 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sequential Recommenders through Counterfactual Augmentation of System Exposure
Apr 18, 2025In sequential recommendation (SR), system exposure refers to items that are exposed to the user. Typically, only a few of the exposed items would be interacted with by the user. Although SR has achieved great success in predicting future user interests, existing SR methods still fail to fully exploit system exposure data. Most methods only model items that have been interacted with, while the large volume of exposed but non-interacted items is overlooked. Even methods that consider the whole system exposure typically train the recommender using only the logged historical system exposure, without exploring unseen user interests. In this paper, we propose counterfactual augmentation over system exposure for sequential recommendation (CaseRec). To better model historical system exposure, CaseRec introduces reinforcement learning to account for different exposure rewards. CaseRec uses a decision transformer-based sequential model to take an exposure sequence as input and assigns different rewards according to the user feedback. To further explore unseen user interests, CaseRec proposes to perform counterfactual augmentation, where exposed original items are replaced with counterfactual items. Then, a transformer-based user simulator is proposed to predict the user feedback reward for the augmented items. Augmentation, together with the user simulator, constructs counterfactual exposure sequences to uncover new user interests. Finally, CaseRec jointly uses the logged exposure sequences with the counterfactual exposure sequences to train a decision transformer-based sequential model for generating recommendation. Experiments on three real-world benchmarks show the effectiveness of CaseRec. Our code is available at https://github.com/ZiqiZhao1/CaseRec.
Constrained Auto-Regressive Decoding Constrains Generative Retrieval
Apr 14, 2025
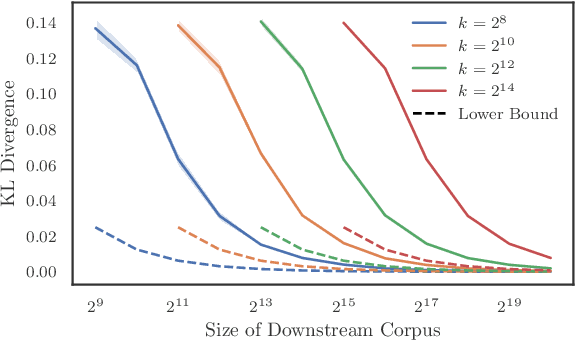
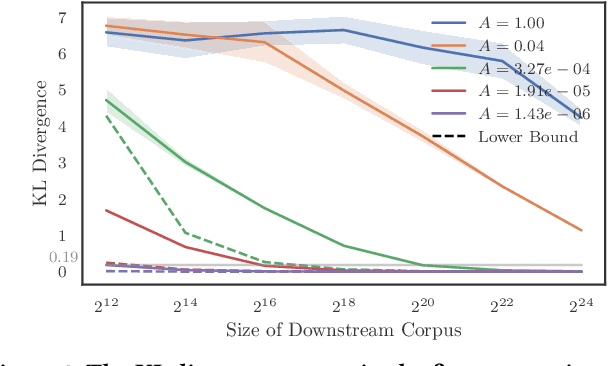
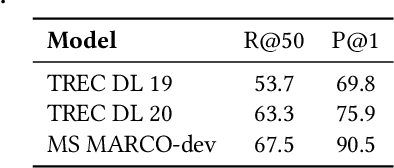
Generative retrieval seeks to replace traditional search index data structures with a single large-scale neural network, offering the potential for improved efficiency and seamless integration with generative large language models. As an end-to-end paradigm, generative retrieval adopts a learned differentiable search index to conduct retrieval by directly generating document identifiers through corpus-specific constrained decoding. The generalization capabilities of generative retrieval on out-of-distribution corpora have gathered significant attention. In this paper, we examine the inherent limitations of constrained auto-regressive generation from two essential perspectives: constraints and beam search. We begin with the Bayes-optimal setting where the generative retrieval model exactly captures the underlying relevance distribution of all possible documents. Then we apply the model to specific corpora by simply adding corpus-specific constraints. Our main findings are two-fold: (i) For the effect of constraints, we derive a lower bound of the error, in terms of the KL divergence between the ground-truth and the model-predicted step-wise marginal distributions. (ii) For the beam search algorithm used during generation, we reveal that the usage of marginal distributions may not be an ideal approach. This paper aims to improve our theoretical understanding of the generalization capabilities of the auto-regressive decoding retrieval paradigm, laying a foundation for its limitations and inspiring future advancements toward more robust and generalizable generative retrieval.
Cognitive Debiasing Large Language Models for Decision-Making
Apr 10, 2025Large language models (LLMs) have shown potential in supporting decision-making applications, particularly as personal conversational assistants in the financial, healthcare, and legal domains. While prompt engineering strategies have enhanced the capabilities of LLMs in decision-making, cognitive biases inherent to LLMs present significant challenges. Cognitive biases are systematic patterns of deviation from norms or rationality in decision-making that can lead to the production of inaccurate outputs. Existing cognitive bias mitigation strategies assume that input prompts contain (exactly) one type of cognitive bias and therefore fail to perform well in realistic settings where there maybe any number of biases. To fill this gap, we propose a cognitive debiasing approach, called self-debiasing, that enhances the reliability of LLMs by iteratively refining prompts. Our method follows three sequential steps -- bias determination, bias analysis, and cognitive debiasing -- to iteratively mitigate potential cognitive biases in prompts. Experimental results on finance, healthcare, and legal decision-making tasks, using both closed-source and open-source LLMs, demonstrate that the proposed self-debiasing method outperforms both advanced prompt engineering methods and existing cognitive debiasing techniques in average accuracy under no-bias, single-bias, and multi-bias settings.
A Universal Model Combining Differential Equations and Neural Networks for Ball Trajectory Prediction
Mar 25, 2025This paper presents a data driven universal ball trajectory prediction method integrated with physics equations. Existing methods are designed for specific ball types and struggle to generalize. This challenge arises from three key factors. First, learning-based models require large datasets but suffer from accuracy drops in unseen scenarios. Second, physics-based models rely on complex formulas and detailed inputs, yet accurately obtaining ball states, such as spin, is often impractical. Third, integrating physical principles with neural networks to achieve high accuracy, fast inference, and strong generalization remains difficult. To address these issues, we propose an innovative approach that incorporates physics-based equations and neural networks. We first derive three generalized physical formulas. Then, using a neural network and observed trajectory points, we infer certain parameters while fitting the remaining ones. These formulas enable precise trajectory prediction with minimal training data: only a few dozen samples. Extensive experiments demonstrate our method superiority in generalization, real-time performance, and accuracy.
UIPE: Enhancing LLM Unlearning by Removing Knowledge Related to Forgetting Targets
Mar 06, 2025Large Language Models (LLMs) inevitably acquire harmful information during training on massive datasets. LLM unlearning aims to eliminate the influence of such harmful information while maintaining the model's overall performance. Existing unlearning methods, represented by gradient ascent-based approaches, primarily focus on forgetting target data while overlooking the crucial impact of logically related knowledge on the effectiveness of unlearning. In this paper, through both theoretical and experimental analyses, we first demonstrate that a key reason for the suboptimal unlearning performance is that models can reconstruct the target content through reasoning with logically related knowledge. To address this issue, we propose Unlearning Improvement via Parameter Extrapolation (UIPE), a method that removes knowledge highly correlated with the forgetting targets. Experimental results show that UIPE significantly enhances the performance of various mainstream LLM unlearning methods on the TOFU benchmark.
A Cooperative Multi-Agent Framework for Zero-Shot Named Entity Recognition
Feb 25, 2025Zero-shot named entity recognition (NER) aims to develop entity recognition systems from unannotated text corpora. This task presents substantial challenges due to minimal human intervention. Recent work has adapted large language models (LLMs) for zero-shot NER by crafting specialized prompt templates. It advances model self-learning abilities by incorporating self-annotated demonstrations. However, two important challenges persist: (i) Correlations between contexts surrounding entities are overlooked, leading to wrong type predictions or entity omissions. (ii) The indiscriminate use of task demonstrations, retrieved through shallow similarity-based strategies, severely misleads LLMs during inference. In this paper, we introduce the cooperative multi-agent system (CMAS), a novel framework for zero-shot NER that uses the collective intelligence of multiple agents to address the challenges outlined above. CMAS has four main agents: (i) a self-annotator, (ii) a type-related feature (TRF) extractor, (iii) a demonstration discriminator, and (iv) an overall predictor. To explicitly capture correlations between contexts surrounding entities, CMAS reformulates NER into two subtasks: recognizing named entities and identifying entity type-related features within the target sentence. To enable controllable utilization of demonstrations, a demonstration discriminator is established to incorporate the self-reflection mechanism, automatically evaluating helpfulness scores for the target sentence. Experimental results show that CMAS significantly improves zero-shot NER performance across six benchmarks, including both domain-specific and general-domain scenarios. Furthermore, CMAS demonstrates its effectiveness in few-shot settings and with various LLM backbones.
ASLoRA: Adaptive Sharing Low-Rank Adaptation Across Layers
Dec 13, 2024



As large language models (LLMs) grow in size, traditional full fine-tuning becomes increasingly impractical due to its high computational and storage costs. Although popular parameter-efficient fine-tuning methods, such as LoRA, have significantly reduced the number of tunable parameters, there is still room for further optimization. In this work, we propose ASLoRA, a cross-layer parameter-sharing strategy combining global sharing with partial adaptive sharing. Specifically, we share the low-rank matrix A across all layers and adaptively merge matrix B during training. This sharing mechanism not only mitigates overfitting effectively but also captures inter-layer dependencies, significantly enhancing the model's representational capability. We conduct extensive experiments on various NLP tasks, showing that ASLoRA outperforms LoRA while using less than 25% of the parameters, highlighting its flexibility and superior parameter efficiency. Furthermore, in-depth analyses of the adaptive sharing strategy confirm its significant advantages in enhancing both model flexibility and task adaptability.
Uncovering Overfitting in Large Language Model Editing
Oct 10, 2024



Knowledge editing has been proposed as an effective method for updating and correcting the internal knowledge of Large Language Models (LLMs). However, existing editing methods often struggle with complex tasks, such as multi-hop reasoning. In this paper, we identify and investigate the phenomenon of Editing Overfit, where edited models assign disproportionately high probabilities to the edit target, hindering the generalization of new knowledge in complex scenarios. We attribute this issue to the current editing paradigm, which places excessive emphasis on the direct correspondence between the input prompt and the edit target for each edit sample. To further explore this issue, we introduce a new benchmark, EVOKE (EValuation of Editing Overfit in Knowledge Editing), along with fine-grained evaluation metrics. Through comprehensive experiments and analysis, we demonstrate that Editing Overfit is prevalent in current editing methods and that common overfitting mitigation strategies are of limited effectiveness in knowledge editing. To overcome this, inspired by LLMs' knowledge recall mechanisms, we propose a new plug-and-play strategy called Learn to Inference (LTI), which introduce a Multi-stage Inference Constraint module to guide the edited models in recalling new knowledge similarly to how unedited LLMs leverage knowledge through in-context learning. Extensive experimental results across a wide range of tasks validate the effectiveness of LTI in mitigating Editing Overfit.
Enhancing Multi-hop Reasoning through Knowledge Erasure in Large Language Model Editing
Aug 22, 2024



Large language models (LLMs) face challenges with internal knowledge inaccuracies and outdated information. Knowledge editing has emerged as a pivotal approach to mitigate these issues. Although current knowledge editing techniques exhibit promising performance in single-hop reasoning tasks, they show limitations when applied to multi-hop reasoning. Drawing on cognitive neuroscience and the operational mechanisms of LLMs, we hypothesize that the residual single-hop knowledge after editing causes edited models to revert to their original answers when processing multi-hop questions, thereby undermining their performance in multihop reasoning tasks. To validate this hypothesis, we conduct a series of experiments that empirically confirm our assumptions. Building on the validated hypothesis, we propose a novel knowledge editing method that incorporates a Knowledge Erasure mechanism for Large language model Editing (KELE). Specifically, we design an erasure function for residual knowledge and an injection function for new knowledge. Through joint optimization, we derive the optimal recall vector, which is subsequently utilized within a rank-one editing framework to update the parameters of targeted model layers. Extensive experiments on GPT-J and GPT-2 XL demonstrate that KELE substantially enhances the multi-hop reasoning capability of edited LLMs.
Beyond Local Views: Global State Inference with Diffusion Models for Cooperative Multi-Agent Reinforcement Learning
Aug 18, 2024



In partially observable multi-agent systems, agents typically only have access to local observations. This severely hinders their ability to make precise decisions, particularly during decentralized execution. To alleviate this problem and inspired by image outpainting, we propose State Inference with Diffusion Models (SIDIFF), which uses diffusion models to reconstruct the original global state based solely on local observations. SIDIFF consists of a state generator and a state extractor, which allow agents to choose suitable actions by considering both the reconstructed global state and local observations. In addition, SIDIFF can be effortlessly incorporated into current multi-agent reinforcement learning algorithms to improve their performance. Finally, we evaluated SIDIFF on different experimental platforms, including Multi-Agent Battle City (MABC), a novel and flexible multi-agent reinforcement learning environment we developed. SIDIFF achieved desirable results and outperformed other popular algorithms.