 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Agentic Evolution is the Path to Evolving LLMs
Jan 30, 2026As Large Language Models (LLMs) move from curated training sets into open-ended real-world environments, a fundamental limitation emerges: static training cannot keep pace with continual deployment environment change. Scaling training-time and inference-time compute improves static capability but does not close this train-deploy gap. We argue that addressing this limitation requires a new scaling axis-evolution. Existing deployment-time adaptation methods, whether parametric fine-tuning or heuristic memory accumulation, lack the strategic agency needed to diagnose failures and produce durable improvements. Our position is that agentic evolution represents the inevitable future of LLM adaptation, elevating evolution itself from a fixed pipeline to an autonomous evolver agent. We instantiate this vision in a general framework, A-Evolve, which treats deployment-time improvement as a deliberate, goal-directed optimization process over persistent system state. We further propose the evolution-scaling hypothesis: the capacity for adaptation scales with the compute allocated to evolution, positioning agentic evolution as a scalable path toward sustained, open-ended adaptation in the real world.
Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
Jan 22, 2026Large language models (LLMs) can call tools effectively, yet they remain brittle in multi-turn execution: following a tool call error, smaller models often degenerate into repetitive invalid re-invocations, failing to interpret error feedback and self-correct. This brittleness hinders reliable real-world deployment, where the execution errors are inherently inevitable during tool interaction procedures. We identify a key limitation of current approaches: standard reinforcement learning (RL) treats errors as sparse negative rewards, providing no guidance on how to recover, while pre-collected synthetic error-correction datasets suffer from distribution mismatch with the model's on-policy error modes. To bridge this gap, we propose Fission-GRPO, a framework that converts execution errors into corrective supervision within the RL training loop. Our core mechanism fissions each failed trajectory into a new training instance by augmenting it with diagnostic feedback from a finetuned Error Simulator, then resampling recovery rollouts on-policy. This enables the model to learn from the precise errors it makes during exploration, rather than from static, pre-collected error cases. On the BFCL v4 Multi-Turn, Fission-GRPO improves the error recovery rate of Qwen3-8B by 5.7% absolute, crucially, yielding a 4% overall accuracy gain (42.75% to 46.75%) over GRPO and outperforming specialized tool-use agents.
dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal Large Language Models
Dec 22, 2025



Diffusion Multi-modal Large Language Models (dMLLMs) have recently emerged as a novel architecture unifying image generation and understanding. However, developing effective and efficient Test-Time Scaling (TTS) methods to unlock their full generative potential remains an underexplored challenge. To address this, we propose dMLLM-TTS, a novel framework operating on two complementary scaling axes: (1) trajectory exploration scaling to enhance the diversity of generated hypotheses, and (2) iterative refinement scaling for stable generation. Conventional TTS approaches typically perform linear search across these two dimensions, incurring substantial computational costs of O(NT) and requiring an external verifier for best-of-N selection. To overcome these limitations, we propose two innovations. First, we design an efficient hierarchical search algorithm with O(N+T) complexity that adaptively expands and prunes sampling trajectories. Second, we introduce a self-verified feedback mechanism that leverages the dMLLMs' intrinsic image understanding capabilities to assess text-image alignment, eliminating the need for external verifier. Extensive experiments on the GenEval benchmark across three representative dMLLMs (e.g., Lumina-DiMOO, MMaDA, Muddit) show that our framework substantially improves generation quality while achieving up to 6x greater efficiency than linear search. Project page: https://github.com/Alpha-VLLM/Lumina-DiMOO.
Latent-Space Autoregressive World Model for Efficient and Robust Image-Goal Navigation
Nov 14, 2025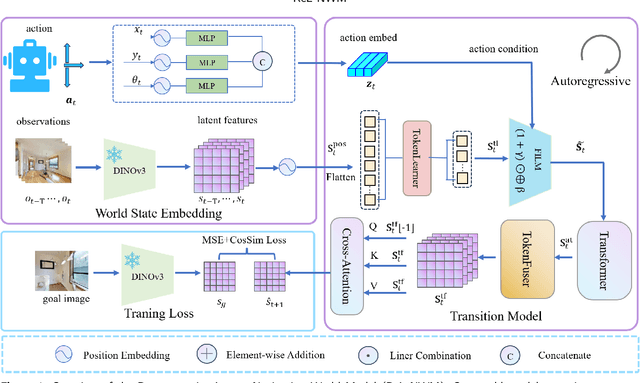
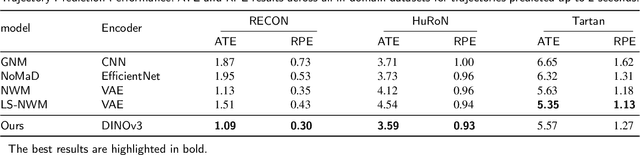
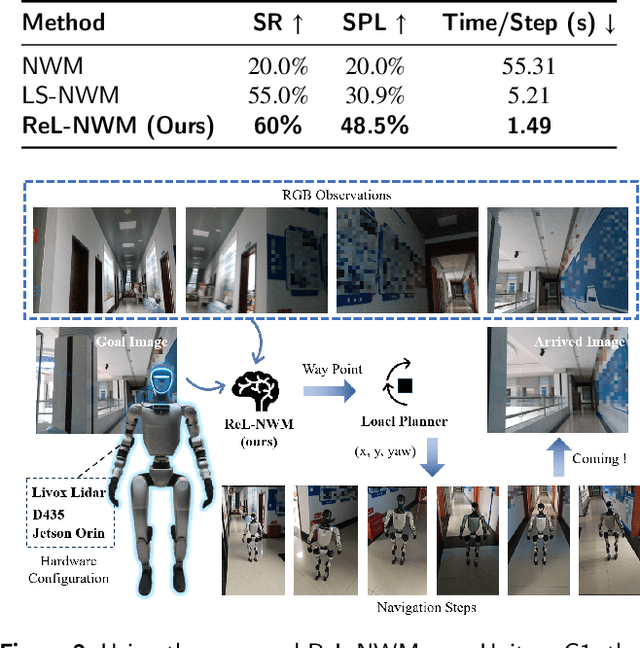
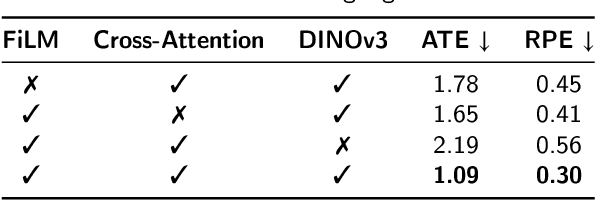
Traditional navigation methods rely heavily on accurate localization and mapping. In contrast, world models that capture environmental dynamics in latent space have opened up new perspectives for navigation tasks, enabling systems to move beyond traditional multi-module pipelines. However, world model often suffers from high computational costs in both training and inference. To address this, we propose LS-NWM - a lightweight latent space navigation world model that is trained and operates entirely in latent space, compared to the state-of-the-art baseline, our method reduces training time by approximately 3.2x and planning time by about 447x,while further improving navigation performance with a 35% higher SR and an 11% higher SPL. The key idea is that accurate pixel-wise environmental prediction is unnecessary for navigation. Instead, the model predicts future latent states based on current observational features and action inputs, then performs path planning and decision-making within this compact representation, significantly improving computational efficiency. By incorporating an autoregressive multi-frame prediction strategy during training, the model effectively captures long-term spatiotemporal dependencies, thereby enhancing navigation performance in complex scenarios. Experimental results demonstrate that our method achieves state-of-the-art navigation performance while maintaining a substantial efficiency advantage over existing approaches.
EMAformer: Enhancing Transformer through Embedding Armor for Time Series Forecasting
Nov 11, 2025Multivariate time series forecasting is crucial across a wide range of domains. While presenting notable progress for the Transformer architecture, iTransformer still lags behind the latest MLP-based models. We attribute this performance gap to unstable inter-channel relationships. To bridge this gap, we propose EMAformer, a simple yet effective model that enhances the Transformer with an auxiliary embedding suite, akin to armor that reinforces its ability. By introducing three key inductive biases, i.e., \textit{global stability}, \textit{phase sensitivity}, and \textit{cross-axis specificity}, EMAformer unlocks the further potential of the Transformer architecture, achieving state-of-the-art performance on 12 real-world benchmarks and reducing forecasting errors by an average of 2.73\% in MSE and 5.15\% in MAE. This significantly advances the practical applicability of Transformer-based approaches for multivariate time series forecasting. The code is available on https://github.com/PlanckChang/EMAformer.
On Continuous Optimization for Constraint Satisfaction Problems
Oct 06, 2025



Constraint satisfaction problems (CSPs) are fundamental in mathematics, physics, and theoretical computer science. While conflict-driven clause learning Boolean Satisfiability (SAT) solvers have achieved remarkable success and become the mainstream approach for Boolean satisfiability, recent advances show that modern continuous local search (CLS) solvers can achieve highly competitive results on certain classes of SAT problems. Motivated by these advances, we extend the CLS framework from Boolean SAT to general CSP with finite-domain variables and expressive constraints. We present FourierCSP, a continuous optimization framework that generalizes the Walsh-Fourier transform to CSP, allowing for transforming versatile constraints to compact multilinear polynomials, thereby avoiding the need for auxiliary variables and memory-intensive encodings. Our approach leverages efficient evaluation and differentiation of the objective via circuit-output probability and employs a projected gradient optimization method with theoretical guarantees. Empirical results on benchmark suites demonstrate that FourierCSP is scalable and competitive, significantly broadening the class of problems that can be efficiently solved by CLS techniques.
A Comprehensive Review of Agricultural Parcel and Boundary Delineation from Remote Sensing Images: Recent Progress and Future Perspectives
Aug 20, 2025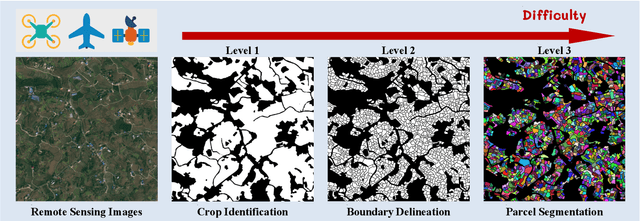
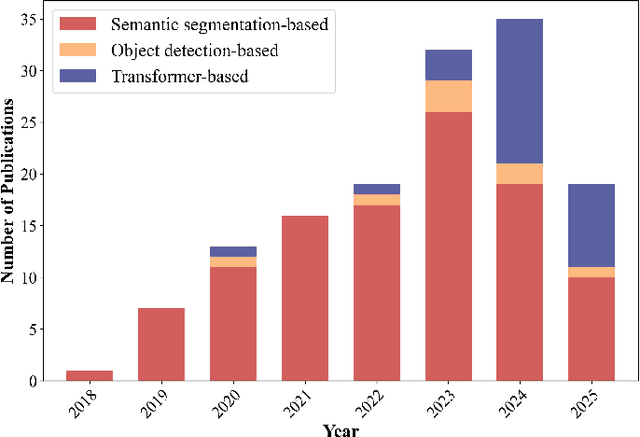
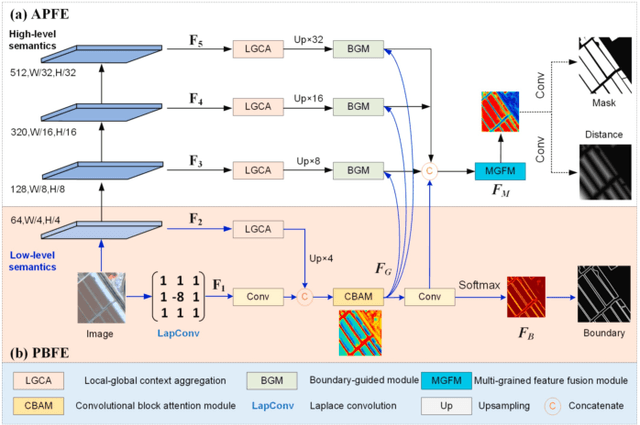
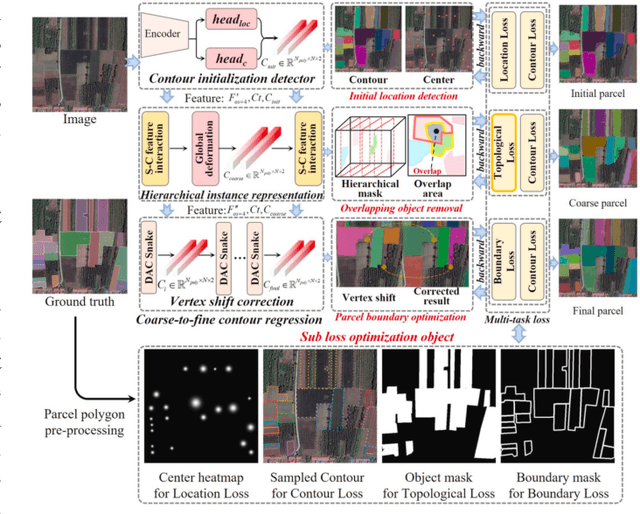
Powered by advances in multiple remote sensing sensors, the production of high spatial resolution images provides great potential to achieve cost-efficient and high-accuracy agricultural inventory and analysis in an automated way. Lots of studies that aim at providing an inventory of the level of each agricultural parcel have generated many methods for Agricultural Parcel and Boundary Delineation (APBD). This review covers APBD methods for detecting and delineating agricultural parcels and systematically reviews the past and present of APBD-related research applied to remote sensing images. With the goal to provide a clear knowledge map of existing APBD efforts, we conduct a comprehensive review of recent APBD papers to build a meta-data analysis, including the algorithm, the study site, the crop type, the sensor type, the evaluation method, etc. We categorize the methods into three classes: (1) traditional image processing methods (including pixel-based, edge-based and region-based); (2) traditional machine learning methods (such as random forest, decision tree); and (3) deep learning-based methods. With deep learning-oriented approaches contributing to a majority, we further discuss deep learning-based methods like semantic segmentation-based, object detection-based and Transformer-based methods. In addition, we discuss five APBD-related issues to further comprehend the APBD domain using remote sensing data, such as multi-sensor data in APBD task, comparisons between single-task learning and multi-task learning in the APBD domain, comparisons among different algorithms and different APBD tasks, etc. Finally, this review proposes some APBD-related applications and a few exciting prospects and potential hot topics in future APBD research. We hope this review help researchers who involved in APBD domain to keep track of its development and tendency.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Image Corruption-Inspired Membership Inference Attacks against Large Vision-Language Models
Jun 14, 2025Large vision-language models (LVLMs) have demonstrated outstanding performance in many downstream tasks. However, LVLMs are trained on large-scale datasets, which can pose privacy risks if training images contain sensitive information. Therefore, it is important to detect whether an image is used to train the LVLM. Recent studies have investigated membership inference attacks (MIAs) against LVLMs, including detecting image-text pairs and single-modality content. In this work, we focus on detecting whether a target image is used to train the target LVLM. We design simple yet effective Image Corruption-Inspired Membership Inference Attacks (ICIMIA) against LLVLMs, which are inspired by LVLM's different sensitivity to image corruption for member and non-member images. We first perform an MIA method under the white-box setting, where we can obtain the embeddings of the image through the vision part of the target LVLM. The attacks are based on the embedding similarity between the image and its corrupted version. We further explore a more practical scenario where we have no knowledge about target LVLMs and we can only query the target LVLMs with an image and a question. We then conduct the attack by utilizing the output text embeddings' similarity. Experiments on existing datasets validate the effectiveness of our proposed attack methods under those two different settings.
Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind
May 18, 2025Large Multimodal Models (LMMs) has demonstrated capabilities across various domains, but comprehensive benchmarks for agricultural remote sensing (RS) remain scarce. Existing benchmarks designed for agricultural RS scenarios exhibit notable limitations, primarily in terms of insufficient scene diversity in the dataset and oversimplified task design. To bridge this gap, we introduce AgroMind, a comprehensive agricultural remote sensing benchmark covering four task dimensions: spatial perception, object understanding, scene understanding, and scene reasoning, with a total of 13 task types, ranging from crop identification and health monitoring to environmental analysis. We curate a high-quality evaluation set by integrating eight public datasets and one private farmland plot dataset, containing 25,026 QA pairs and 15,556 images. The pipeline begins with multi-source data preprocessing, including collection, format standardization, and annotation refinement. We then generate a diverse set of agriculturally relevant questions through the systematic definition of tasks. Finally, we employ LMMs for inference, generating responses, and performing detailed examinations. We evaluated 18 open-source LMMs and 3 closed-source models on AgroMind. Experiments reveal significant performance gaps, particularly in spatial reasoning and fine-grained recognition, it is notable that human performance lags behind several leading LMMs. By establishing a standardized evaluation framework for agricultural RS, AgroMind reveals the limitations of LMMs in domain knowledge and highlights critical challenges for future work. Data and code can be accessed at https://rssysu.github.io/AgroMind/.