 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Efficiency and Reliability for Continuous Mobile Manipulation
Apr 07, 2026Humans seamlessly fuse anticipatory planning with immediate feedback to perform successive mobile manipulation tasks without stopping, achieving both high efficiency and reliability. Replicating this fluid and reliable behavior in robots remains fundamentally challenging, not only due to conflicts between long-horizon planning and real-time reactivity, but also because excessively pursuing efficiency undermines reliability in uncertain environments: it impairs stable perception and the potential for compensation, while also increasing the risk of unintended contact. In this work, we present a unified framework that synergizes efficiency and reliability for continuous mobile manipulation. It features a reliability-aware trajectory planner that embeds essential elements for reliable execution into spatiotemporal optimization, generating efficient and reliability-promising global trajectories. It is coupled with a phase-dependent switching controller that seamlessly transitions between global trajectory tracking for efficiency and task-error compensation for reliability. We also investigate a hierarchical initialization that facilitates online replanning despite the complexity of long-horizon planning problems. Real-world evaluations demonstrate that our approach enables efficient and reliable completion of successive tasks under uncertainty (e.g., dynamic disturbances, perception and control errors). Moreover, the framework generalizes to tasks with diverse end-effector constraints. Compared with state-of-the-art baselines, our method consistently achieves the highest efficiency while improving the task success rate by 26.67\%--81.67\%. Comprehensive ablation studies further validate the contribution of each component. The source code will be released.
Rethinking Scientific Modeling: Toward Physically Consistent and Simulation-Executable Programmatic Generation
Feb 06, 2026Structural modeling is a fundamental component of computational engineering science, in which even minor physical inconsistencies or specification violations may invalidate downstream simulations. The potential of large language models (LLMs) for automatic generation of modeling code has been demonstrated. However, non-executable or physically inconsistent outputs remain prevalent under stringent engineering constraints. A framework for physics-consistent automatic building modeling is therefore proposed, integrating domain knowledge construction, constraint-oriented model alignment, and verification-driven evaluation. CivilInstruct is introduced as a domain-specific dataset that formalizes structural engineering knowledge and constraint reasoning to enable simulation-ready model generation. A two-stage fine-tuning strategy is further employed to enforce constraint satisfaction and application programming interface compliance, substantially reducing hallucinated and non-conforming outputs. MBEval is presented as a verification-driven benchmark that evaluates executability and structural dynamics consistency through closed-loop validation. Experimental results show consistent improvements over baselines across rigorous verification metrics. Our code is available at https://github.com/Jovanqing/AutoBM.
Efficient Coordination with the System-Level Shared State: An Embodied-AI Native Modular Framework
Jan 20, 2026As Embodied AI systems move from research prototypes to real world deployments, they tend to evolve rapidly while remaining reliable under workload changes and partial failures. In practice, many deployments are only partially decoupled: middleware moves messages, but shared context and feedback semantics are implicit, causing interface drift, cross-module interference, and brittle recovery at scale. We present ANCHOR, a modular framework that makes decoupling and robustness explicit system-level primitives. ANCHOR separates (i) Canonical Records, an evolvable contract for the standardized shared state, from (ii) a communication bus for many-to-many dissemination and feedback-oriented coordination, forming an inspectable end-to-end loop. We validate closed-loop feasibility on a de-identified workflow instantiation, characterize latency distributions under varying payload sizes and publish rates, and demonstrate automatic stream resumption after hard crashes and restarts even with shared-memory loss. Overall, ANCHOR turns ad-hoc integration glue into explicit contracts, enabling controlled degradation under load and self-healing recovery for scalable deployment of closed-loop AI systems.
MonoSLAM: Robust Monocular SLAM with Global Structure Optimization
Mar 12, 2025This paper presents a robust monocular visual SLAM system that simultaneously utilizes point, line, and vanishing point features for accurate camera pose estimation and mapping. To address the critical challenge of achieving reliable localization in low-texture environments, where traditional point-based systems often fail due to insufficient visual features, we introduce a novel approach leveraging Global Primitives structural information to improve the system's robustness and accuracy performance. Our key innovation lies in constructing vanishing points from line features and proposing a weighted fusion strategy to build Global Primitives in the world coordinate system. This strategy associates multiple frames with non-overlapping regions and formulates a multi-frame reprojection error optimization, significantly improving tracking accuracy in texture-scarce scenarios. Evaluations on various datasets show that our system outperforms state-of-the-art methods in trajectory precision, particularly in challenging environments.
You Only Look at Once for Real-time and Generic Multi-Task
Oct 10, 2023



High precision, lightweight, and real-time responsiveness are three essential requirements for implementing autonomous driving. In this study, we present an adaptive, real-time, and lightweight multi-task model designed to concurrently address object detection, drivable area segmentation, and lane line segmentation tasks. Specifically, we developed an end-to-end multi-task model with a unified and streamlined segmentation structure. We introduced a learnable parameter that adaptively concatenate features in segmentation necks, using the same loss function for all segmentation tasks. This eliminates the need for customizations and enhances the model's generalization capabilities. We also introduced a segmentation head composed only of a series of convolutional layers, which reduces the inference time. We achieved competitive results on the BDD100k dataset, particularly in visualization outcomes. The performance results show a mAP50 of 81.1% for object detection, a mIoU of 91.0% for drivable area segmentation, and an IoU of 28.8% for lane line segmentation. Additionally, we introduced real-world scenarios to evaluate our model's performance in a real scene, which significantly outperforms competitors. This demonstrates that our model not only exhibits competitive performance but is also more flexible and faster than existing multi-task models. The source codes and pre-trained models are released at https://github.com/JiayuanWang-JW/YOLOv8-multi-task
An Attentive-based Generative Model for Medical Image Synthesis
Jun 02, 2023Magnetic resonance (MR) and computer tomography (CT) imaging are valuable tools for diagnosing diseases and planning treatment. However, limitations such as radiation exposure and cost can restrict access to certain imaging modalities. To address this issue, medical image synthesis can generate one modality from another, but many existing models struggle with high-quality image synthesis when multiple slices are present in the dataset. This study proposes an attention-based dual contrast generative model, called ADC-cycleGAN, which can synthesize medical images from unpaired data with multiple slices. The model integrates a dual contrast loss term with the CycleGAN loss to ensure that the synthesized images are distinguishable from the source domain. Additionally, an attention mechanism is incorporated into the generators to extract informative features from both channel and spatial domains. To improve performance when dealing with multiple slices, the $K$-means algorithm is used to cluster the dataset into $K$ groups, and each group is used to train a separate ADC-cycleGAN. Experimental results demonstrate that the proposed ADC-cycleGAN model produces comparable samples to other state-of-the-art generative models, achieving the highest PSNR and SSIM values of 19.04385 and 0.68551, respectively. We publish the code at https://github.com/JiayuanWang-JW/ADC-cycleGAN.
DC-cycleGAN: Bidirectional CT-to-MR Synthesis from Unpaired Data
Nov 02, 2022Magnetic resonance (MR) and computer tomography (CT) images are two typical types of medical images that provide mutually-complementary information for accurate clinical diagnosis and treatment. However, obtaining both images may be limited due to some considerations such as cost, radiation dose and modality missing. Recently, medical image synthesis has aroused gaining research interest to cope with this limitation. In this paper, we propose a bidirectional learning model, denoted as dual contrast cycleGAN (DC-cycleGAN), to synthesis medical images from unpaired data. Specifically, a dual contrast loss is introduced into the discriminators to indirectly build constraints between MR and CT images by taking the advantage of samples from the source domain as negative sample and enforce the synthetic images fall far away from the source domain. In addition, cross entropy and structural similarity index (SSIM) are integrated into the cycleGAN in order to consider both luminance and structure of samples when synthesizing images. The experimental results indicates that DC-cycleGAN is able to produce promising results as compared with other cycleGAN-based medical image synthesis methods such as cycleGAN, RegGAN, DualGAN and NiceGAN. The code will be available at https://github.com/JiayuanWang-JW/DC-cycleGAN.
Road Network Reconstruction from Satellite Images with Machine Learning Supported by Topological Methods
Sep 15, 2019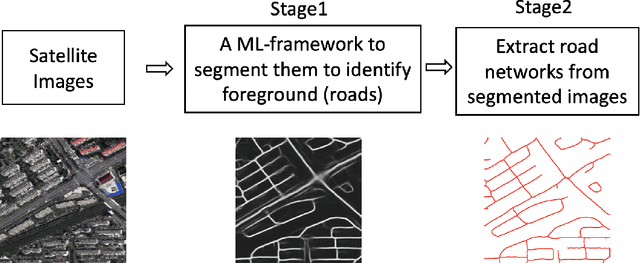
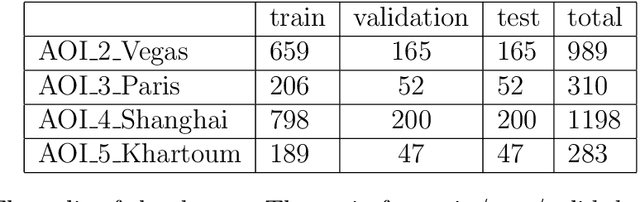
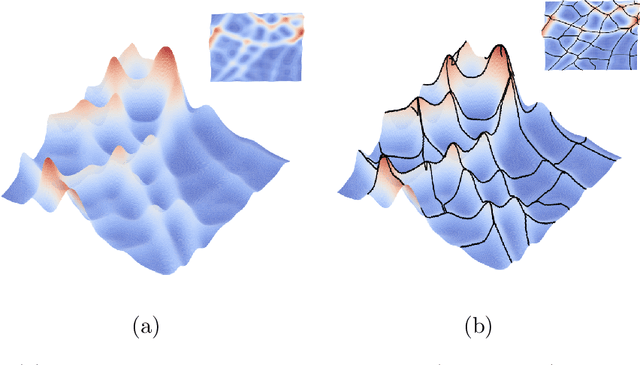
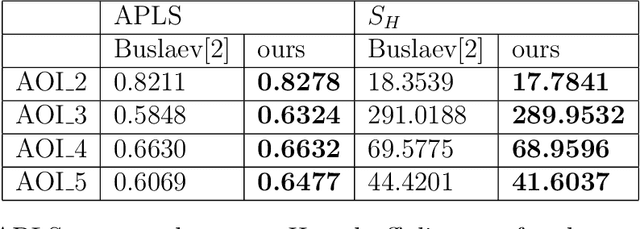
Automatic Extraction of road network from satellite images is a goal that can benefit and even enable new technologies. Methods that combine machine learning (ML) and computer vision have been proposed in recent years which make the task semi-automatic by requiring the user to provide curated training samples. The process can be fully automatized if training samples can be produced algorithmically. Of course, this requires a robust algorithm that can reconstruct the road networks from satellite images reliably so that the output can be fed as training samples. In this work, we develop such a technique by infusing a persistence-guided discrete Morse based graph reconstruction algorithm into ML framework. We elucidate our contributions in two phases. First, in a semi-automatic framework, we combine a discrete-Morse based graph reconstruction algorithm with an existing CNN framework to segment input satellite images. We show that this leads to reconstructions with better connectivity and less noise. Next, in a fully automatic framework, we leverage the power of the discrete-Morse based graph reconstruction algorithm to train a CNN from a collection of images without labelled data and use the same algorithm to produce the final output from the segmented images created by the trained CNN. We apply the discrete-Morse based graph reconstruction algorithm iteratively to improve the accuracy of the CNN. We show promising experimental results of this new framework on datasets from SpaceNet Challenge.