 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockchain-based Federated Recommendation with Incentive Mechanism
Sep 03, 2024


Nowadays, federated recommendation technology is rapidly evolving to help multiple organisations share data and train models while meeting user privacy, data security and government regulatory requirements. However, federated recommendation increases customer system costs such as power, computational and communication resources. Besides, federated recommendation systems are also susceptible to model attacks and data poisoning by participating malicious clients. Therefore, most customers are unwilling to participate in federated recommendation without any incentive. To address these problems, we propose a blockchain-based federated recommendation system with incentive mechanism to promote more trustworthy, secure, and efficient federated recommendation service. First, we construct a federated recommendation system based on NeuMF and FedAvg. Then we introduce a reverse auction mechanism to select optimal clients that can maximize the social surplus. Finally, we employ blockchain for on-chain evidence storage of models to ensure the safety of the federated recommendation system. The experimental results show that our proposed incentive mechanism can attract clients with superior training data to engage in the federal recommendation at a lower cost, which can increase the economic benefit of federal recommendation by 54.9\% while improve the recommendation performance. Thus our work provides theoretical and technological support for the construction of a harmonious and healthy ecological environment for the application of federal recommendation.
ETGuard: Malicious Encrypted Traffic Detection in Blockchain-based Power Grid Systems
Aug 20, 2024The escalating prevalence of encryption protocols has led to a concomitant surge in the number of malicious attacks that hide in encrypted traffic. Power grid systems, as fundamental infrastructure, are becoming prime targets for such attacks. Conventional methods for detecting malicious encrypted packets typically use a static pre-trained model. We observe that these methods are not well-suited for blockchain-based power grid systems. More critically, they fall short in dynamic environments where new types of encrypted attacks continuously emerge. Motivated by this, in this paper we try to tackle these challenges from two aspects: (1) We present a novel framework that is able to automatically detect malicious encrypted traffic in blockchain-based power grid systems and incrementally learn from new malicious traffic. (2) We mathematically derive incremental learning losses to resist the forgetting of old attack patterns while ensuring the model is capable of handling new encrypted attack patterns. Empirically, our method achieves state-of-the-art performance on three different benchmark datasets. We also constructed the first malicious encrypted traffic dataset for blockchain-based power grid scenario. Our code and dataset are available at https://github.com/PPPmzt/ETGuard, hoping to inspire future research.
Joint-Motion Mutual Learning for Pose Estimation in Videos
Aug 05, 2024Human pose estimation in videos has long been a compelling yet challenging task within the realm of computer vision. Nevertheless, this task remains difficult because of the complex video scenes, such as video defocus and self-occlusion. Recent methods strive to integrate multi-frame visual features generated by a backbone network for pose estimation. However, they often ignore the useful joint information encoded in the initial heatmap, which is a by-product of the backbone generation. Comparatively, methods that attempt to refine the initial heatmap fail to consider any spatio-temporal motion features. As a result, the performance of existing methods for pose estimation falls short due to the lack of ability to leverage both local joint (heatmap) information and global motion (feature) dynamics. To address this problem, we propose a novel joint-motion mutual learning framework for pose estimation, which effectively concentrates on both local joint dependency and global pixel-level motion dynamics. Specifically, we introduce a context-aware joint learner that adaptively leverages initial heatmaps and motion flow to retrieve robust local joint feature. Given that local joint feature and global motion flow are complementary, we further propose a progressive joint-motion mutual learning that synergistically exchanges information and interactively learns between joint feature and motion flow to improve the capability of the model. More importantly, to capture more diverse joint and motion cues, we theoretically analyze and propose an information orthogonality objective to avoid learning redundant information from multi-cues. Empirical experiments show our method outperforms prior arts on three challenging benchmarks.
Multi-threshold Deep Metric Learning for Facial Expression Recognition
Jun 24, 2024



Effective expression feature representations generated by a triplet-based deep metric learning are highly advantageous for facial expression recognition (FER). The performance of triplet-based deep metric learning is contingent upon identifying the best threshold for triplet loss. Threshold validation, however, is tough and challenging, as the ideal threshold changes among datasets and even across classes within the same dataset. In this paper, we present the multi-threshold deep metric learning technique, which not only avoids the difficult threshold validation but also vastly increases the capacity of triplet loss learning to construct expression feature representations. We find that each threshold of the triplet loss intrinsically determines a distinctive distribution of inter-class variations and corresponds, thus, to a unique expression feature representation. Therefore, rather than selecting a single optimal threshold from a valid threshold range, we thoroughly sample thresholds across the range, allowing the representation characteristics manifested by thresholds within the range to be fully extracted and leveraged for FER. To realize this approach, we partition the embedding layer of the deep metric learning network into a collection of slices and model training these embedding slices as an end-to-end multi-threshold deep metric learning problem. Each embedding slice corresponds to a sample threshold and is learned by enforcing the corresponding triplet loss, yielding a set of distinct expression features, one for each embedding slice. It makes the embedding layer, which is composed of a set of slices, a more informative and discriminative feature, hence enhancing the FER accuracy. Extensive evaluations demonstrate the superior performance of the proposed approach on both posed and spontaneous facial expression datasets.
Do As I Do: Pose Guided Human Motion Copy
Jun 24, 2024



Human motion copy is an intriguing yet challenging task in artificial intelligence and computer vision, which strives to generate a fake video of a target person performing the motion of a source person. The problem is inherently challenging due to the subtle human-body texture details to be generated and the temporal consistency to be considered. Existing approaches typically adopt a conventional GAN with an L1 or L2 loss to produce the target fake video, which intrinsically necessitates a large number of training samples that are challenging to acquire. Meanwhile, current methods still have difficulties in attaining realistic image details and temporal consistency, which unfortunately can be easily perceived by human observers. Motivated by this, we try to tackle the issues from three aspects: (1) We constrain pose-to-appearance generation with a perceptual loss and a theoretically motivated Gromov-Wasserstein loss to bridge the gap between pose and appearance. (2) We present an episodic memory module in the pose-to-appearance generation to propel continuous learning that helps the model learn from its past poor generations. We also utilize geometrical cues of the face to optimize facial details and refine each key body part with a dedicated local GAN. (3) We advocate generating the foreground in a sequence-to-sequence manner rather than a single-frame manner, explicitly enforcing temporal inconsistency. Empirical results on five datasets, iPER, ComplexMotion, SoloDance, Fish, and Mouse datasets, demonstrate that our method is capable of generating realistic target videos while precisely copying motion from a source video. Our method significantly outperforms state-of-the-art approaches and gains 7.2% and 12.4% improvements in PSNR and FID respectively.
Exposing the Deception: Uncovering More Forgery Clues for Deepfake Detection
Mar 04, 2024



Deepfake technology has given rise to a spectrum of novel and compelling applications. Unfortunately, the widespread proliferation of high-fidelity fake videos has led to pervasive confusion and deception, shattering our faith that seeing is believing. One aspect that has been overlooked so far is that current deepfake detection approaches may easily fall into the trap of overfitting, focusing only on forgery clues within one or a few local regions. Moreover, existing works heavily rely on neural networks to extract forgery features, lacking theoretical constraints guaranteeing that sufficient forgery clues are extracted and superfluous features are eliminated. These deficiencies culminate in unsatisfactory accuracy and limited generalizability in real-life scenarios. In this paper, we try to tackle these challenges through three designs: (1) We present a novel framework to capture broader forgery clues by extracting multiple non-overlapping local representations and fusing them into a global semantic-rich feature. (2) Based on the information bottleneck theory, we derive Local Information Loss to guarantee the orthogonality of local representations while preserving comprehensive task-relevant information. (3) Further, to fuse the local representations and remove task-irrelevant information, we arrive at a Global Information Loss through the theoretical analysis of mutual information. Empirically, our method achieves state-of-the-art performance on five benchmark datasets.Our code is available at \url{https://github.com/QingyuLiu/Exposing-the-Deception}, hoping to inspire researchers.
Alleviating Structural Distribution Shift in Graph Anomaly Detection
Jan 25, 2024



Graph anomaly detection (GAD) is a challenging binary classification problem due to its different structural distribution between anomalies and normal nodes -- abnormal nodes are a minority, therefore holding high heterophily and low homophily compared to normal nodes. Furthermore, due to various time factors and the annotation preferences of human experts, the heterophily and homophily can change across training and testing data, which is called structural distribution shift (SDS) in this paper. The mainstream methods are built on graph neural networks (GNNs), benefiting the classification of normals from aggregating homophilous neighbors, yet ignoring the SDS issue for anomalies and suffering from poor generalization. This work solves the problem from a feature view. We observe that the degree of SDS varies between anomalies and normal nodes. Hence to address the issue, the key lies in resisting high heterophily for anomalies meanwhile benefiting the learning of normals from homophily. We tease out the anomaly features on which we constrain to mitigate the effect of heterophilous neighbors and make them invariant. We term our proposed framework as Graph Decomposition Network (GDN). Extensive experiments are conducted on two benchmark datasets, and the proposed framework achieves a remarkable performance boost in GAD, especially in an SDS environment where anomalies have largely different structural distribution across training and testing environments. Codes are open-sourced in https://github.com/blacksingular/wsdm_GDN.
Red Teaming Visual Language Models
Jan 23, 2024



VLMs (Vision-Language Models) extend the capabilities of LLMs (Large Language Models) to accept multimodal inputs. Since it has been verified that LLMs can be induced to generate harmful or inaccurate content through specific test cases (termed as Red Teaming), how VLMs perform in similar scenarios, especially with their combination of textual and visual inputs, remains a question. To explore this problem, we present a novel red teaming dataset RTVLM, which encompasses 10 subtasks (e.g., image misleading, multi-modal jail-breaking, face fairness, etc) under 4 primary aspects (faithfulness, privacy, safety, fairness). Our RTVLM is the first red-teaming dataset to benchmark current VLMs in terms of these 4 different aspects. Detailed analysis shows that 10 prominent open-sourced VLMs struggle with the red teaming in different degrees and have up to 31% performance gap with GPT-4V. Additionally, we simply apply red teaming alignment to LLaVA-v1.5 with Supervised Fine-tuning (SFT) using RTVLM, and this bolsters the models' performance with 10% in RTVLM test set, 13% in MM-Hal, and without noticeable decline in MM-Bench, overpassing other LLaVA-based models with regular alignment data. This reveals that current open-sourced VLMs still lack red teaming alignment. Our code and datasets will be open-source.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023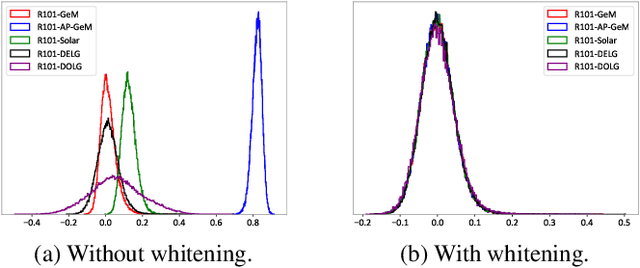
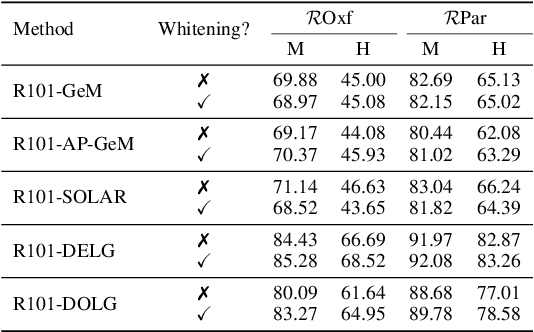
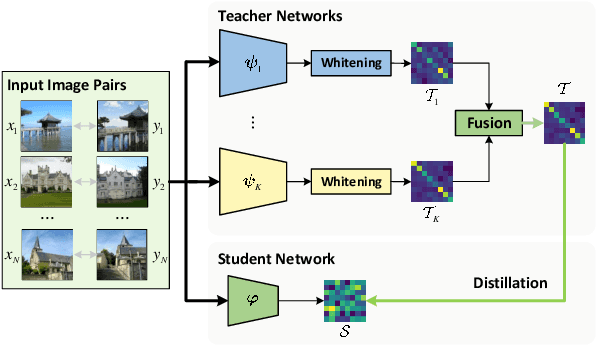
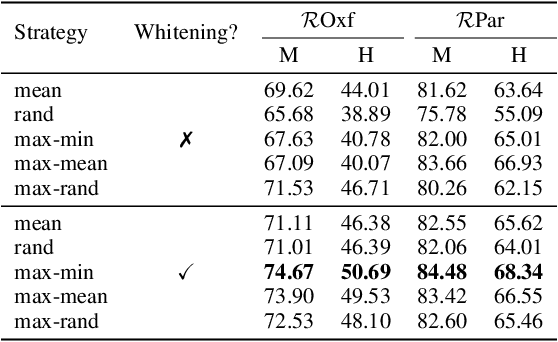
Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.
Locate and Verify: A Two-Stream Network for Improved Deepfake Detection
Sep 20, 2023



Deepfake has taken the world by storm, triggering a trust crisis. Current deepfake detection methods are typically inadequate in generalizability, with a tendency to overfit to image contents such as the background, which are frequently occurring but relatively unimportant in the training dataset. Furthermore, current methods heavily rely on a few dominant forgery regions and may ignore other equally important regions, leading to inadequate uncovering of forgery cues. In this paper, we strive to address these shortcomings from three aspects: (1) We propose an innovative two-stream network that effectively enlarges the potential regions from which the model extracts forgery evidence. (2) We devise three functional modules to handle the multi-stream and multi-scale features in a collaborative learning scheme. (3) Confronted with the challenge of obtaining forgery annotations, we propose a Semi-supervised Patch Similarity Learning strategy to estimate patch-level forged location annotations. Empirically, our method demonstrates significantly improved robustness and generalizability, outperforming previous methods on six benchmarks, and improving the frame-level AUC on Deepfake Detection Challenge preview dataset from 0.797 to 0.835 and video-level AUC on CelebDF$\_$v1 dataset from 0.811 to 0.847. Our implementation is available at https://github.com/sccsok/Locate-and-Verify.