 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETC: Extreme Token Compression via Task-aware Visual Information Distillation in VLMs
May 30, 2026In Vision-Language Models (VLMs), high-resolution images produce a large number of visual tokens, resulting in high computational costs and KV-cache overhead during inference. To address this problem, we propose an Extreme Token Compression (ETC) framework that minimizes task loss when reducing the number of input tokens based on the principle of variational information distillation. Specifically, from an information-theoretic perspective, we show that minimizing task loss requires the compact representation to preserve the instruction-aware sufficient statistic of the task-relevant visual information for prediction. In practice, ETC leverages text-to-image cross-attention to weight the original visual features to approximate the latent instruction-aware predictive statistic. Moreover, ETC introduces a variational information distillation, enabling the compact representation to preserve the essential information to recover this predictive statistic. Experiments on LLaVA-1.5-7B and Qwen3-VL-2B show that ETC remains effective even under single-token compression, substantially reducing KV-cache overhead while retaining strong task performance.
LOP: Learning Optimal Pruning for Efficient On-Demand MLLMs Scaling
Jun 15, 2025Structural pruning techniques are essential for deploying multimodal large language models (MLLMs) across various hardware platforms, from edge devices to cloud servers. However, current pruning methods typically determine optimal strategies through iterative search processes, resulting in substantial computational overhead for on-demand MLLMs adaptation. To address this challenge, we propose LOP, an efficient neural pruning framework that learns optimal pruning strategies from the target pruning constraint, eliminating the need for computationally expensive search-based methods. LOP approach trains autoregressive neural networks (NNs) to directly predict layer-wise pruning strategies adaptive to the target pruning constraint, eliminating the time-consuming iterative searches. Experimental results across multiple tasks show that LOP outperforms state-of-the-art pruning methods in various metrics while achieving up to three orders of magnitude speedup.
RSFAKE-1M: A Large-Scale Dataset for Detecting Diffusion-Generated Remote Sensing Forgeries
May 29, 2025



Detecting forged remote sensing images is becoming increasingly critical, as such imagery plays a vital role in environmental monitoring, urban planning, and national security. While diffusion models have emerged as the dominant paradigm for image generation, their impact on remote sensing forgery detection remains underexplored. Existing benchmarks primarily target GAN-based forgeries or focus on natural images, limiting progress in this critical domain. To address this gap, we introduce RSFAKE-1M, a large-scale dataset of 500K forged and 500K real remote sensing images. The fake images are generated by ten diffusion models fine-tuned on remote sensing data, covering six generation conditions such as text prompts, structural guidance, and inpainting. This paper presents the construction of RSFAKE-1M along with a comprehensive experimental evaluation using both existing detectors and unified baselines. The results reveal that diffusion-based remote sensing forgeries remain challenging for current methods, and that models trained on RSFAKE-1M exhibit notably improved generalization and robustness. Our findings underscore the importance of RSFAKE-1M as a foundation for developing and evaluating next-generation forgery detection approaches in the remote sensing domain. The dataset and other supplementary materials are available at https://huggingface.co/datasets/TZHSW/RSFAKE/.
Training-Free Reasoning and Reflection in MLLMs
May 22, 2025Recent advances in Reasoning LLMs (e.g., DeepSeek-R1 and OpenAI-o1) have showcased impressive reasoning capabilities via reinforcement learning. However, extending these capabilities to Multimodal LLMs (MLLMs) is hampered by the prohibitive costs of retraining and the scarcity of high-quality, verifiable multimodal reasoning datasets. This paper introduces FRANK Model, a training-FRee ANd r1-liKe MLLM that imbues off-the-shelf MLLMs with reasoning and reflection abilities, without any gradient updates or extra supervision. Our key insight is to decouple perception and reasoning across MLLM decoder layers. Specifically, we observe that compared to the deeper decoder layers, the shallow decoder layers allocate more attention to visual tokens, while the deeper decoder layers concentrate on textual semantics. This observation motivates a hierarchical weight merging approach that combines a visual-pretrained MLLM with a reasoning-specialized LLM. To this end, we propose a layer-wise, Taylor-derived closed-form fusion mechanism that integrates reasoning capacity into deep decoder layers while preserving visual grounding in shallow decoder layers. Extensive experiments on challenging multimodal reasoning benchmarks demonstrate the effectiveness of our approach. On the MMMU benchmark, our model FRANK-38B achieves an accuracy of 69.2, outperforming the strongest baseline InternVL2.5-38B by +5.3, and even surpasses the proprietary GPT-4o model. Our project homepage is at: http://iip.whu.edu.cn/frank/index.html
LongCaptioning: Unlocking the Power of Long Caption Generation in Large Multimodal Models
Feb 21, 2025Large multimodal models (LMMs) have shown remarkable performance in video understanding tasks and can even process videos longer than one hour. However, despite their ability to handle long inputs, generating outputs with corresponding levels of richness remains a challenge. In this paper, we explore the issue of long outputs in LMMs using video captioning as a proxy task, and we find that open-source LMMs struggle to consistently generate outputs exceeding about 300 words. Through controlled experiments, we find that the scarcity of paired examples with long-captions during training is the primary factor limiting the model's output length. However, manually annotating long-caption examples is time-consuming and expensive. To address this, we propose the LongCaption-Agent, a framework that synthesizes long caption data by aggregating multi-level descriptions. Using LongCaption-Agent, we curated a new long-caption dataset, LongCaption-10K. We also develop LongCaption-Bench, a benchmark designed to comprehensively evaluate the quality of long captions generated by LMMs. By incorporating LongCaption-10K into training, we enable LMMs to generate captions exceeding 1,000 words, while maintaining high output quality. In LongCaption-Bench, our 8B parameter model achieved state-of-the-art performance, even surpassing larger proprietary models. We will release the dataset and code after publication.
Remote Sensing Semantic Segmentation Quality Assessment based on Vision Language Model
Feb 19, 2025The complexity of scenes and variations in image quality result in significant variability in the performance of semantic segmentation methods of remote sensing imagery (RSI) in supervised real-world scenarios. This makes the evaluation of semantic segmentation quality in such scenarios an issue to be resolved. However, most of the existing evaluation metrics are developed based on expert-labeled object-level annotations, which are not applicable in such scenarios. To address this issue, we propose RS-SQA, an unsupervised quality assessment model for RSI semantic segmentation based on vision language model (VLM). This framework leverages a pre-trained RS VLM for semantic understanding and utilizes intermediate features from segmentation methods to extract implicit information about segmentation quality. Specifically, we introduce CLIP-RS, a large-scale pre-trained VLM trained with purified text to reduce textual noise and capture robust semantic information in the RS domain. Feature visualizations confirm that CLIP-RS can effectively differentiate between various levels of segmentation quality. Semantic features and low-level segmentation features are effectively integrated through a semantic-guided approach to enhance evaluation accuracy. To further support the development of RS semantic segmentation quality assessment, we present RS-SQED, a dedicated dataset sampled from four major RS semantic segmentation datasets and annotated with segmentation accuracy derived from the inference results of 8 representative segmentation methods. Experimental results on the established dataset demonstrate that RS-SQA significantly outperforms state-of-the-art quality assessment models. This provides essential support for predicting segmentation accuracy and high-quality semantic segmentation interpretation, offering substantial practical value.
Visual Context Window Extension: A New Perspective for Long Video Understanding
Sep 30, 2024Large Multimodal Models (LMMs) have demonstrated impressive performance in short video understanding tasks but face great challenges when applied to long video understanding. In contrast, Large Language Models (LLMs) exhibit outstanding capabilities in modeling long texts. Existing work attempts to address this issue by introducing long video-text pairs during training. However, these approaches require substantial computational and data resources. In this paper, we tackle the challenge of long video understanding from the perspective of context windows, aiming to apply LMMs to long video tasks without retraining on long video datasets. We first conduct an in-depth analysis of why pretrained LMMs struggle to understand lengthy video content, identifying that discrepancies between visual and language modalities lead to different context windows for visual and language tokens, making it difficult to directly extend the visual tokens to match the language context window. Based on this, we propose to adapt LMMs for long video understanding tasks by extending the visual context window, eliminating the need for retraining on large scalelong video datasets. To further mitigate the significant memory consumption caused by long sequences, we introduce a progressive pooling inference strategy that selectively adjusts the spatial resolution of frame embeddings, reducing the number of visual tokens while retaining important spatial information. Across multiple long video understanding benchmarks, our method consistently improves the performance as the number of video frames increases. On the MLVU benchmark, our method outperforms GPT-4o, even though our model size is only 7B. Additionally, in the 256-frame setting, our method reduces memory usage by approximately 45% compared to the baseline, without introducing any performance loss.
Improving Generalization of Image Captioning with Unsupervised Prompt Learning
Aug 05, 2023Pretrained visual-language models have demonstrated impressive zero-shot abilities in image captioning, when accompanied by hand-crafted prompts. Meanwhile, hand-crafted prompts utilize human prior knowledge to guide the model. However, due to the diversity between different domains, such hand-crafted prompt that provide invariant prior knowledge may result in mode collapse for some domains. Some researches attempted to incorporate expert knowledge and instruction datasets, but the results were costly and led to hallucinations. In this paper, we propose an unsupervised prompt learning method to improve Generalization of Image Captioning (GeneIC), which learns a domain-specific prompt vector for the target domain without requiring annotated data. GeneIC aligns visual and language modalities with a pre-trained Contrastive Language-Image Pre-Training (CLIP) model, thus optimizing the domain-specific prompt vector from two aspects: attribute and semantic consistency. Specifically, GeneIC first generates attribute-transferred images with differing attributes, while retaining semantic similarity with original images. Then, GeneIC uses CLIP to measure the similarity between the images and the generated sentences. By exploring the variable and invariant features in the original images and attribute-transferred images, attribute consistency constrains the attribute change direction of both images and sentences to learn domain-specific knowledge. The semantic consistency directly measures the similarity between the generated sentences and images to ensure the accuracy and comprehensiveness of the generated sentences. Consequently, GeneIC only optimizes the prompt vectors, which effectively retains the knowledge in the large model and introduces domain-specific knowledge.
Exploiting Cross-Modal Prediction and Relation Consistency for Semi-Supervised Image Captioning
Oct 28, 2021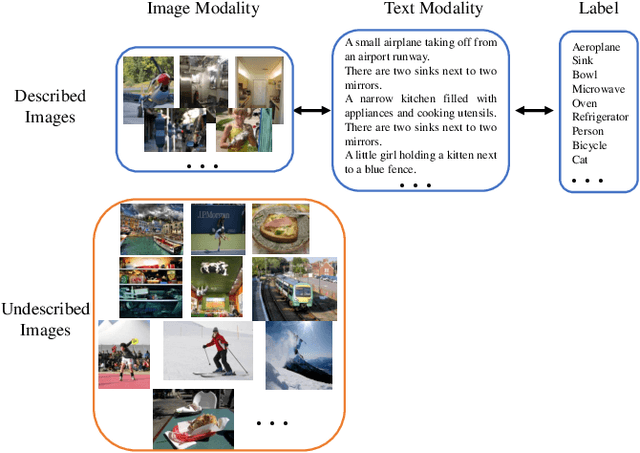
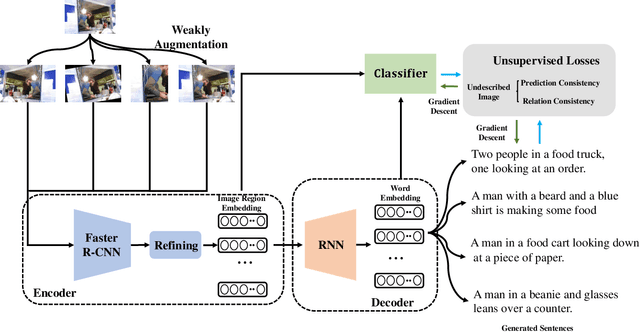
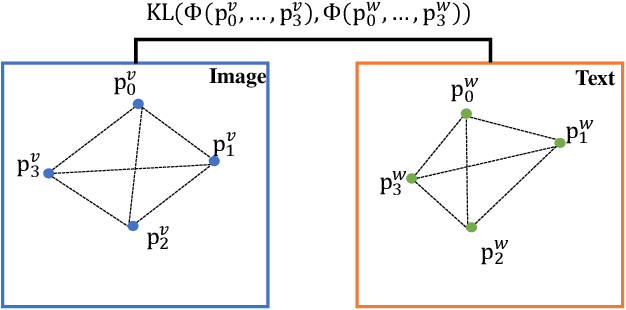
The task of image captioning aims to generate captions directly from images via the automatically learned cross-modal generator. To build a well-performing generator, existing approaches usually need a large number of described images, which requires a huge effects on manual labeling. However, in real-world applications, a more general scenario is that we only have limited amount of described images and a large number of undescribed images. Therefore, a resulting challenge is how to effectively combine the undescribed images into the learning of cross-modal generator. To solve this problem, we propose a novel image captioning method by exploiting the Cross-modal Prediction and Relation Consistency (CPRC), which aims to utilize the raw image input to constrain the generated sentence in the commonly semantic space. In detail, considering that the heterogeneous gap between modalities always leads to the supervision difficulty of using the global embedding directly, CPRC turns to transform both the raw image and corresponding generated sentence into the shared semantic space, and measure the generated sentence from two aspects: 1) Prediction consistency. CPRC utilizes the prediction of raw image as soft label to distill useful supervision for the generated sentence, rather than employing the traditional pseudo labeling; 2) Relation consistency. CPRC develops a novel relation consistency between augmented images and corresponding generated sentences to retain the important relational knowledge. In result, CPRC supervises the generated sentence from both the informativeness and representativeness perspectives, and can reasonably use the undescribed images to learn a more effective generator under the semi-supervised scenario.