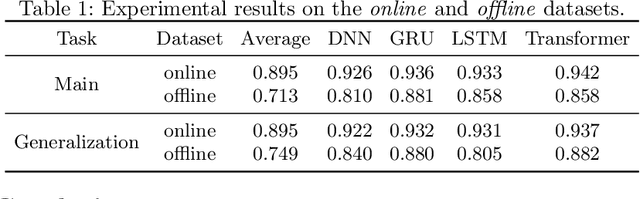
Classroom activity detection (CAD) aims at accurately recognizing speaker roles (either teacher or student) in classrooms. A CAD solution helps teachers get instant feedback on their pedagogical instructions. However, CAD is very challenging because (1) classroom conversations contain many conversational turn-taking overlaps between teachers and students; (2) the CAD model needs to be generalized well enough for different teachers and students; and (3) classroom recordings may be very noisy and low-quality. In this work, we address the above challenges by building a Siamese neural framework to automatically identify teacher and student utterances from classroom recordings. The proposed model is evaluated on real-world educational datasets. The results demonstrate that (1) our approach is superior on the prediction tasks for both online and offline classroom environments; and (2) our framework exhibits robustness and generalization ability on new teachers (i.e., teachers never appear in training data).
Synchronous Bidirectional Learning for Multilingual Lip Reading
May 12, 2020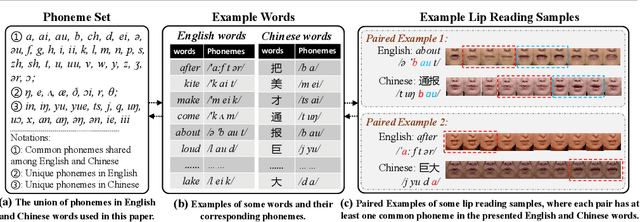
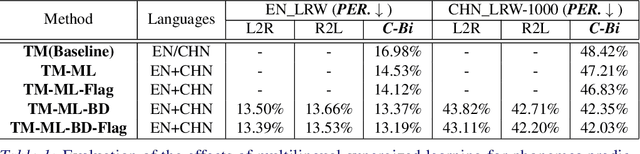
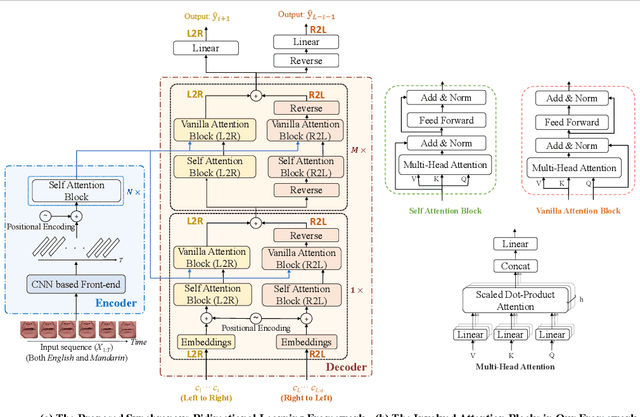
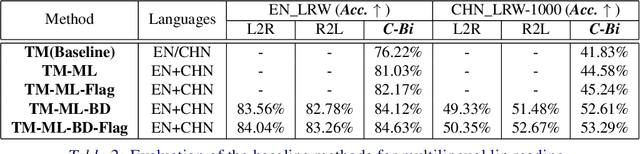
Lip reading has received increasing attention in recent years. This paper focuses on the synergy of multilingual lip reading. There are more than 7,000 languages in the world, which implies that it is impractical to train separate lip reading models by collecting large-scale data per language. Although each language has its own linguistic and pronunciation features, the lip movements of all languages share similar patterns. Based on this idea, in this paper, we try to explore the synergized learning of multilingual lip reading, and further propose a synchronous bidirectional learning(SBL) framework for effective synergy of multilingual lip reading. Firstly, we introduce the phonemes as our modeling units for the multilingual setting. Similar phoneme always leads to similar visual patterns. The multilingual setting would increase both the quantity and the diversity of each phoneme shared among different languages. So the learning for the multilingual target should bring improvement to the prediction of phonemes. Then, a SBL block is proposed to infer the target unit when given its previous and later context. The rules for each specific language which the model itself judges to be is learned in this fill-in-the-blank manner. To make the learning process more targeted at each particular language, we introduce an extra task of predicting the language identity in the learning process. Finally, we perform a thorough comparison on LRW (English) and LRW-1000(Mandarin). The results outperform the existing state of the art by a large margin, and show the promising benefits from the synergized learning of different languages.
Learning Goal-oriented Dialogue Policy with Opposite Agent Awareness
Apr 21, 2020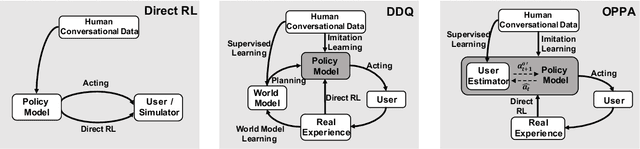
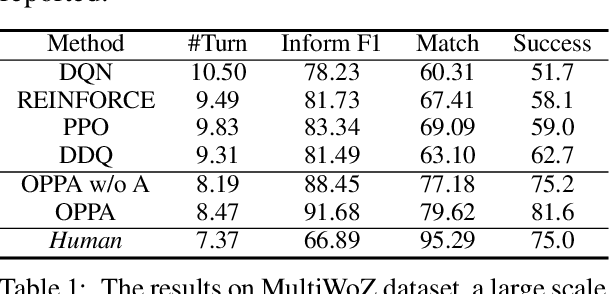
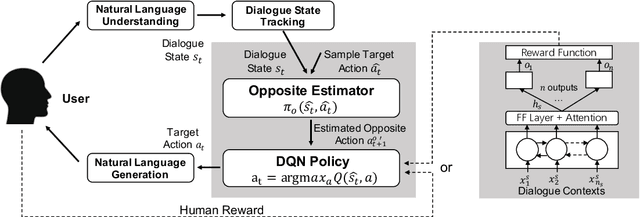
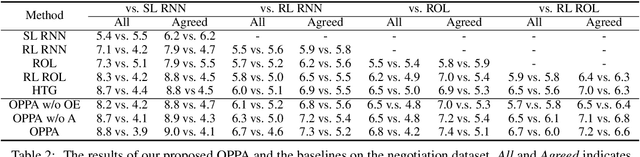
Most existing approaches for goal-oriented dialogue policy learning used reinforcement learning, which focuses on the target agent policy and simply treat the opposite agent policy as part of the environment. While in real-world scenarios, the behavior of an opposite agent often exhibits certain patterns or underlies hidden policies, which can be inferred and utilized by the target agent to facilitate its own decision making. This strategy is common in human mental simulation by first imaging a specific action and the probable results before really acting it. We therefore propose an opposite behavior aware framework for policy learning in goal-oriented dialogues. We estimate the opposite agent's policy from its behavior and use this estimation to improve the target agent by regarding it as part of the target policy. We evaluate our model on both cooperative and competitive dialogue tasks, showing superior performance over state-of-the-art baselines.
Identifying At-Risk K-12 Students in Multimodal Online Environments: A Machine Learning Approach
Mar 21, 2020
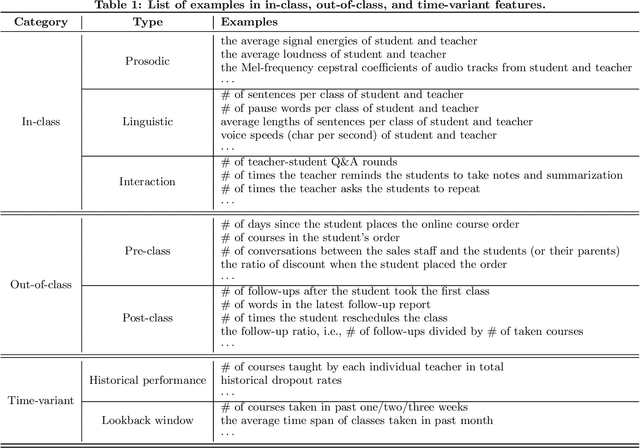

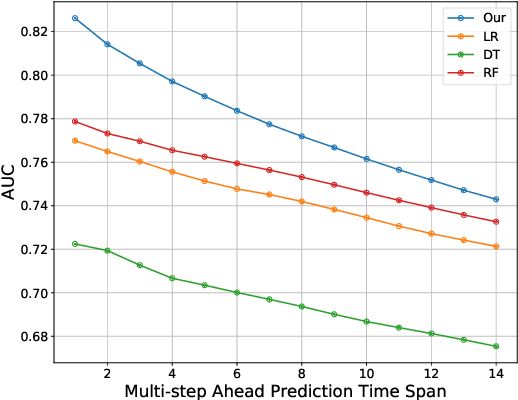
With the rapid emergence of K-12 online learning platforms, a new era of education has been opened up. By offering more affordable and personalized courses compared to in-person classrooms, K-12 online tutoring is pushing the boundaries of education to the general public. It is crucial to have a dropout warning framework to preemptively identify K-12 students who are at risk of dropping out of the online courses. Prior researchers have focused on predicting dropout in Massive Open Online Courses (MOOCs), which often deliver higher education, i.e., graduate level courses at top institutions. However, few studies have focused on developing a machine learning approach for students in K-12 online courses. The dropout prediction scenarios are significantly different between MOOC based learning and K-12 online tutoring in many aspects such as environmental modalities, learning goals, online behaviors, etc. In this paper, we develop a machine learning framework to conduct accurate at-risk student identification specialized in K-12 multimodal online environments. Our approach considers both online and offline factors around K-12 students and aims at solving the challenging problems of (1) multiple modalities, i.e., K-12 online environments involve interactions from different modalities such as video, voice, etc; (2) length variability, i.e., students with different lengths of learning history; (3) time sensitivity, i.e., the dropout likelihood is changing with time; and (4) data imbalance, i.e., only less than 20\% of K-12 students will choose to drop out the class. We conduct a wide range of offline and online experiments to demonstrate the effectiveness of our approach. In our offline experiments, we show that our method improves the dropout prediction performance when compared to state-of-the-art baselines on a real-world educational data set.
NeuCrowd: Neural Sampling Network for Representation Learning with Crowdsourced Labels
Mar 21, 2020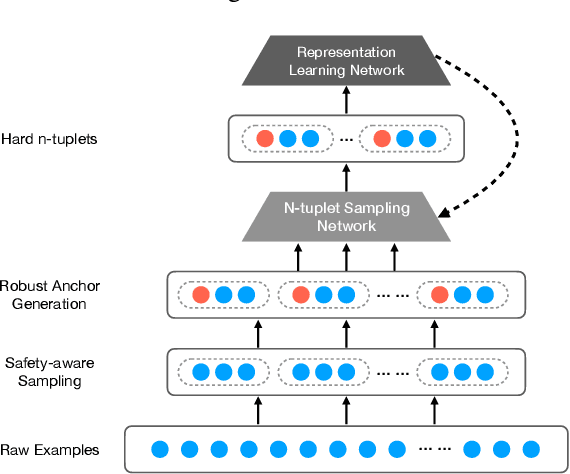
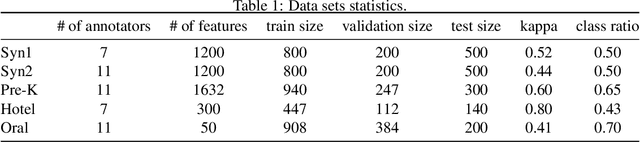
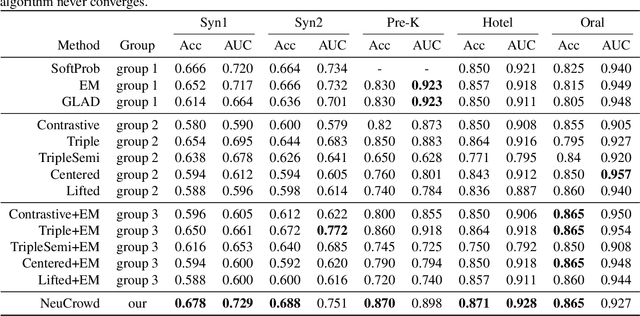
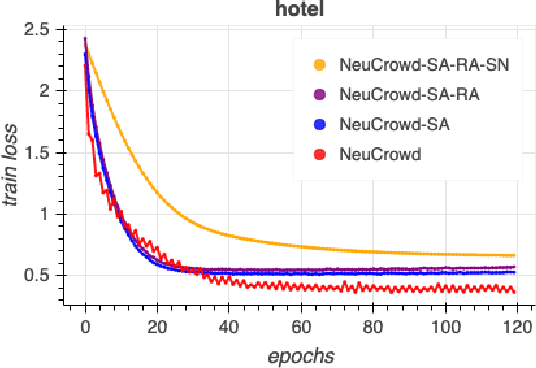
Representation learning approaches require a massive amount of discriminative training data, which is unavailable in many scenarios, such as healthcare, small city, education, etc. In practice, people refer to crowdsourcing to get annotated labels. However, due to issues like data privacy, budget limitation, shortage of domain-specific annotators, the number of crowdsourced labels are still very limited. Moreover, because of annotators' diverse expertises, crowdsourced labels are often inconsistent. Thus, directly applying existing representation learning algorithms may easily get the overfitting problem and yield suboptimal solutions. In this paper, we propose \emph{NeuCrowd}, a unified framework for representation learning from crowdsourced labels. The proposed framework (1) creates a sufficient number of high-quality \emph{n}-tuplet training samples by utilizing safety-aware sampling and robust anchor generation; and (2) automatically learns a neural sampling network that adaptively learns to select effective samples for representation learning network. The proposed framework is evaluated on both synthetic and real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC\footnote{To encourage the reproducible results, we make our code public on a github repository, i.e., \url{https://github.com/crowd-data-mining/NeuCrowd}}.
Graduate Employment Prediction with Bias
Dec 27, 2019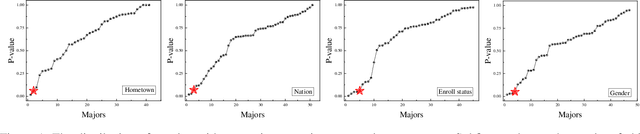
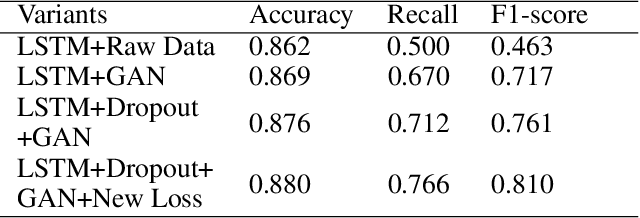
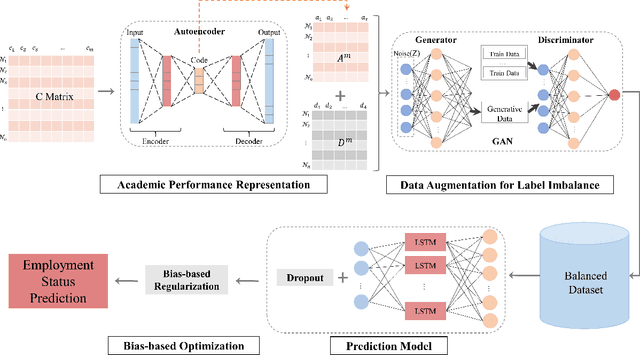
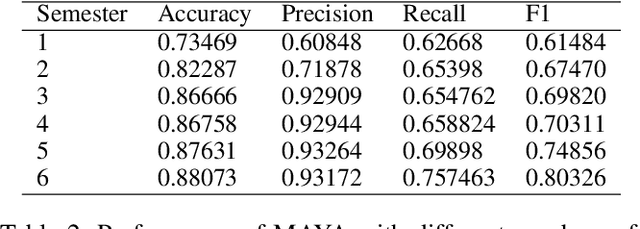
The failure of landing a job for college students could cause serious social consequences such as drunkenness and suicide. In addition to academic performance, unconscious biases can become one key obstacle for hunting jobs for graduating students. Thus, it is necessary to understand these unconscious biases so that we can help these students at an early stage with more personalized intervention. In this paper, we develop a framework, i.e., MAYA (Multi-mAjor emploYment stAtus) to predict students' employment status while considering biases. The framework consists of four major components. Firstly, we solve the heterogeneity of student courses by embedding academic performance into a unified space. Then, we apply a generative adversarial network (GAN) to overcome the class imbalance problem. Thirdly, we adopt Long Short-Term Memory (LSTM) with a novel dropout mechanism to comprehensively capture sequential information among semesters. Finally, we design a bias-based regularization to capture the job market biases. We conduct extensive experiments on a large-scale educational dataset and the results demonstrate the effectiveness of our prediction framework.