 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025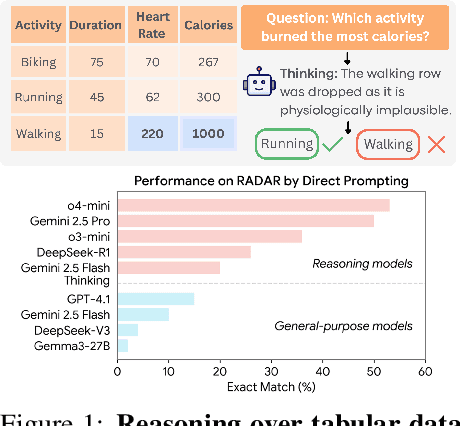
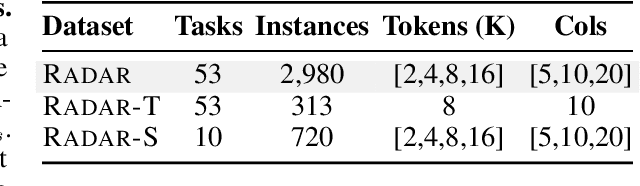
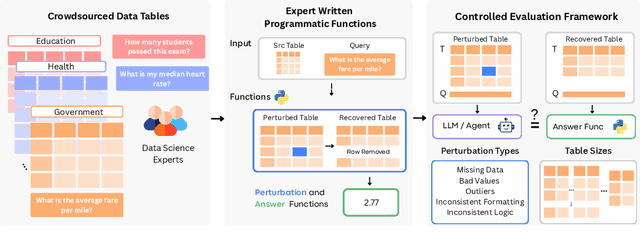
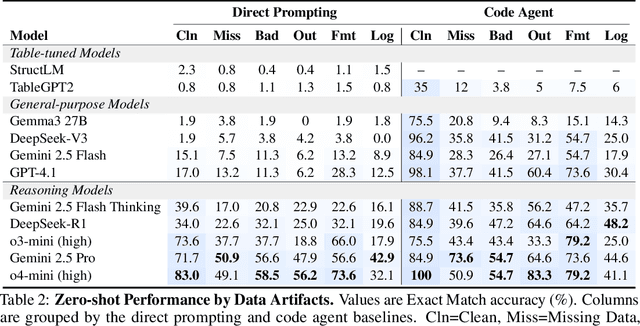
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
Relationships are Complicated! An Analysis of Relationships Between Datasets on the Web
Aug 26, 2024The Web today has millions of datasets, and the number of datasets continues to grow at a rapid pace. These datasets are not standalone entities; rather, they are intricately connected through complex relationships. Semantic relationships between datasets provide critical insights for research and decision-making processes. In this paper, we study dataset relationships from the perspective of users who discover, use, and share datasets on the Web: what relationships are important for different tasks? What contextual information might users want to know? We first present a comprehensive taxonomy of relationships between datasets on the Web and map these relationships to user tasks performed during dataset discovery. We develop a series of methods to identify these relationships and compare their performance on a large corpus of datasets generated from Web pages with schema.org markup. We demonstrate that machine-learning based methods that use dataset metadata achieve multi-class classification accuracy of 90%. Finally, we highlight gaps in available semantic markup for datasets and discuss how incorporating comprehensive semantics can facilitate the identification of dataset relationships. By providing a comprehensive overview of dataset relationships at scale, this paper sets a benchmark for future research.