 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Language Models on Multiple Datasets for Citation Intention Classification
Oct 17, 2024



Citation intention Classification (CIC) tools classify citations by their intention (e.g., background, motivation) and assist readers in evaluating the contribution of scientific literature. Prior research has shown that pretrained language models (PLMs) such as SciBERT can achieve state-of-the-art performance on CIC benchmarks. PLMs are trained via self-supervision tasks on a large corpus of general text and can quickly adapt to CIC tasks via moderate fine-tuning on the corresponding dataset. Despite their advantages, PLMs can easily overfit small datasets during fine-tuning. In this paper, we propose a multi-task learning (MTL) framework that jointly fine-tunes PLMs on a dataset of primary interest together with multiple auxiliary CIC datasets to take advantage of additional supervision signals. We develop a data-driven task relation learning (TRL) method that controls the contribution of auxiliary datasets to avoid negative transfer and expensive hyper-parameter tuning. We conduct experiments on three CIC datasets and show that fine-tuning with additional datasets can improve the PLMs' generalization performance on the primary dataset. PLMs fine-tuned with our proposed framework outperform the current state-of-the-art models by 7% to 11% on small datasets while aligning with the best-performing model on a large dataset.
MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs
Jul 15, 2024The rapid progress in machine learning (ML) has brought forth many large language models (LLMs) that excel in various tasks and areas. These LLMs come with different abilities and costs in terms of computation or pricing. Since the demand for each query can vary, e.g., because of the queried domain or its complexity, defaulting to one LLM in an application is not usually the best choice, whether it is the biggest, priciest, or even the one with the best average test performance. Consequently, picking the right LLM that is both accurate and cost-effective for an application remains a challenge. In this paper, we introduce MetaLLM, a framework that dynamically and intelligently routes each query to the optimal LLM (among several available LLMs) for classification tasks, achieving significantly improved accuracy and cost-effectiveness. By framing the selection problem as a multi-armed bandit, MetaLLM balances prediction accuracy and cost efficiency under uncertainty. Our experiments, conducted on popular LLM platforms such as OpenAI's GPT models, Amazon's Titan, Anthropic's Claude, and Meta's LLaMa, showcase MetaLLM's efficacy in real-world scenarios, laying the groundwork for future extensions beyond classification tasks.
Fooling the Textual Fooler via Randomizing Latent Representations
Oct 02, 2023



Despite outstanding performance in a variety of NLP tasks, recent studies have revealed that NLP models are vulnerable to adversarial attacks that slightly perturb the input to cause the models to misbehave. Among these attacks, adversarial word-level perturbations are well-studied and effective attack strategies. Since these attacks work in black-box settings, they do not require access to the model architecture or model parameters and thus can be detrimental to existing NLP applications. To perform an attack, the adversary queries the victim model many times to determine the most important words in an input text and to replace these words with their corresponding synonyms. In this work, we propose a lightweight and attack-agnostic defense whose main goal is to perplex the process of generating an adversarial example in these query-based black-box attacks; that is to fool the textual fooler. This defense, named AdvFooler, works by randomizing the latent representation of the input at inference time. Different from existing defenses, AdvFooler does not necessitate additional computational overhead during training nor relies on assumptions about the potential adversarial perturbation set while having a negligible impact on the model's accuracy. Our theoretical and empirical analyses highlight the significance of robustness resulting from confusing the adversary via randomizing the latent space, as well as the impact of randomization on clean accuracy. Finally, we empirically demonstrate near state-of-the-art robustness of AdvFooler against representative adversarial word-level attacks on two benchmark datasets.
Walk-and-Relate: A Random-Walk-based Algorithm for Representation Learning on Sparse Knowledge Graphs
Sep 19, 2022
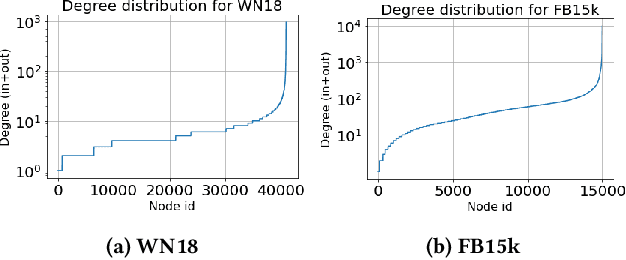

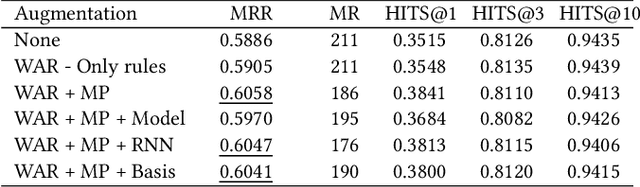
Knowledge graph (KG) embedding techniques use structured relationships between entities to learn low-dimensional representations of entities and relations. The traditional KG embedding techniques (such as TransE and DistMult) estimate these embeddings via simple models developed over observed KG triplets. These approaches differ in their triplet scoring loss functions. As these models only use the observed triplets to estimate the embeddings, they are prone to suffer through data sparsity that usually occurs in the real-world knowledge graphs, i.e., the lack of enough triplets per entity. To settle this issue, we propose an efficient method to augment the number of triplets to address the problem of data sparsity. We use random walks to create additional triplets, such that the relations carried by these introduced triplets entail the metapath induced by the random walks. We also provide approaches to accurately and efficiently filter out informative metapaths from the possible set of metapaths, induced by the random walks. The proposed approaches are model-agnostic, and the augmented training dataset can be used with any KG embedding approach out of the box. Experimental results obtained on the benchmark datasets show the advantages of the proposed approach.
An Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022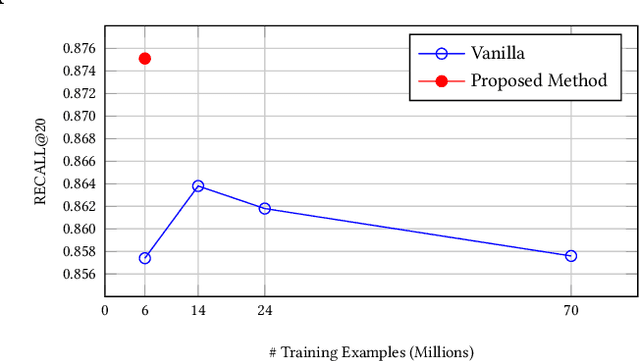

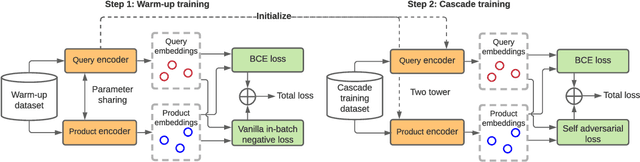
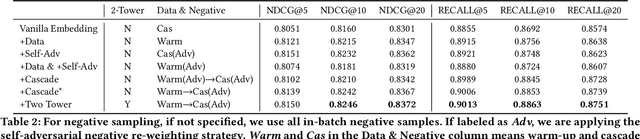
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.
Schema-Aware Deep Graph Convolutional Networks for Heterogeneous Graphs
May 03, 2021

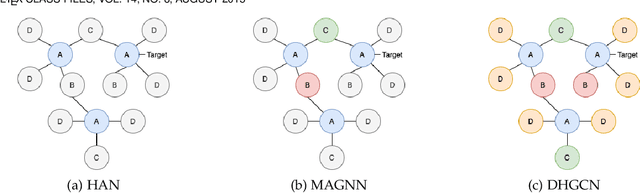

Graph convolutional network (GCN) based approaches have achieved significant progress for solving complex, graph-structured problems. GCNs incorporate the graph structure information and the node (or edge) features through message passing and computes 'deep' node representations. Despite significant progress in the field, designing GCN architectures for heterogeneous graphs still remains an open challenge. Due to the schema of a heterogeneous graph, useful information may reside multiple hops away. A key question is how to perform message passing to incorporate information of neighbors multiple hops away while avoiding the well-known over-smoothing problem in GCNs. To address this question, we propose our GCN framework 'Deep Heterogeneous Graph Convolutional Network (DHGCN)', which takes advantage of the schema of a heterogeneous graph and uses a hierarchical approach to effectively utilize information many hops away. It first computes representations of the target nodes based on their 'schema-derived ego-network' (SEN). It then links the nodes of the same type with various pre-defined metapaths and performs message passing along these links to compute final node representations. Our design choices naturally capture the way a heterogeneous graph is generated from the schema. The experimental results on real and synthetic datasets corroborate the design choice and illustrate the performance gains relative to competing alternatives.
Distant-Supervised Slot-Filling for E-Commerce Queries
Dec 15, 2020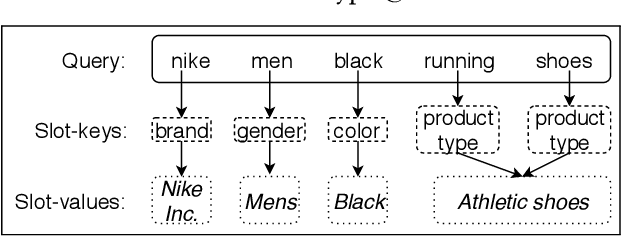
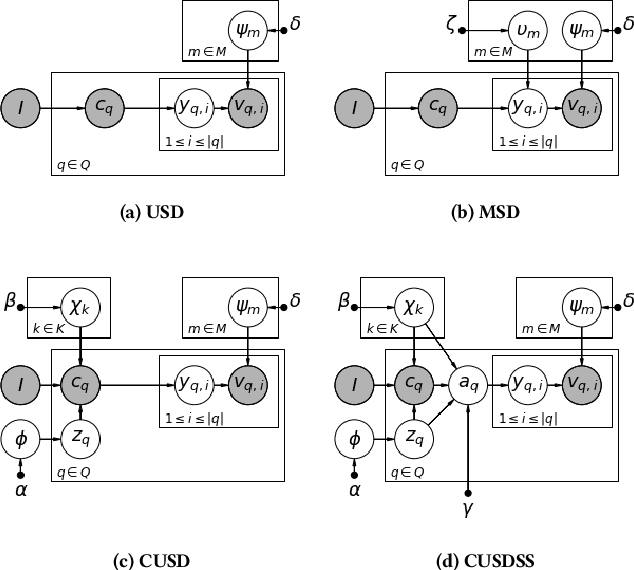
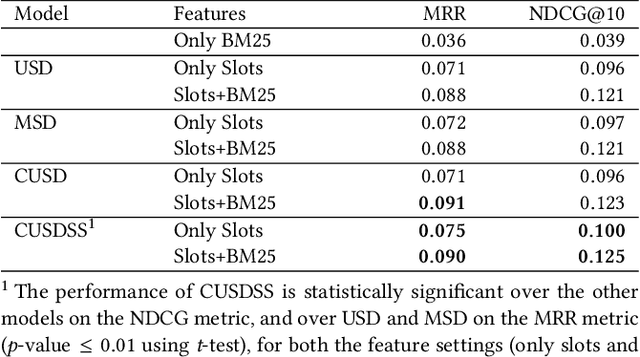
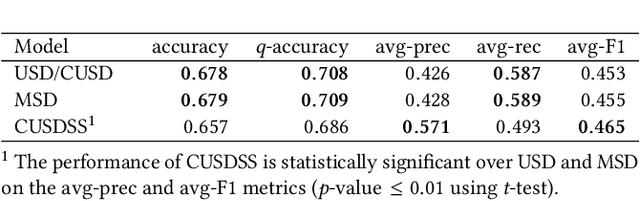
Slot-filling refers to the task of annotating individual terms in a query with the corresponding intended product characteristics (product type, brand, gender, size, color, etc.). These characteristics can then be used by a search engine to return results that better match the query's product intent. Traditional methods for slot-filling require the availability of training data with ground truth slot-annotation information. However, generating such labeled data, especially in e-commerce is expensive and time-consuming because the number of slots increases as new products are added. In this paper, we present distant-supervised probabilistic generative models, that require no manual annotation. The proposed approaches leverage the readily available historical query logs and the purchases that these queries led to, and also exploit co-occurrence information among the slots in order to identify intended product characteristics. We evaluate our approaches by considering how they affect retrieval performance, as well as how well they classify the slots. In terms of retrieval, our approaches achieve better ranking performance (up to 156%) over Okapi BM25. Moreover, our approach that leverages co-occurrence information leads to better performance than the one that does not on both the retrieval and slot classification tasks.
Image Generation Via Minimizing Fréchet Distance in Discriminator Feature Space
Mar 30, 2020
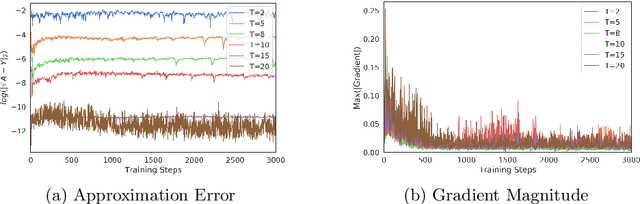
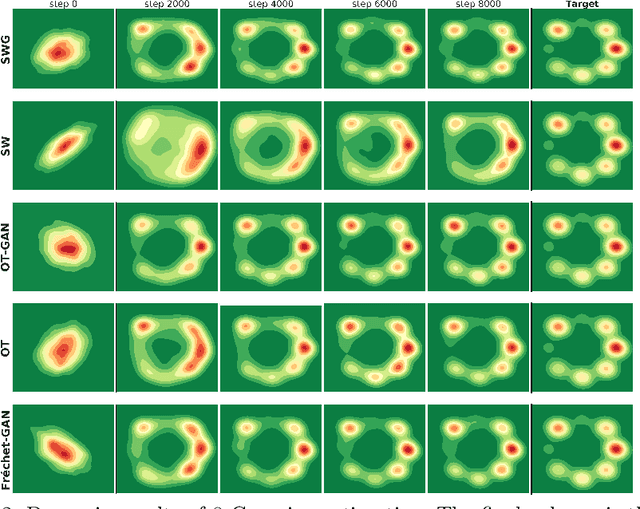
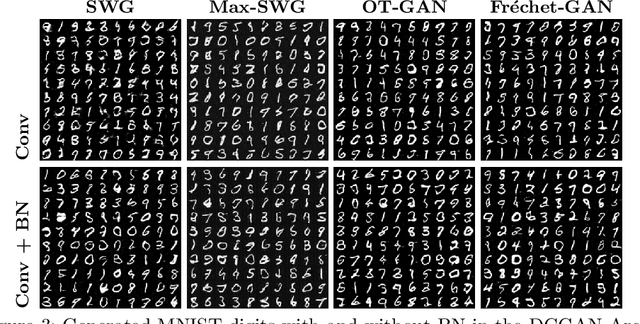
For a given image generation problem, the intrinsic image manifold is often low dimensional. We use the intuition that it is much better to train the GAN generator by minimizing the distributional distance between real and generated images in a small dimensional feature space representing such a manifold than on the original pixel-space. We use the feature space of the GAN discriminator for such a representation. For distributional distance, we employ one of two choices: the Fr\'{e}chet distance or direct optimal transport (OT); these respectively lead us to two new GAN methods: Fr\'{e}chet-GAN and OT-GAN. The idea of employing Fr\'{e}chet distance comes from the success of Fr\'{e}chet Inception Distance as a solid evaluation metric in image generation. Fr\'{e}chet-GAN is attractive in several ways. We propose an efficient, numerically stable approach to calculate the Fr\'{e}chet distance and its gradient. The Fr\'{e}chet distance estimation requires a significantly less computation time than OT; this allows Fr\'{e}chet-GAN to use much larger mini-batch size in training than OT. More importantly, we conduct experiments on a number of benchmark datasets and show that Fr\'{e}chet-GAN (in particular) and OT-GAN have significantly better image generation capabilities than the existing representative primal and dual GAN approaches based on the Wasserstein distance.
Regression via Implicit Models and Optimal Transport Cost Minimization
Mar 03, 2020
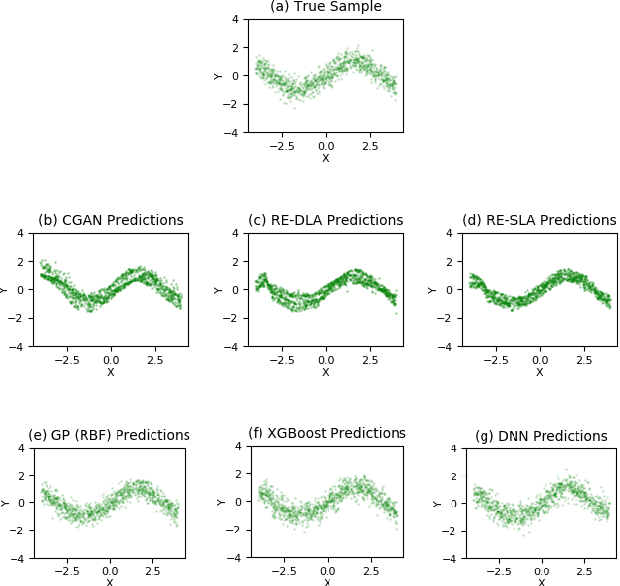
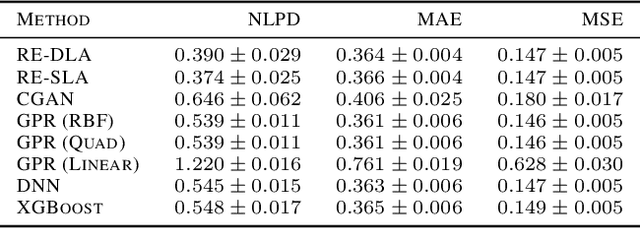
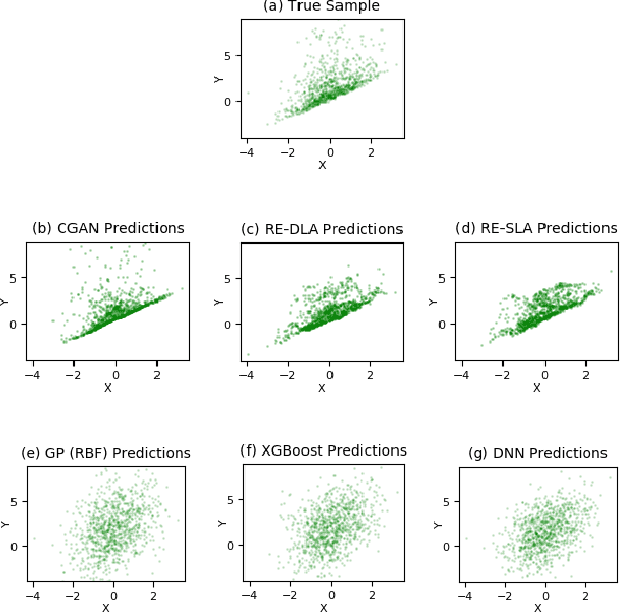
This paper addresses the classic problem of regression, which involves the inductive learning of a map, $y=f(x,z)$, $z$ denoting noise, $f:\mathbb{R}^n\times \mathbb{R}^k \rightarrow \mathbb{R}^m$. Recently, Conditional GAN (CGAN) has been applied for regression and has shown to be advantageous over the other standard approaches like Gaussian Process Regression, given its ability to implicitly model complex noise forms. However, the current CGAN implementation for regression uses the classical generator-discriminator architecture with the minimax optimization approach, which is notorious for being difficult to train due to issues like training instability or failure to converge. In this paper, we take another step towards regression models that implicitly model the noise, and propose a solution which directly optimizes the optimal transport cost between the true probability distribution $p(y|x)$ and the estimated distribution $\hat{p}(y|x)$ and does not suffer from the issues associated with the minimax approach. On a variety of synthetic and real-world datasets, our proposed solution achieves state-of-the-art results. The code accompanying this paper is available at "https://github.com/gurdaspuriya/ot_regression".
Image Hashing by Minimizing Independent Relaxed Wasserstein Distance
Feb 29, 2020
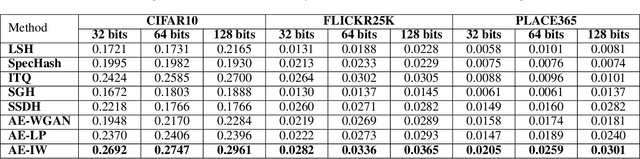
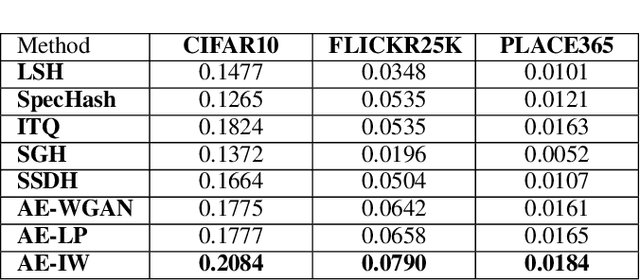
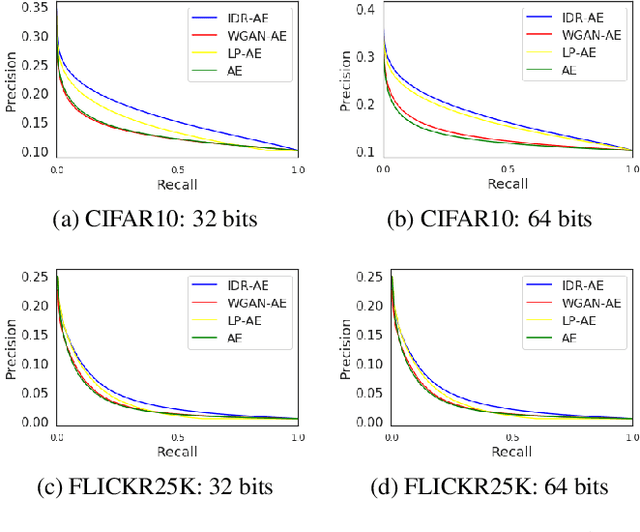
Image hashing is a fundamental problem in the computer vision domain with various challenges, primarily, in terms of efficiency and effectiveness. Existing hashing methods lack a principled characterization of the goodness of the hash codes and a principled approach to learn the discrete hash functions that are being optimized in the continuous space. Adversarial autoencoders are shown to be able to implicitly learn a robust hash function that generates hash codes which are balanced and have low-quantization error. However, the existing adversarial autoencoders for hashing are too inefficient to be employed for large-scale image retrieval applications because of the minmax optimization procedure. In this paper, we propose an Independent Relaxed Wasserstein Autoencoder, which presents a novel, efficient hashing method that can implicitly learn the optimal hash function by directly training the adversarial autoencoder without any discriminator/critic. Our method is an order-of-magnitude more efficient and has a much lower sample complexity than the Optimal Transport formulation of the Wasserstein distance. The proposed method outperforms the current state-of-the-art image hashing methods for the retrieval task on several prominent image collections.