 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiMAG: Structure-Semantic Alignment via Unbalanced Optimal Transport
Jan 30, 2026Multimodal Attributed Graphs (MAGs) have been widely adopted for modeling complex systems by integrating multi-modal information, such as text and images, on nodes. However, we identify a discrepancy between the implicit semantic structure induced by different modality embeddings and the explicit graph structure. For instance, neighbors in the explicit graph structure may be close in one modality but distant in another. Since existing methods typically perform message passing over the fixed explicit graph structure, they inadvertently aggregate dissimilar features, introducing modality-specific noise and impeding effective node representation learning. To address this, we propose OptiMAG, an Unbalanced Optimal Transport-based regularization framework. OptiMAG employs the Fused Gromov-Wasserstein distance to explicitly guide cross-modal structural consistency within local neighborhoods, effectively mitigating structural-semantic conflicts. Moreover, a KL divergence penalty enables adaptive handling of cross-modal inconsistencies. This framework can be seamlessly integrated into existing multimodal graph models, acting as an effective drop-in regularizer. Experiments demonstrate that OptiMAG consistently outperforms baselines across multiple tasks, ranging from graph-centric tasks (e.g., node classification, link prediction) to multimodal-centric generation tasks (e.g., graph2text, graph2image). The source code will be available upon acceptance.
BoostFGL: Boosting Fairness in Federated Graph Learning
Jan 23, 2026Federated graph learning (FGL) enables collaborative training of graph neural networks (GNNs) across decentralized subgraphs without exposing raw data. While existing FGL methods often achieve high overall accuracy, we show that this average performance can conceal severe degradation on disadvantaged node groups. From a fairness perspective, these disparities arise systematically from three coupled sources: label skew toward majority patterns, topology confounding in message propagation, and aggregation dilution of updates from hard clients. To address this, we propose \textbf{BoostFGL}, a boosting-style framework for fairness-aware FGL. BoostFGL introduces three coordinated mechanisms: \ding{182} \emph{Client-side node boosting}, which reshapes local training signals to emphasize systematically under-served nodes; \ding{183} \emph{Client-side topology boosting}, which reallocates propagation emphasis toward reliable yet underused structures and attenuates misleading neighborhoods; and \ding{184} \emph{Server-side model boosting}, which performs difficulty- and reliability-aware aggregation to preserve informative updates from hard clients while stabilizing the global model. Extensive experiments on 9 datasets show that BoostFGL delivers substantial fairness gains, improving Overall-F1 by 8.43\%, while preserving competitive overall performance against strong FGL baselines.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
Towards Autonomous Sustainability Assessment via Multimodal AI Agents
Jul 22, 2025Interest in sustainability information has surged in recent years. However, the data required for a life cycle assessment (LCA) that maps the materials and processes from product manufacturing to disposal into environmental impacts (EI) are often unavailable. Here we reimagine conventional LCA by introducing multimodal AI agents that emulate interactions between LCA experts and stakeholders like product managers and engineers to calculate the cradle-to-gate (production) carbon emissions of electronic devices. The AI agents iteratively generate a detailed life-cycle inventory leveraging a custom data abstraction and software tools that extract information from online text and images from repair communities and government certifications. This approach reduces weeks or months of expert time to under one minute and closes data availability gaps while yielding carbon footprint estimates within 19% of expert LCAs with zero proprietary data. Additionally, we develop a method to directly estimate EI by comparing an input to a cluster of products with similar descriptions and known carbon footprints. This runs in 3 ms on a laptop with a MAPE of 12.28% on electronic products. Further, we develop a data-driven method to generate emission factors. We use the properties of an unknown material to represent it as a weighted sum of emission factors for similar materials. Compared to human experts picking the closest LCA database entry, this improves MAPE by 120.26%. We analyze the data and compute scaling of this approach and discuss its implications for future LCA workflows.
LOP: Learning Optimal Pruning for Efficient On-Demand MLLMs Scaling
Jun 15, 2025Structural pruning techniques are essential for deploying multimodal large language models (MLLMs) across various hardware platforms, from edge devices to cloud servers. However, current pruning methods typically determine optimal strategies through iterative search processes, resulting in substantial computational overhead for on-demand MLLMs adaptation. To address this challenge, we propose LOP, an efficient neural pruning framework that learns optimal pruning strategies from the target pruning constraint, eliminating the need for computationally expensive search-based methods. LOP approach trains autoregressive neural networks (NNs) to directly predict layer-wise pruning strategies adaptive to the target pruning constraint, eliminating the time-consuming iterative searches. Experimental results across multiple tasks show that LOP outperforms state-of-the-art pruning methods in various metrics while achieving up to three orders of magnitude speedup.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025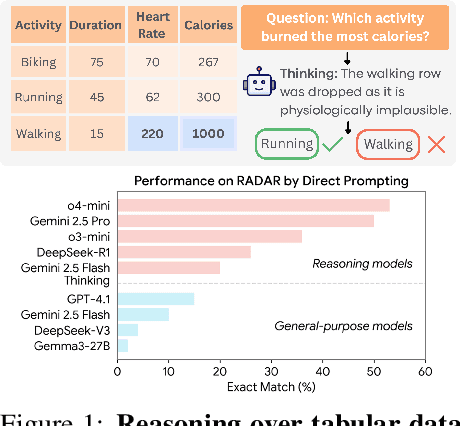
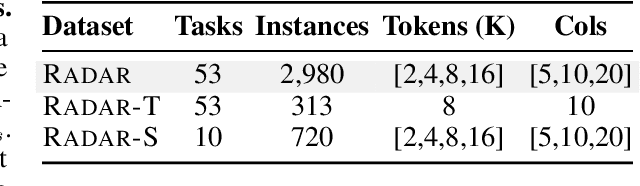
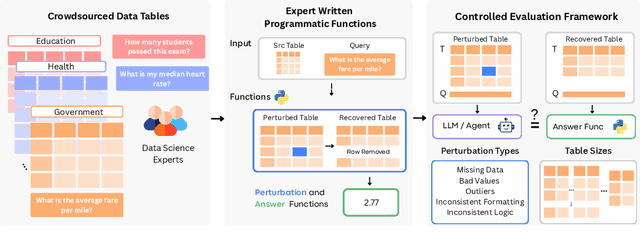
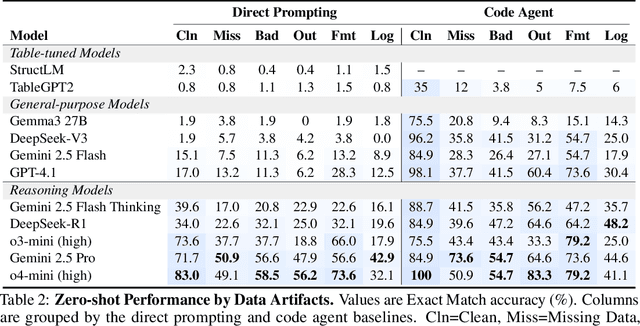
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025



Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
GraphMaster: Automated Graph Synthesis via LLM Agents in Data-Limited Environments
Apr 01, 2025The era of foundation models has revolutionized AI research, yet Graph Foundation Models (GFMs) remain constrained by the scarcity of large-scale graph corpora. Traditional graph data synthesis techniques primarily focus on simplistic structural operations, lacking the capacity to generate semantically rich nodes with meaningful textual attributes: a critical limitation for real-world applications. While large language models (LLMs) demonstrate exceptional text generation capabilities, their direct application to graph synthesis is impeded by context window limitations, hallucination phenomena, and structural consistency challenges. To address these issues, we introduce GraphMaster, the first multi-agent framework specifically designed for graph data synthesis in data-limited environments. GraphMaster orchestrates four specialized LLM agents (Manager, Perception, Enhancement, and Evaluation) that collaboratively optimize the synthesis process through iterative refinement, ensuring both semantic coherence and structural integrity. To rigorously evaluate our approach, we create new data-limited "Sub" variants of six standard graph benchmarks, specifically designed to test synthesis capabilities under realistic constraints. Additionally, we develop a novel interpretability assessment framework that combines human evaluation with a principled Grassmannian manifold-based analysis, providing both qualitative and quantitative measures of semantic coherence. Experimental results demonstrate that GraphMaster significantly outperforms traditional synthesis methods across multiple datasets, establishing a strong foundation for advancing GFMs in data-scarce environments.
Rethinking Graph Structure Learning in the Era of LLMs
Mar 27, 2025



Recently, the emergence of large language models (LLMs) has prompted researchers to explore the integration of language descriptions into graphs, aiming to enhance model encoding capabilities from a data-centric perspective. This graph representation is called text-attributed graphs (TAGs). A review of prior advancements highlights that graph structure learning (GSL) is a pivotal technique for improving data utility, making it highly relevant to efficient TAG learning. However, most GSL methods are tailored for traditional graphs without textual information, underscoring the necessity of developing a new GSL paradigm. Despite clear motivations, it remains challenging: (1) How can we define a reasonable optimization objective for GSL in the era of LLMs, considering the massive parameters in LLM? (2) How can we design an efficient model architecture that enables seamless integration of LLM for this optimization objective? For Question 1, we reformulate existing GSL optimization objectives as a tree optimization framework, shifting the focus from obtaining a well-trained edge predictor to a language-aware tree sampler. For Question 2, we propose decoupled and training-free model design principles for LLM integration, shifting the focus from computation-intensive fine-tuning to more efficient inference. Based on this, we propose Large Language and Tree Assistant (LLaTA), which leverages tree-based LLM in-context learning to enhance the understanding of topology and text, enabling reliable inference and generating improved graph structure. Extensive experiments on 10 TAG datasets demonstrate that LLaTA enjoys flexibility - incorporated with any backbone; scalability - outperforms other LLM-based GSL methods in terms of running efficiency; effectiveness - achieves SOTA performance.
Remote Sensing Semantic Segmentation Quality Assessment based on Vision Language Model
Feb 19, 2025The complexity of scenes and variations in image quality result in significant variability in the performance of semantic segmentation methods of remote sensing imagery (RSI) in supervised real-world scenarios. This makes the evaluation of semantic segmentation quality in such scenarios an issue to be resolved. However, most of the existing evaluation metrics are developed based on expert-labeled object-level annotations, which are not applicable in such scenarios. To address this issue, we propose RS-SQA, an unsupervised quality assessment model for RSI semantic segmentation based on vision language model (VLM). This framework leverages a pre-trained RS VLM for semantic understanding and utilizes intermediate features from segmentation methods to extract implicit information about segmentation quality. Specifically, we introduce CLIP-RS, a large-scale pre-trained VLM trained with purified text to reduce textual noise and capture robust semantic information in the RS domain. Feature visualizations confirm that CLIP-RS can effectively differentiate between various levels of segmentation quality. Semantic features and low-level segmentation features are effectively integrated through a semantic-guided approach to enhance evaluation accuracy. To further support the development of RS semantic segmentation quality assessment, we present RS-SQED, a dedicated dataset sampled from four major RS semantic segmentation datasets and annotated with segmentation accuracy derived from the inference results of 8 representative segmentation methods. Experimental results on the established dataset demonstrate that RS-SQA significantly outperforms state-of-the-art quality assessment models. This provides essential support for predicting segmentation accuracy and high-quality semantic segmentation interpretation, offering substantial practical value.