 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Arena: Iterative Optimization via Hardware Feedback
Jun 15, 2026Embedded devices from wildlife monitoring stations to clinical wearables require local AI inference due to latency, communication, or privacy constraints. Optimizing models for heterogeneous microcontrollers (MCUs) requires simultaneously satisfying hard physical constraints on memory, power, and temperature while preserving accuracy, a multidimensional optimization that is today performed manually by experts. We ask whether an LLM agent can autonomously navigate this complex, multi-turn pipeline guided by real hardware feedback, and introduce a hardware-in-the-loop agent arena in which the agent iteratively refines both model and firmware -- compiling, flashing, and measuring on real hardware -- to enable closed-loop optimization. Frontier models, including Claude Opus 4.7 and Gemini 3.1 Pro, fail entirely without hardware feedback (0% deployment success), whereas our hardware-in-the-loop formulation achieves the first successful deployment within three iterations and can surpass human expert results within seven. This agentic co-optimization achieves 250x compression for vision models with <3.3% accuracy loss and 400x for audio with <6% Feature Error Rate loss, enabling battery-free operation on a commercial MCU via solar harvesting. We demonstrate practical impact in two real-world systems: an elk-detection camera trap (96.7% accuracy) and a phonetic-transcription wearable (8.44% FER) for child development research.
Towards Autonomous Sustainability Assessment via Multimodal AI Agents
Jul 22, 2025



Interest in sustainability information has surged in recent years. However, the data required for a life cycle assessment (LCA) that maps the materials and processes from product manufacturing to disposal into environmental impacts (EI) are often unavailable. Here we reimagine conventional LCA by introducing multimodal AI agents that emulate interactions between LCA experts and stakeholders like product managers and engineers to calculate the cradle-to-gate (production) carbon emissions of electronic devices. The AI agents iteratively generate a detailed life-cycle inventory leveraging a custom data abstraction and software tools that extract information from online text and images from repair communities and government certifications. This approach reduces weeks or months of expert time to under one minute and closes data availability gaps while yielding carbon footprint estimates within 19% of expert LCAs with zero proprietary data. Additionally, we develop a method to directly estimate EI by comparing an input to a cluster of products with similar descriptions and known carbon footprints. This runs in 3 ms on a laptop with a MAPE of 12.28% on electronic products. Further, we develop a data-driven method to generate emission factors. We use the properties of an unknown material to represent it as a weighted sum of emission factors for similar materials. Compared to human experts picking the closest LCA database entry, this improves MAPE by 120.26%. We analyze the data and compute scaling of this approach and discuss its implications for future LCA workflows.
IMUTube: Automatic extraction of virtual on-body accelerometry from video for human activity recognition
May 29, 2020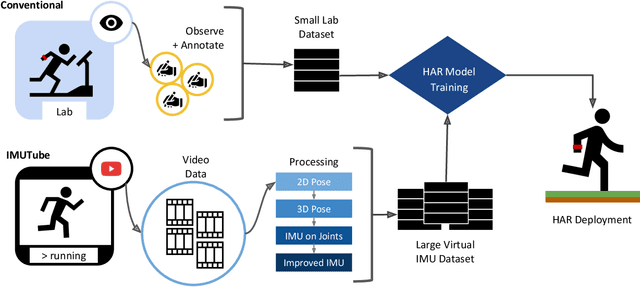

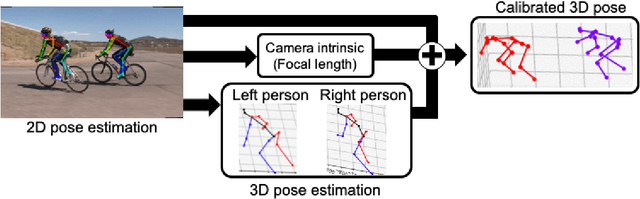

The lack of large-scale, labeled data sets impedes progress in developing robust and generalized predictive models for on-body sensor-based human activity recognition (HAR). Labeled data in human activity recognition is scarce and hard to come by, as sensor data collection is expensive, and the annotation is time-consuming and error-prone. To address this problem, we introduce IMUTube, an automated processing pipeline that integrates existing computer vision and signal processing techniques to convert videos of human activity into virtual streams of IMU data. These virtual IMU streams represent accelerometry at a wide variety of locations on the human body. We show how the virtually-generated IMU data improves the performance of a variety of models on known HAR datasets. Our initial results are very promising, but the greater promise of this work lies in a collective approach by the computer vision, signal processing, and activity recognition communities to extend this work in ways that we outline. This should lead to on-body, sensor-based HAR becoming yet another success story in large-dataset breakthroughs in recognition.