 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Mar 11, 2021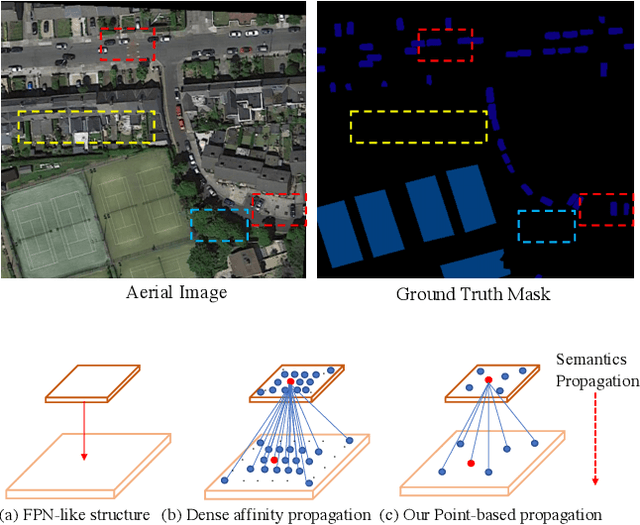
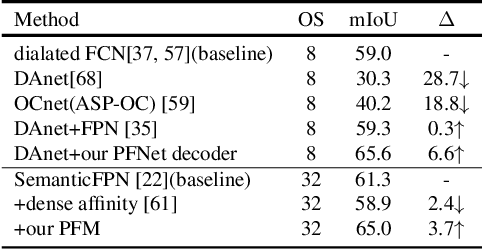
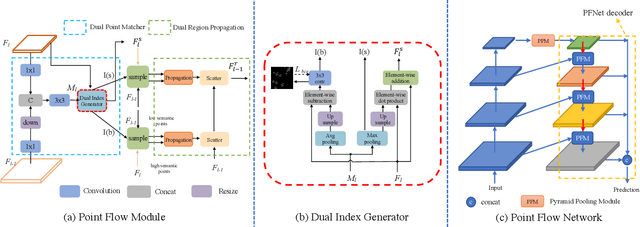
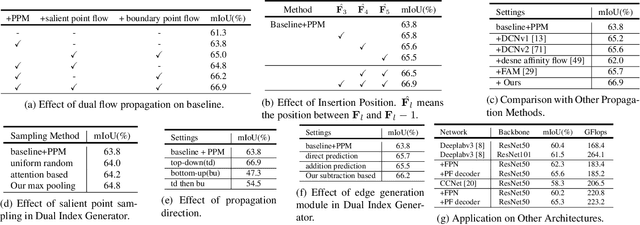
Aerial Image Segmentation is a particular semantic segmentation problem and has several challenging characteristics that general semantic segmentation does not have. There are two critical issues: The one is an extremely foreground-background imbalanced distribution, and the other is multiple small objects along with the complex background. Such problems make the recent dense affinity context modeling perform poorly even compared with baselines due to over-introduced background context. To handle these problems, we propose a point-wise affinity propagation module based on the Feature Pyramid Network (FPN) framework, named PointFlow. Rather than dense affinity learning, a sparse affinity map is generated upon selected points between the adjacent features, which reduces the noise introduced by the background while keeping efficiency. In particular, we design a dual point matcher to select points from the salient area and object boundaries, respectively. Experimental results on three different aerial segmentation datasets suggest that the proposed method is more effective and efficient than state-of-the-art general semantic segmentation methods. Especially, our methods achieve the best speed and accuracy trade-off on three aerial benchmarks. Further experiments on three general semantic segmentation datasets prove the generality of our method. Code will be provided in (https: //github.com/lxtGH/PFSegNets).
Dissecting the Diffusion Process in Linear Graph Convolutional Networks
Feb 22, 2021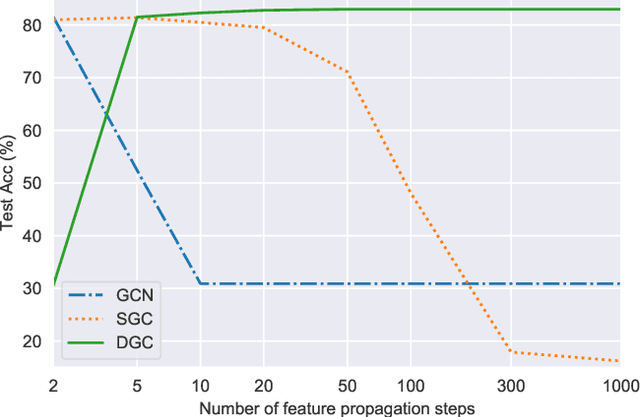
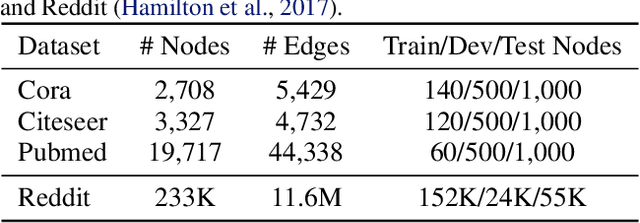
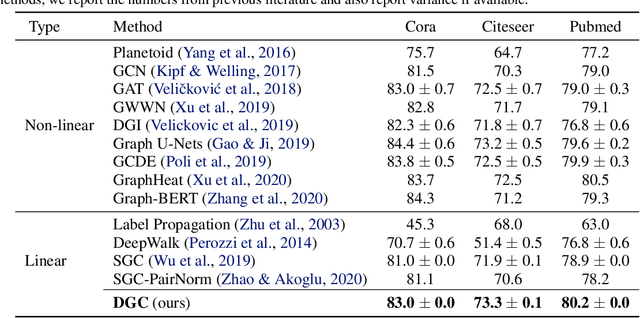
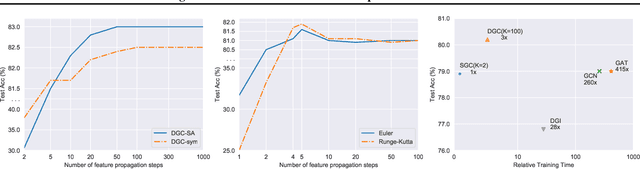
Graph Convolutional Networks (GCNs) have attracted more and more attentions in recent years. A typical GCN layer consists of a linear feature propagation step and a nonlinear transformation step. Recent works show that a linear GCN can achieve comparable performance to the original non-linear GCN while being much more computationally efficient. In this paper, we dissect the feature propagation steps of linear GCNs from a perspective of continuous graph diffusion, and analyze why linear GCNs fail to benefit from more propagation steps. Following that, we propose Decoupled Graph Convolution (DGC) that decouples the terminal time and the feature propagation steps, making it more flexible and capable of exploiting a very large number of feature propagation steps. Experiments demonstrate that our proposed DGC improves linear GCNs by a large margin and makes them competitive with many modern variants of non-linear GCNs.
Investigating Bi-Level Optimization for Learning and Vision from a Unified Perspective: A Survey and Beyond
Jan 27, 2021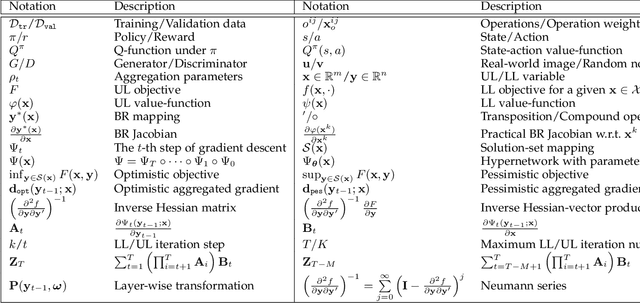
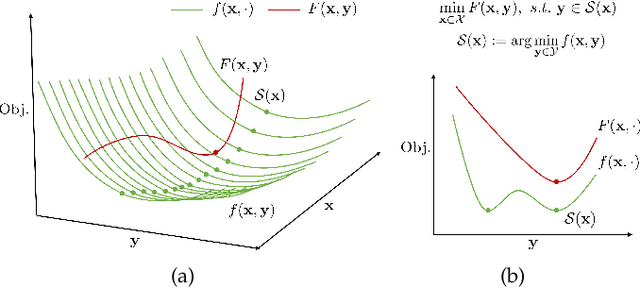
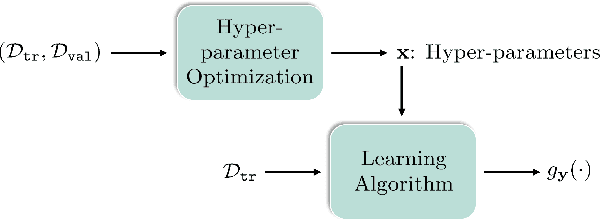
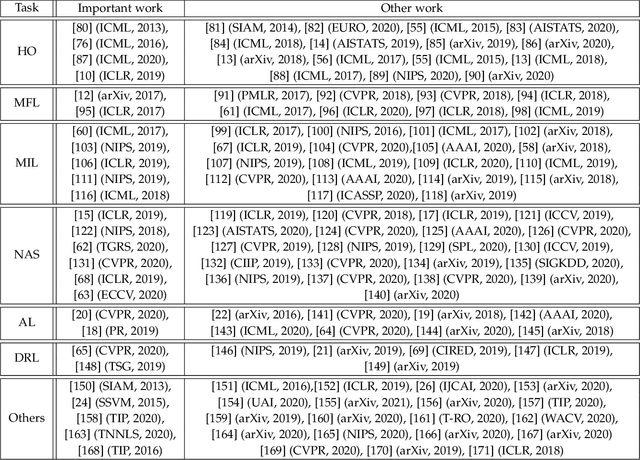
Bi-Level Optimization (BLO) is originated from the area of economic game theory and then introduced into the optimization community. BLO is able to handle problems with a hierarchical structure, involving two levels of optimization tasks, where one task is nested inside the other. In machine learning and computer vision fields, despite the different motivations and mechanisms, a lot of complex problems, such as hyper-parameter optimization, multi-task and meta-learning, neural architecture search, adversarial learning and deep reinforcement learning, actually all contain a series of closely related subproblms. In this paper, we first uniformly express these complex learning and vision problems from the perspective of BLO. Then we construct a value-function-based single-level reformulation and establish a unified algorithmic framework to understand and formulate mainstream gradient-based BLO methodologies, covering aspects ranging from fundamental automatic differentiation schemes to various accelerations, simplifications, extensions and their convergence and complexity properties. Last but not least, we discuss the potentials of our unified BLO framework for designing new algorithms and point out some promising directions for future research.
Towards Improving the Consistency, Efficiency, and Flexibility of Differentiable Neural Architecture Search
Jan 27, 2021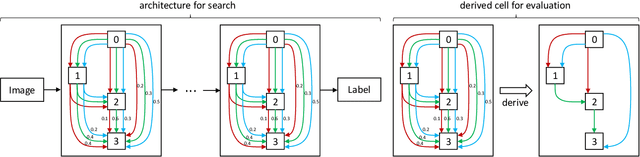
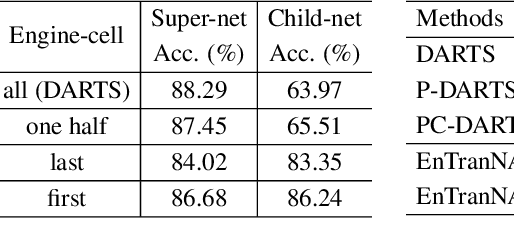
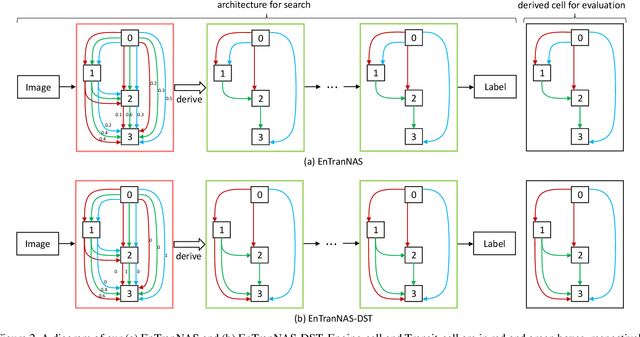

Most differentiable neural architecture search methods construct a super-net for search and derive a target-net as its sub-graph for evaluation. There exists a significant gap between the architectures in search and evaluation. As a result, current methods suffer from an inconsistent, inefficient, and inflexible search process. In this paper, we introduce EnTranNAS that is composed of Engine-cells and Transit-cells. The Engine-cell is differentiable for architecture search, while the Transit-cell only transits a sub-graph by architecture derivation. Consequently, the gap between the architectures in search and evaluation is significantly reduced. Our method also spares much memory and computation cost, which speeds up the search process. A feature sharing strategy is introduced for more balanced optimization and more efficient search. Furthermore, we develop an architecture derivation method to replace the traditional one that is based on a hand-crafted rule. Our method enables differentiable sparsification, and keeps the derived architecture equivalent to that of Engine-cell, which further improves the consistency between search and evaluation. Besides, it supports the search for topology where a node can be connected to prior nodes with any number of connections, so that the searched architectures could be more flexible. For experiments on CIFAR-10, our search on the standard space requires only 0.06 GPU-day. We further have an error rate of 2.22% with 0.07 GPU-day for the search on an extended space. We can also directly perform the search on ImageNet with topology learnable and achieve a top-1 error rate of 23.8% in 2.1 GPU-day.
Learning Optimization-inspired Image Propagation with Control Mechanisms and Architecture Augmentations for Low-level Vision
Dec 10, 2020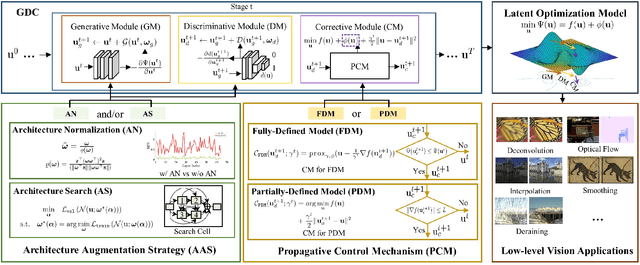



In recent years, building deep learning models from optimization perspectives has becoming a promising direction for solving low-level vision problems. The main idea of most existing approaches is to straightforwardly combine numerical iterations with manually designed network architectures to generate image propagations for specific kinds of optimization models. However, these heuristic learning models often lack mechanisms to control the propagation and rely on architecture engineering heavily. To mitigate the above issues, this paper proposes a unified optimization-inspired deep image propagation framework to aggregate Generative, Discriminative and Corrective (GDC for short) principles for a variety of low-level vision tasks. Specifically, we first formulate low-level vision tasks using a generic optimization objective and construct our fundamental propagative modules from three different viewpoints, i.e., the solution could be obtained/learned 1) in generative manner; 2) based on discriminative metric, and 3) with domain knowledge correction. By designing control mechanisms to guide image propagations, we then obtain convergence guarantees of GDC for both fully- and partially-defined optimization formulations. Furthermore, we introduce two architecture augmentation strategies (i.e., normalization and automatic search) to respectively enhance the propagation stability and task/data-adaption ability. Extensive experiments on different low-level vision applications demonstrate the effectiveness and flexibility of GDC.
Towards Efficient Scene Understanding via Squeeze Reasoning
Nov 06, 2020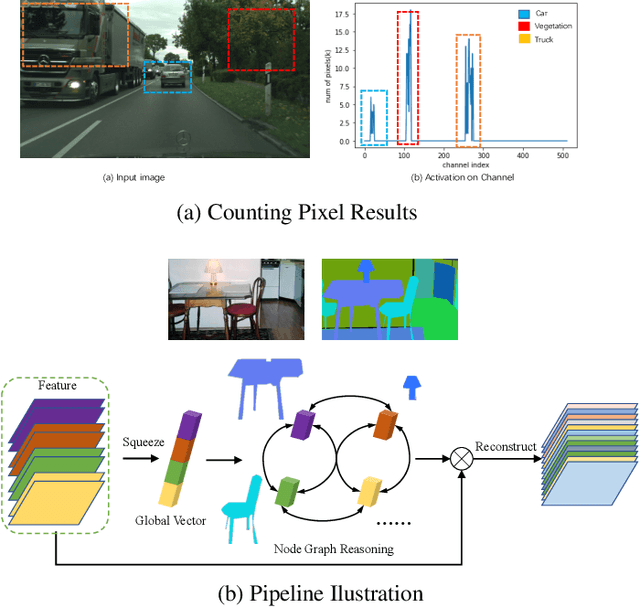

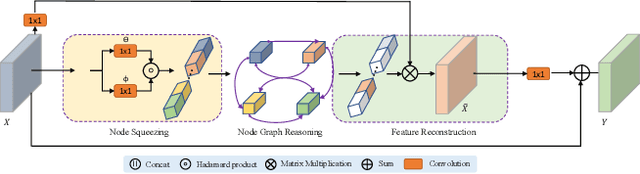
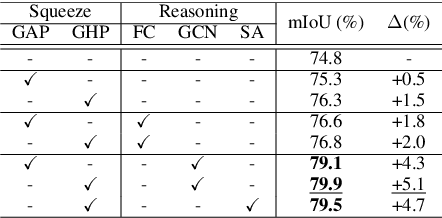
Graph-based convolutional model such as non-local block has shown to be effective for strengthening the context modeling ability in convolutional neural networks (CNNs). However, its pixel-wise computational overhead is prohibitive which renders it unsuitable for high resolution imagery. In this paper, we explore the efficiency of context graph reasoning and propose a novel framework called Squeeze Reasoning. Instead of propagating information on the spatial map, we first learn to squeeze the input feature into a channel-wise global vector and perform reasoning within the single vector where the computation cost can be significantly reduced. Specifically, we build the node graph in the vector where each node represents an abstract semantic concept. The refined feature within the same semantic category results to be consistent, which is thus beneficial for downstream tasks. We show that our approach can be modularized as an end-to-end trained block and can be easily plugged into existing networks. Despite its simplicity and being lightweight, our strategy allows us to establish a new state-of-the-art on semantic segmentation and show significant improvements with respect to strong, state-of-the-art baselines on various other scene understanding tasks including object detection, instance segmentation and panoptic segmentation. Code will be made available to foster any further research
ISTA-NAS: Efficient and Consistent Neural Architecture Search by Sparse Coding
Oct 13, 2020
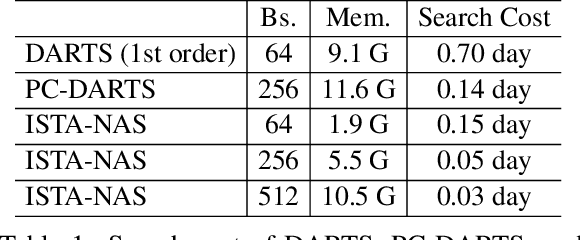

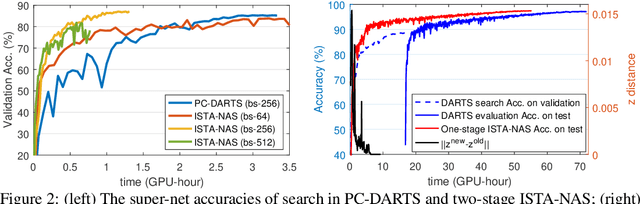
Neural architecture search (NAS) aims to produce the optimal sparse solution from a high-dimensional space spanned by all candidate connections. Current gradient-based NAS methods commonly ignore the constraint of sparsity in the search phase, but project the optimized solution onto a sparse one by post-processing. As a result, the dense super-net for search is inefficient to train and has a gap with the projected architecture for evaluation. In this paper, we formulate neural architecture search as a sparse coding problem. We perform the differentiable search on a compressed lower-dimensional space that has the same validation loss as the original sparse solution space, and recover an architecture by solving the sparse coding problem. The differentiable search and architecture recovery are optimized in an alternate manner. By doing so, our network for search at each update satisfies the sparsity constraint and is efficient to train. In order to also eliminate the depth and width gap between the network in search and the target-net in evaluation, we further propose a method to search and evaluate in one stage under the target-net settings. When training finishes, architecture variables are absorbed into network weights. Thus we get the searched architecture and optimized parameters in a single run. In experiments, our two-stage method on CIFAR-10 requires only 0.05 GPU-day for search. Our one-stage method produces state-of-the-art performances on both CIFAR-10 and ImageNet at the cost of only evaluation time.
Variance Reduced EXTRA and DIGing and Their Optimal Acceleration for Strongly Convex Decentralized Optimization
Oct 10, 2020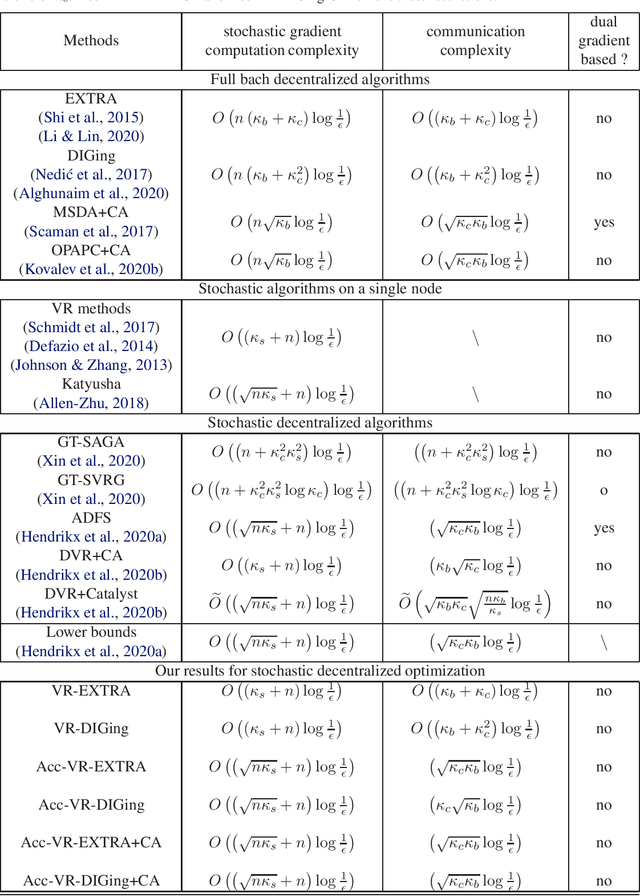
We study stochastic decentralized optimization for the problem of training machine learning models with large-scale distributed data. We extend the widely used EXTRA and DIGing methods with variance reduction (VR), and propose two methods: VR-EXTRA and VR-DIGing. The proposed VR-EXTRA requires the time of $O((\kappa_s+n)\log\frac{1}{\epsilon})$ stochastic gradient evaluations and $O((\kappa_b+\kappa_c)\log\frac{1}{\epsilon})$ communication rounds to reach precision $\epsilon$, where $\kappa_s$ and $\kappa_b$ are the stochastic condition number and batch condition number for strongly convex and smooth problems, respectively, $\kappa_c$ is the condition number of the communication network, and $n$ is the sample size on each distributed node. The proposed VR-DIGing has a little higher communication cost of $O((\kappa_b+\kappa_c^2)\log\frac{1}{\epsilon})$. Our stochastic gradient computation complexities are the same as the ones of single-machine VR methods, such as SAG, SAGA, and SVRG, and our communication complexities keep the same as those of EXTRA and DIGing, respectively. To further speed up the convergence, we also propose the accelerated VR-EXTRA and VR-DIGing with both the optimal $O((\sqrt{n\kappa_s}+n)\log\frac{1}{\epsilon})$ stochastic gradient computation complexity and $O(\sqrt{\kappa_b\kappa_c}\log\frac{1}{\epsilon})$ communication complexity. Our stochastic gradient computation complexity is also the same as the ones of single-machine accelerated VR methods, such as Katyusha, and our communication complexity keeps the same as those of accelerated full batch decentralized methods, such as MSDA.
Improving Semantic Segmentation via Decoupled Body and Edge Supervision
Aug 18, 2020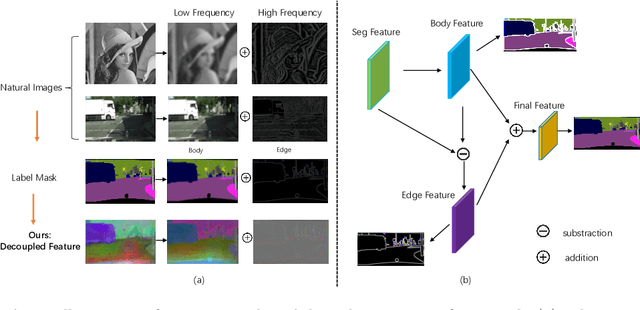
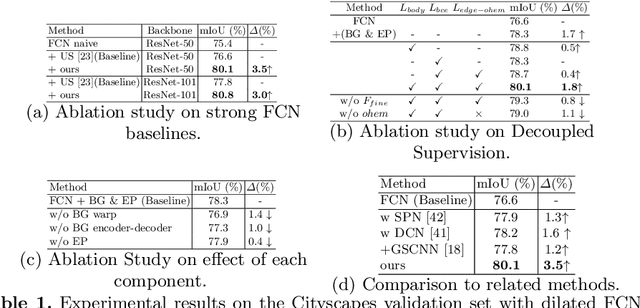
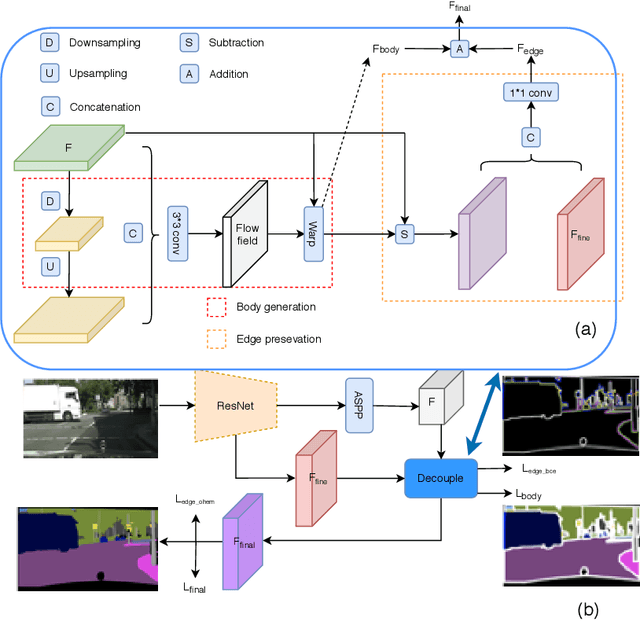

Existing semantic segmentation approaches either aim to improve the object's inner consistency by modeling the global context, or refine objects detail along their boundaries by multi-scale feature fusion. In this paper, a new paradigm for semantic segmentation is proposed. Our insight is that appealing performance of semantic segmentation requires \textit{explicitly} modeling the object \textit{body} and \textit{edge}, which correspond to the high and low frequency of the image. To do so, we first warp the image feature by learning a flow field to make the object part more consistent. The resulting body feature and the residual edge feature are further optimized under decoupled supervision by explicitly sampling different parts (body or edge) pixels. We show that the proposed framework with various baselines or backbone networks leads to better object inner consistency and object boundaries. Extensive experiments on four major road scene semantic segmentation benchmarks including \textit{Cityscapes}, \textit{CamVid}, \textit{KIITI} and \textit{BDD} show that our proposed approach establishes new state of the art while retaining high efficiency in inference. In particular, we achieve 83.7 mIoU \% on Cityscape with only fine-annotated data. Code and models are made available to foster any further research (\url{https://github.com/lxtGH/DecoupleSegNets}).
PDO-eConvs: Partial Differential Operator Based Equivariant Convolutions
Aug 11, 2020
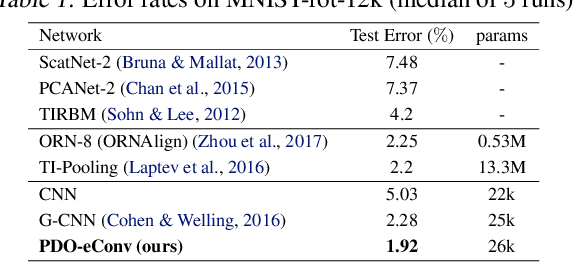

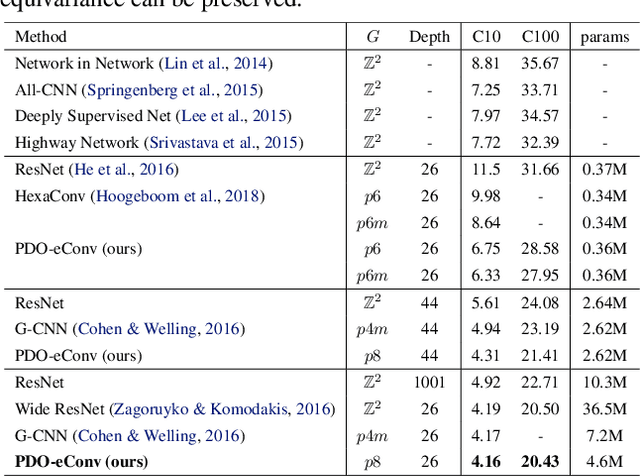
Recent research has shown that incorporating equivariance into neural network architectures is very helpful, and there have been some works investigating the equivariance of networks under group actions. However, as digital images and feature maps are on the discrete meshgrid, corresponding equivariance-preserving transformation groups are very limited. In this work, we deal with this issue from the connection between convolutions and partial differential operators (PDOs). In theory, assuming inputs to be smooth, we transform PDOs and propose a system which is equivariant to a much more general continuous group, the $n$-dimension Euclidean group. In implementation, we discretize the system using the numerical schemes of PDOs, deriving approximately equivariant convolutions (PDO-eConvs). Theoretically, the approximation error of PDO-eConvs is of the quadratic order. It is the first time that the error analysis is provided when the equivariance is approximate. Extensive experiments on rotated MNIST and natural image classification show that PDO-eConvs perform competitively yet use parameters much more efficiently. Particularly, compared with Wide ResNets, our methods result in better results using only 12.6% parameters.