 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Accelerating Neural Architecture Search with Training-Free and Theory-Grounded Metrics
Aug 26, 2021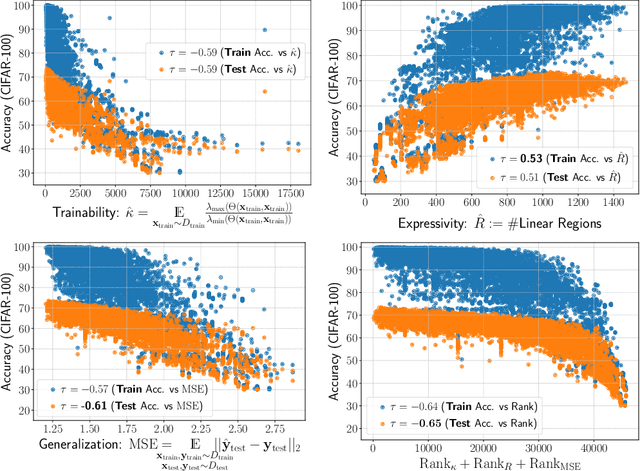

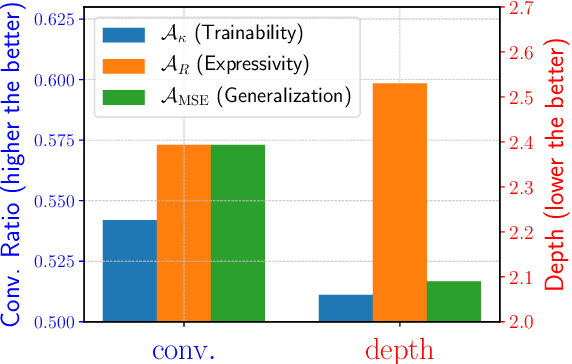
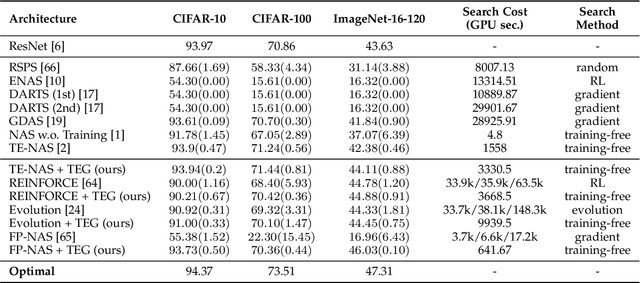
This work targets designing a principled and unified training-free framework for Neural Architecture Search (NAS), with high performance, low cost, and in-depth interpretation. NAS has been explosively studied to automate the discovery of top-performer neural networks, but suffers from heavy resource consumption and often incurs search bias due to truncated training or approximations. Recent NAS works start to explore indicators that can predict a network's performance without training. However, they either leveraged limited properties of deep networks, or the benefits of their training-free indicators are not applied to more extensive search methods. By rigorous correlation analysis, we present a unified framework to understand and accelerate NAS, by disentangling "TEG" characteristics of searched networks - Trainability, Expressivity, Generalization - all assessed in a training-free manner. The TEG indicators could be scaled up and integrated with various NAS search methods, including both supernet and single-path approaches. Extensive studies validate the effective and efficient guidance from our TEG-NAS framework, leading to both improved search accuracy and over 2.3x reduction in search time cost. Moreover, we visualize search trajectories on three landscapes of "TEG" characteristics, observing that while a good local minimum is easier to find on NAS-Bench-201 given its simple topology, balancing "TEG" characteristics is much harder on the DARTS search space due to its complex landscape geometry. Our code is available at https://github.com/VITA-Group/TEGNAS.
Multiscale Vision Transformers
Apr 22, 2021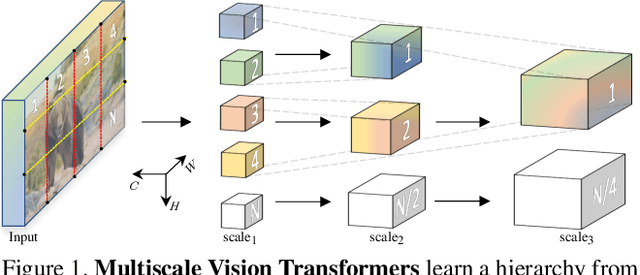

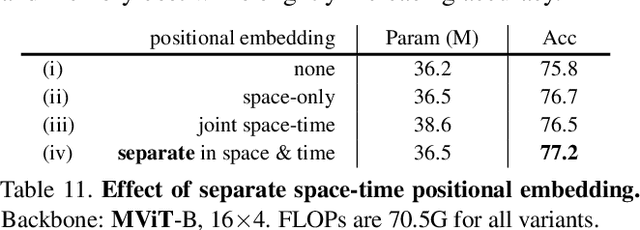
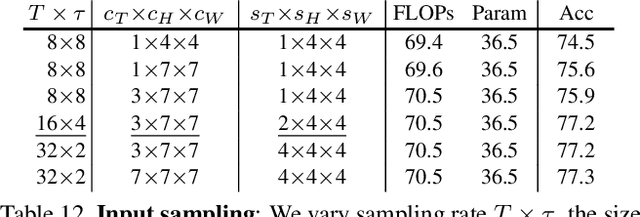
We present Multiscale Vision Transformers (MViT) for video and image recognition, by connecting the seminal idea of multiscale feature hierarchies with transformer models. Multiscale Transformers have several channel-resolution scale stages. Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution. This creates a multiscale pyramid of features with early layers operating at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features. We evaluate this fundamental architectural prior for modeling the dense nature of visual signals for a variety of video recognition tasks where it outperforms concurrent vision transformers that rely on large scale external pre-training and are 5-10x more costly in computation and parameters. We further remove the temporal dimension and apply our model for image classification where it outperforms prior work on vision transformers. Code is available at: https://github.com/facebookresearch/SlowFast
FP-NAS: Fast Probabilistic Neural Architecture Search
Nov 24, 2020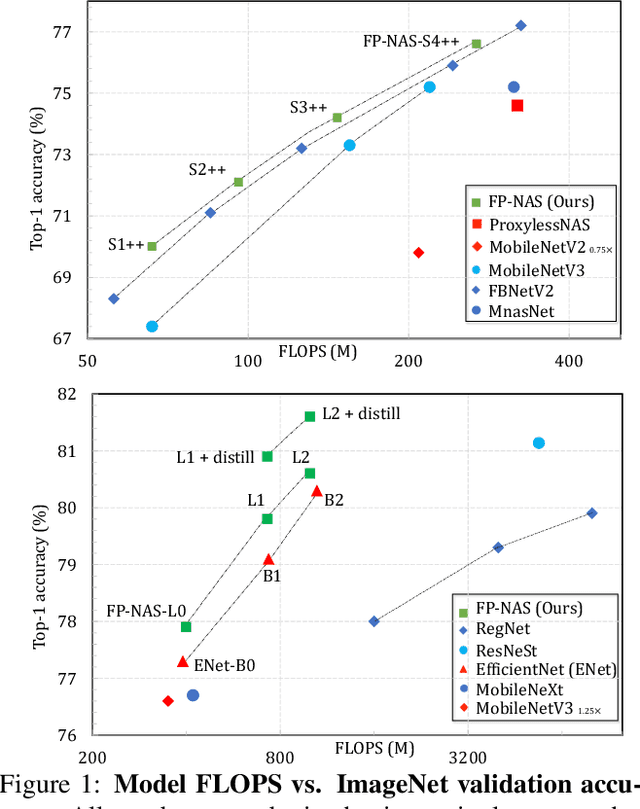
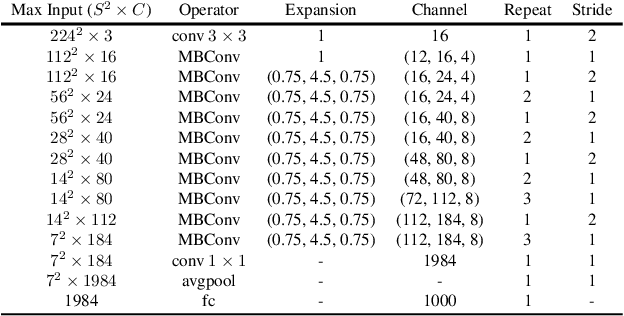
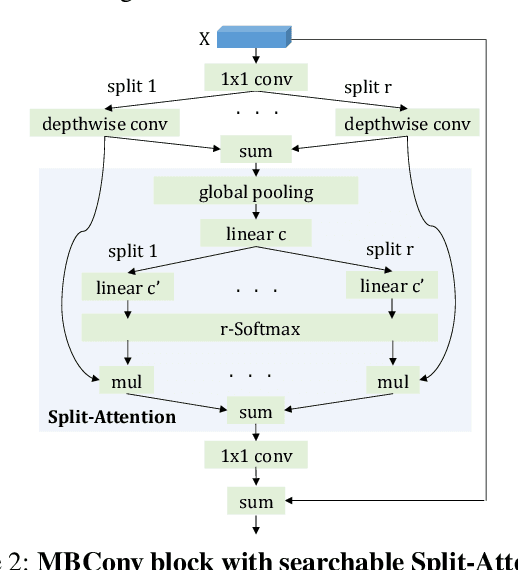

Differential Neural Architecture Search (NAS) requires all layer choices to be held in memory simultaneously; this limits the size of both search space and final architecture. In contrast, Probabilistic NAS, such as PARSEC, learns a distribution over high-performing architectures, and uses only as much memory as needed to train a single model. Nevertheless, it needs to sample many architectures, making it computationally expensive for searching in an extensive space. To solve these problems, we propose a sampling method adaptive to the distribution entropy, drawing more samples to encourage explorations at the beginning, and reducing samples as learning proceeds. Furthermore, to search fast in the multi-variate space, we propose a coarse-to-fine strategy by using a factorized distribution at the beginning which can reduce the number of architecture parameters by over an order of magnitude.We call this method Fast Probabilistic NAS (FP-NAS). Compared with PARSEC, it can sample 64% fewer architectures and search 2.1x faster. Compared with FBNetV2, FP-NAS is 1.9x - 3.6x faster, and the searched models outperform FBNetV2 models on ImageNet. FP-NAS allows us to expand the giant FBNetV2 space to be wider (i.e. larger channel choices) and deeper (i.e. more blocks), while adding Split-Attention block and enabling the search over the number of splits. When searching a model of size 0.4G FLOPS, FP-NAS is 132x faster than EfficientNet, and the searched FP-NAS-L0 model outperforms EfficientNet-B0 by 0.6% accuracy. Without using any architecture surrogate or scaling tricks, we directly search large models up to 1.0G FLOPS. Our FP-NAS-L2 model with simple distillation outperforms BigNAS-XL with advanced inplace distillation by 0.7% accuracy with less FLOPS.
Decoupling Representation and Classifier for Long-Tailed Recognition
Oct 21, 2019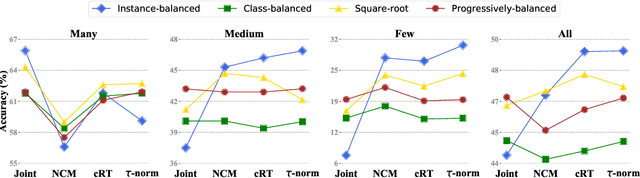
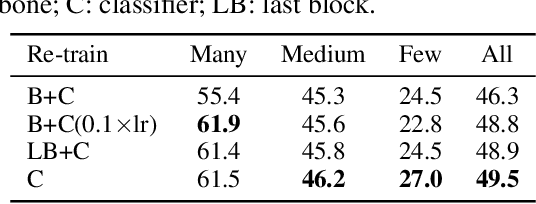
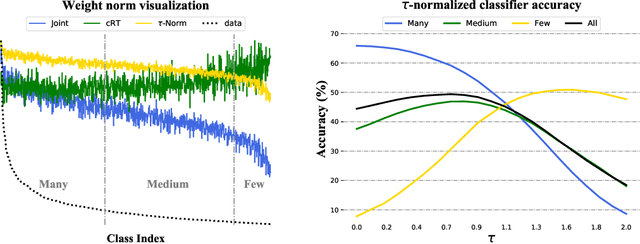
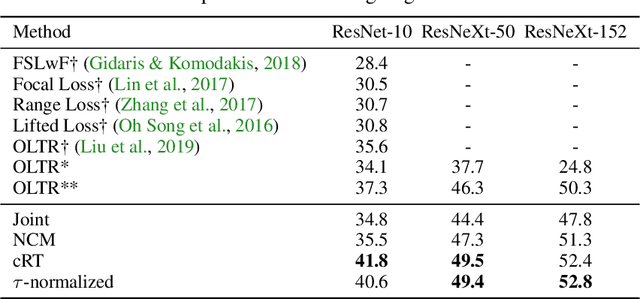
The long-tail distribution of the visual world poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balancing strategies, e.g., by loss re-weighting, data re-sampling, or transfer learning from head- to tail-classes, but most of them adhere to the scheme of jointly learning representations and classifiers. In this work, we decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition. The findings are surprising: (1) data imbalance might not be an issue in learning high-quality representations; (2) with representations learned with the simplest instance-balanced (natural) sampling, it is also possible to achieve strong long-tailed recognition ability at little cost by adjusting only the classifier. We conduct extensive experiments and set new state-of-the-art performance on common long-tailed benchmarks like ImageNet-LT, Places-LT and iNaturalist, showing that it is possible to outperform carefully designed losses, sampling strategies, even complex modules with memory, by using a straightforward approach that decouples representation and classification.
Only Time Can Tell: Discovering Temporal Data for Temporal Modeling
Jul 19, 2019
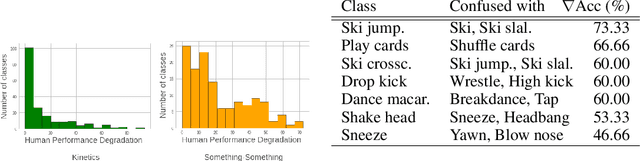


Understanding temporal information and how the visual world changes over time is a fundamental ability of intelligent systems. In video understanding, temporal information is at the core of many current challenges, including compression, efficient inference, motion estimation or summarization. However, in current video datasets it has been observed that action classes can often be recognized without any temporal information from a single frame of video. As a result, both benchmarking and training in these datasets may give an unintentional advantage to models with strong image understanding capabilities, as opposed to those with strong temporal understanding. In this paper we address this problem head on by identifying action classes where temporal information is actually necessary to recognize them and call these "temporal classes". Selecting temporal classes using a computational method would bias the process. Instead, we propose a methodology based on a simple and effective human annotation experiment. We remove just the temporal information by shuffling frames in time and measure if the action can still be recognized. Classes that cannot be recognized when frames are not in order are included in the temporal Dataset. We observe that this set is statistically different from other static classes, and that performance in it correlates with a network's ability to capture temporal information. Thus we use it as a benchmark on current popular networks, which reveals a series of interesting facts. We also explore the effect of training on the temporal dataset, and observe that this leads to better generalization in unseen classes, demonstrating the need for more temporal data. We hope that the proposed dataset of temporal categories will help guide future research in temporal modeling for better video understanding.
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Apr 30, 2019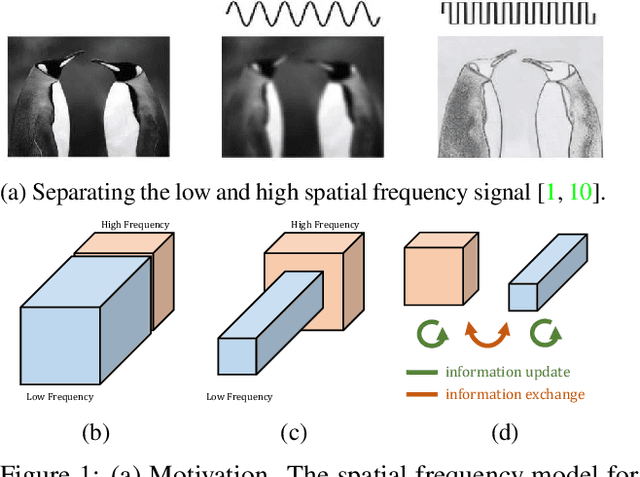

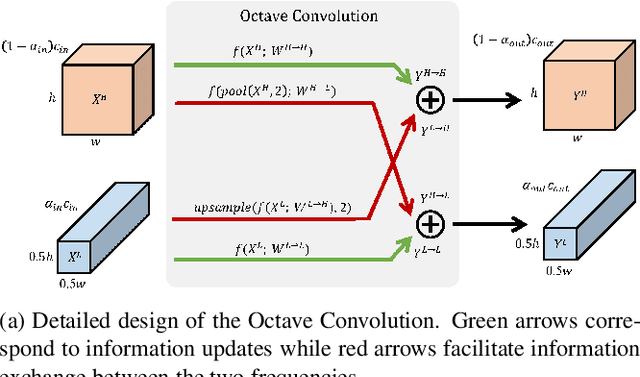
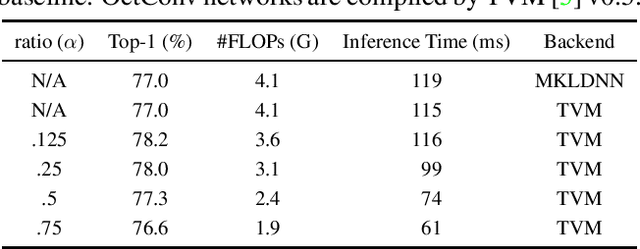
In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.
DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition
Jan 11, 2019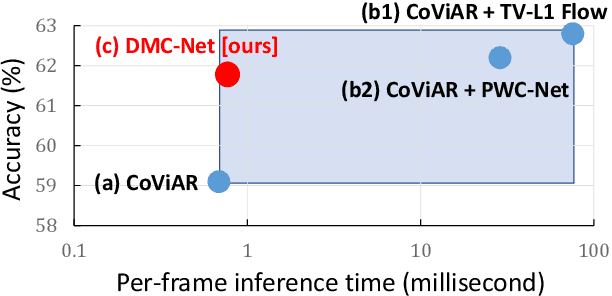

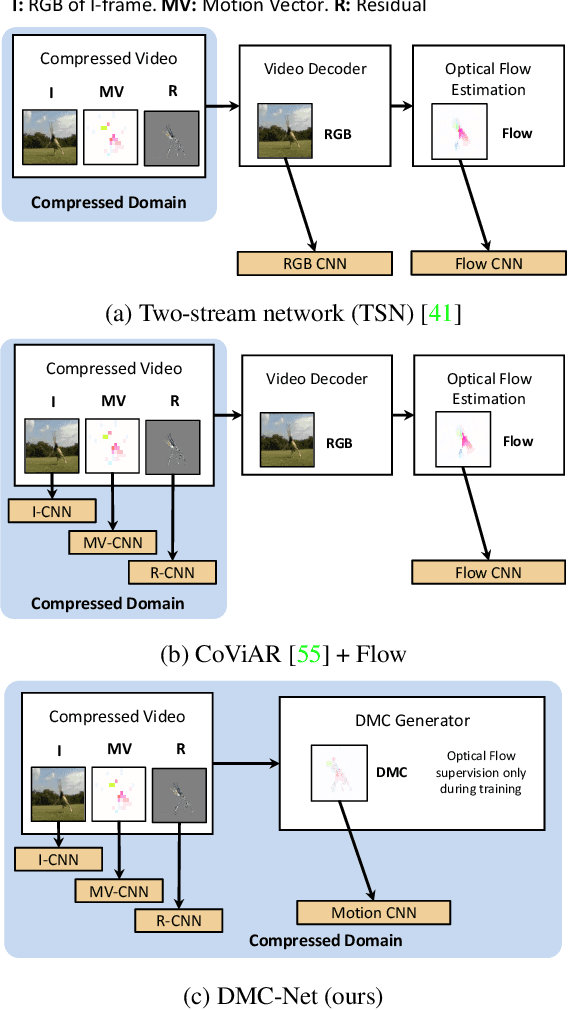
Motion has shown to be useful for video understanding, where motion is typically represented by optical flow. However, computing flow from video frames is very time-consuming. Recent works directly leverage the motion vectors and residuals readily available in the compressed video to represent motion at no cost. While this avoids flow computation, it also hurts accuracy since the motion vector is noisy and has substantially reduced resolution, which makes it a less discriminative motion representation. To remedy these issues, we propose a lightweight generator network, which reduces noises in motion vectors and captures fine motion details, achieving a more Discriminative Motion Cue (DMC) representation. Since optical flow is a more accurate motion representation, we train the DMC generator to approximate flow using a reconstruction loss and a generative adversarial loss, jointly with the downstream action classification task. Extensive evaluations on three action recognition benchmarks (HMDB-51, UCF-101, and a subset of Kinetics) confirm the effectiveness of our method. Our full system, consisting of the generator and the classifier, is coined as DMC-Net which obtains high accuracy close to that of using flow and runs two orders of magnitude faster than using optical flow at inference time.
Graph-Based Global Reasoning Networks
Nov 30, 2018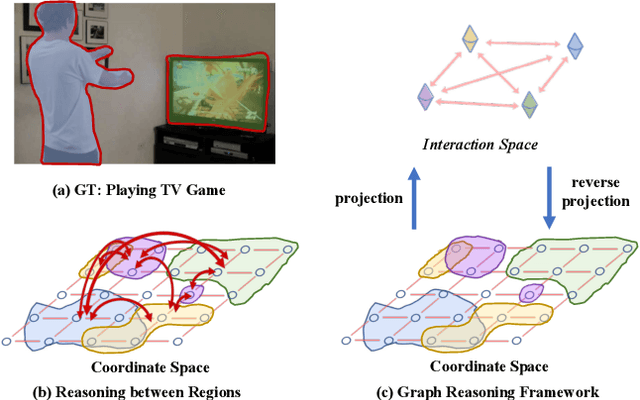
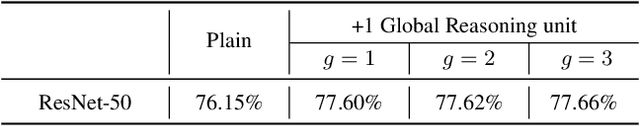
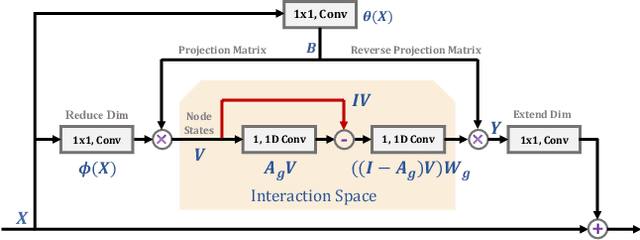
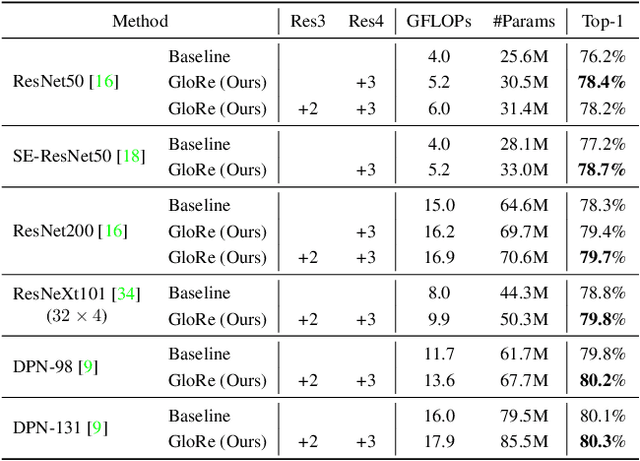
Globally modeling and reasoning over relations between regions can be beneficial for many computer vision tasks on both images and videos. Convolutional Neural Networks (CNNs) excel at modeling local relations by convolution operations, but they are typically inefficient at capturing global relations between distant regions and require stacking multiple convolution layers. In this work, we propose a new approach for reasoning globally in which a set of features are globally aggregated over the coordinate space and then projected to an interaction space where relational reasoning can be efficiently computed. After reasoning, relation-aware features are distributed back to the original coordinate space for down-stream tasks. We further present a highly efficient instantiation of the proposed approach and introduce the Global Reasoning unit (GloRe unit) that implements the coordinate-interaction space mapping by weighted global pooling and weighted broadcasting, and the relation reasoning via graph convolution on a small graph in interaction space. The proposed GloRe unit is lightweight, end-to-end trainable and can be easily plugged into existing CNNs for a wide range of tasks. Extensive experiments show our GloRe unit can consistently boost the performance of state-of-the-art backbone architectures, including ResNet, ResNeXt, SE-Net and DPN, for both 2D and 3D CNNs, on image classification, semantic segmentation and video action recognition task.
SLAC: A Sparsely Labeled Dataset for Action Classification and Localization
Dec 26, 2017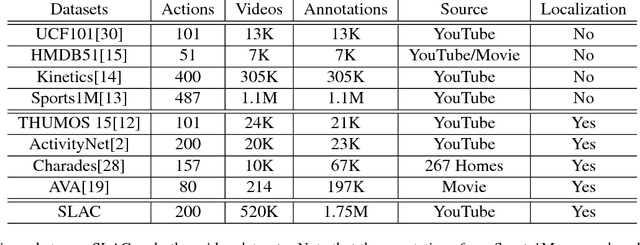
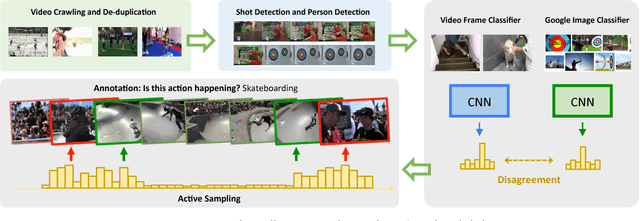


This paper describes a procedure for the creation of large-scale video datasets for action classification and localization from unconstrained, realistic web data. The scalability of the proposed procedure is demonstrated by building a novel video benchmark, named SLAC (Sparsely Labeled ACtions), consisting of over 520K untrimmed videos and 1.75M clip annotations spanning 200 action categories. Using our proposed framework, annotating a clip takes merely 8.8 seconds on average. This represents a saving in labeling time of over 95% compared to the traditional procedure of manual trimming and localization of actions. Our approach dramatically reduces the amount of human labeling by automatically identifying hard clips, i.e., clips that contain coherent actions but lead to prediction disagreement between action classifiers. A human annotator can disambiguate whether such a clip truly contains the hypothesized action in a handful of seconds, thus generating labels for highly informative samples at little cost. We show that our large-scale dataset can be used to effectively pre-train action recognition models, significantly improving final metrics on smaller-scale benchmarks after fine-tuning. On Kinetics, UCF-101 and HMDB-51, models pre-trained on SLAC outperform baselines trained from scratch, by 2.0%, 20.1% and 35.4% in top-1 accuracy, respectively when RGB input is used. Furthermore, we introduce a simple procedure that leverages the sparse labels in SLAC to pre-train action localization models. On THUMOS14 and ActivityNet-v1.3, our localization model improves the mAP of baseline model by 8.6% and 2.5%, respectively.
Learning Concept Taxonomies from Multi-modal Data
Jun 29, 2016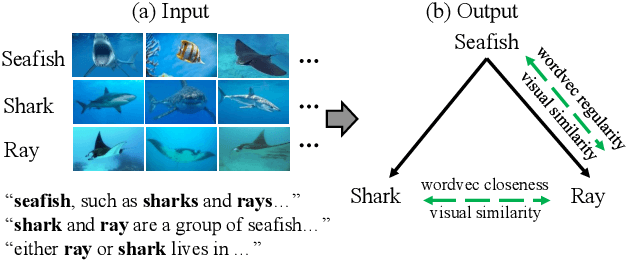
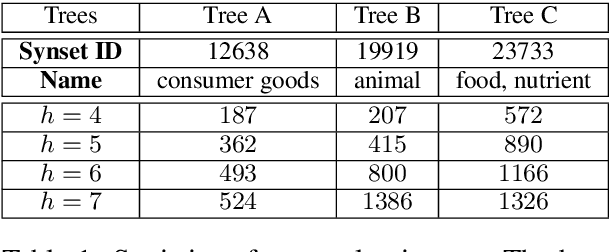
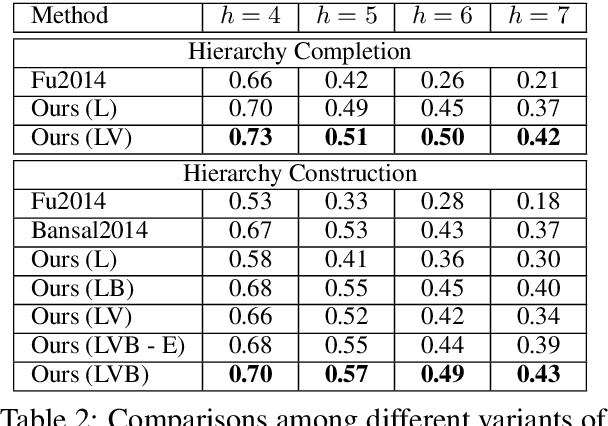
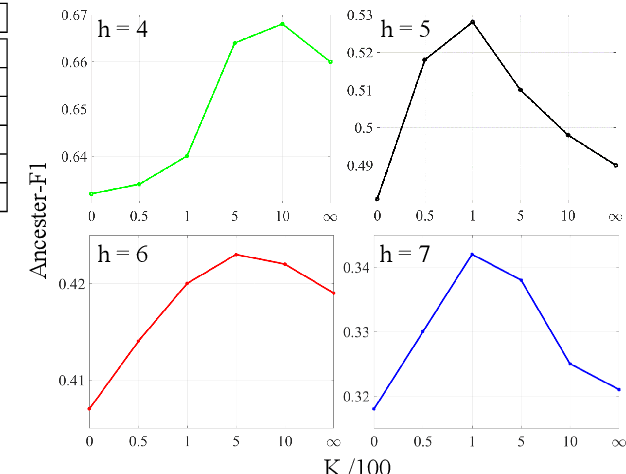
We study the problem of automatically building hypernym taxonomies from textual and visual data. Previous works in taxonomy induction generally ignore the increasingly prominent visual data, which encode important perceptual semantics. Instead, we propose a probabilistic model for taxonomy induction by jointly leveraging text and images. To avoid hand-crafted feature engineering, we design end-to-end features based on distributed representations of images and words. The model is discriminatively trained given a small set of existing ontologies and is capable of building full taxonomies from scratch for a collection of unseen conceptual label items with associated images. We evaluate our model and features on the WordNet hierarchies, where our system outperforms previous approaches by a large gap.