 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Centric Social Trajectory Prediction: A Free Energy Principle Perspective
May 25, 2026Trajectory prediction methods have demonstrated remarkable capabilities in capturing complex motion patterns. However, existing methods rely on global state assumptions, suffer from insufficient belief inference under partial observability, and lack cognitive behavioral constraints in prediction. These limitations severely compromise both deployment feasibility and physical plausibility in real-world settings. In this work, we propose FEP-Diff, an agent-centric trajectory prediction framework grounded in the Free Energy Principle, aimed at achieving cognitively plausible predictions under realistic constraints. Specifically, a dual-branch spatiotemporal encoder extracts ego-motion dynamics and social interaction cues from local observations. Building upon this, a goal-conditioned belief learner infers multimodal latent belief distributions optimized via a free-energy objective, with a social consistency constraint on the local neighborhood graph to promote cognitive alignment among neighboring agents. Finally, a residual diffusion trajectory generator is conditioned on the learned belief representations with token-level proxy conditioning, producing precise and diverse future predictions. Extensive experiments on five public benchmarks demonstrate that FEP-Diff consistently outperforms state-of-the-art methods under restricted observability. Code: https://anonymous.4open.science/r/FEP-Diff-8876.
ESIA: An Energy-Based Spatiotemporal Interaction-Aware Framework for Pedestrian Intention Prediction
Apr 26, 2026Recent advances in autonomous driving have motivated research on pedestrian intention prediction, which aims to infer future crossing decisions and actions by modeling temporal dynamics, social interactions, and environmental context. However, existing studies remain constrained by oversimplified multi-agent interaction patterns, opaque reasoning logic, and a lack of global consistency in behavioral predictions, which compromise both robustness and interpretability. In this work, we propose ESIA (Energy-based Spatiotemporal Interaction-Aware framework), a novel Conditional Random Field (CRF)-based paradigm. We cast the intention prediction task as a structured prediction problem over a unified graph-based representation, treating pedestrians and the environment as spatiotemporal nodes. To characterize their distinct roles, we assign unary potentials to nodes to capture individual intentions, and pairwise potentials to edges to encode social and environmental interactions. These potentials are integrated into a unified global energy function to ensure scene-level consistency across behavioral predictions. To further constrain inference without ground-truth supervision, we introduce structural consistency terms to penalize logical contradictions. This optimization is efficiently solved via a novel Unary-Seeded Simulated Annealing (U-SSA) algorithm, which leverages high-confidence unary priors to rapidly converge to a high-quality solution. Extensive experiments on standard benchmarks demonstrate that ESIA achieves state-of-the-art performance with improved interpretability over existing methods.
Free Energy-Inspired Cognitive Risk Integration for AV Navigation in Pedestrian-Rich Environments
Jul 28, 2025



Recent advances in autonomous vehicle (AV) behavior planning have shown impressive social interaction capabilities when interacting with other road users. However, achieving human-like prediction and decision-making in interactions with vulnerable road users remains a key challenge in complex multi-agent interactive environments. Existing research focuses primarily on crowd navigation for small mobile robots, which cannot be directly applied to AVs due to inherent differences in their decision-making strategies and dynamic boundaries. Moreover, pedestrians in these multi-agent simulations follow fixed behavior patterns that cannot dynamically respond to AV actions. To overcome these limitations, this paper proposes a novel framework for modeling interactions between the AV and multiple pedestrians. In this framework, a cognitive process modeling approach inspired by the Free Energy Principle is integrated into both the AV and pedestrian models to simulate more realistic interaction dynamics. Specifically, the proposed pedestrian Cognitive-Risk Social Force Model adjusts goal-directed and repulsive forces using a fused measure of cognitive uncertainty and physical risk to produce human-like trajectories. Meanwhile, the AV leverages this fused risk to construct a dynamic, risk-aware adjacency matrix for a Graph Convolutional Network within a Soft Actor-Critic architecture, allowing it to make more reasonable and informed decisions. Simulation results indicate that our proposed framework effectively improves safety, efficiency, and smoothness of AV navigation compared to the state-of-the-art method.
Iterative Feature Space Optimization through Incremental Adaptive Evaluation
Jan 24, 2025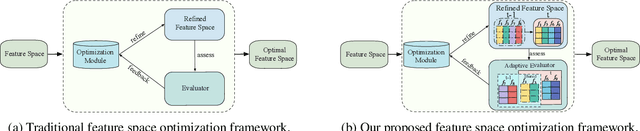
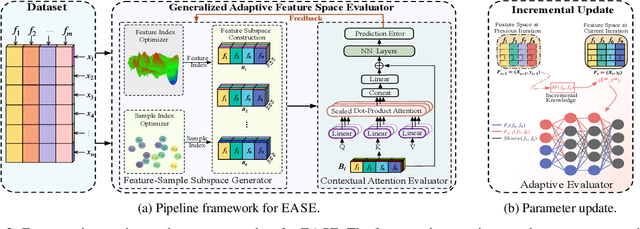
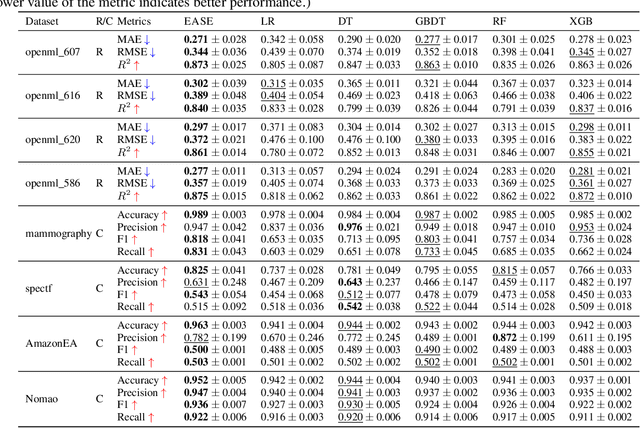
Iterative feature space optimization involves systematically evaluating and adjusting the feature space to improve downstream task performance. However, existing works suffer from three key limitations:1) overlooking differences among data samples leads to evaluation bias; 2) tailoring feature spaces to specific machine learning models results in overfitting and poor generalization; 3) requiring the evaluator to be retrained from scratch during each optimization iteration significantly reduces the overall efficiency of the optimization process. To bridge these gaps, we propose a gEneralized Adaptive feature Space Evaluator (EASE) to efficiently produce optimal and generalized feature spaces. This framework consists of two key components: Feature-Sample Subspace Generator and Contextual Attention Evaluator. The first component aims to decouple the information distribution within the feature space to mitigate evaluation bias. To achieve this, we first identify features most relevant to prediction tasks and samples most challenging for evaluation based on feedback from the subsequent evaluator. This decoupling strategy makes the evaluator consistently target the most challenging aspects of the feature space. The second component intends to incrementally capture evolving patterns of the feature space for efficient evaluation. We propose a weighted-sharing multi-head attention mechanism to encode key characteristics of the feature space into an embedding vector for evaluation. Moreover, the evaluator is updated incrementally, retaining prior evaluation knowledge while incorporating new insights, as consecutive feature spaces during the optimization process share partial information. Extensive experiments on fourteen real-world datasets demonstrate the effectiveness of the proposed framework. Our code and data are publicly available.
Fingerprint Classification Based on Depth Neural Network
Sep 18, 2014
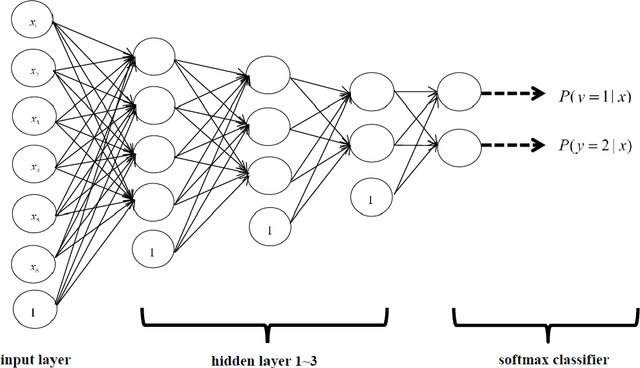
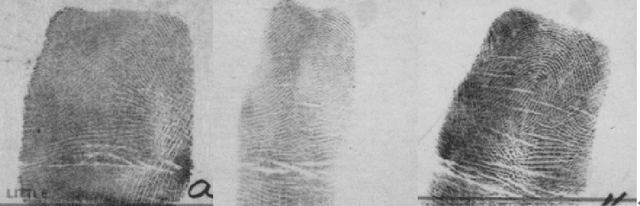
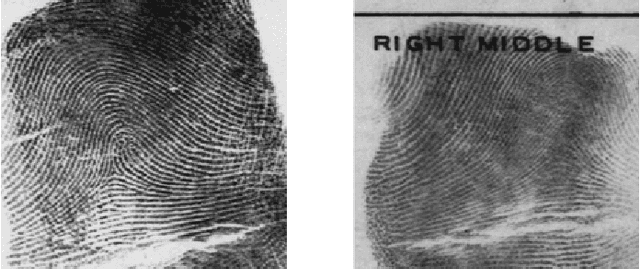
Fingerprint classification is an effective technique for reducing the candidate numbers of fingerprints in the stage of matching in automatic fingerprint identification system (AFIS). In recent years, deep learning is an emerging technology which has achieved great success in many fields, such as image processing, natural language processing and so on. In this paper, we only choose the orientation field as the input feature and adopt a new method (stacked sparse autoencoders) based on depth neural network for fingerprint classification. For the four-class problem, we achieve a classification of 93.1 percent using the depth network structure which has three hidden layers (with 1.8% rejection) in the NIST-DB4 database. And then we propose a novel method using two classification probabilities for fuzzy classification which can effectively enhance the accuracy of classification. By only adjusting the probability threshold, we get the accuracy of classification is 96.1% (setting threshold is 0.85), 97.2% (setting threshold is 0.90) and 98.0% (setting threshold is 0.95). Using the fuzzy method, we obtain higher accuracy than other methods.