 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy
Apr 29, 2025To support the Low Altitude Economy (LAE), precise unmanned aerial vehicles (UAVs) localization in urban areas where global positioning system (GPS) signals are unavailable. Vision-based methods offer a viable alternative but face severe bandwidth, memory and processing constraints on lightweight UAVs. Inspired by mammalian spatial cognition, we propose a task-oriented communication framework, where UAVs equipped with multi-camera systems extract compact multi-view features and offload localization tasks to edge servers. We introduce the Orthogonally-constrained Variational Information Bottleneck encoder (O-VIB), which incorporates automatic relevance determination (ARD) to prune non-informative features while enforcing orthogonality to minimize redundancy. This enables efficient and accurate localization with minimal transmission cost. Extensive evaluation on a dedicated LAE UAV dataset shows that O-VIB achieves high-precision localization under stringent bandwidth budgets. Code and dataset will be made publicly available: github.com/fangzr/TOC-Edge-Aerial.
Enhancing the Patent Matching Capability of Large Language Models via the Memory Graph
Apr 21, 2025



Intellectual Property (IP) management involves strategically protecting and utilizing intellectual assets to enhance organizational innovation, competitiveness, and value creation. Patent matching is a crucial task in intellectual property management, which facilitates the organization and utilization of patents. Existing models often rely on the emergent capabilities of Large Language Models (LLMs) and leverage them to identify related patents directly. However, these methods usually depend on matching keywords and overlook the hierarchical classification and categorical relationships of patents. In this paper, we propose MemGraph, a method that augments the patent matching capabilities of LLMs by incorporating a memory graph derived from their parametric memory. Specifically, MemGraph prompts LLMs to traverse their memory to identify relevant entities within patents, followed by attributing these entities to corresponding ontologies. After traversing the memory graph, we utilize extracted entities and ontologies to improve the capability of LLM in comprehending the semantics of patents. Experimental results on the PatentMatch dataset demonstrate the effectiveness of MemGraph, achieving a 17.68% performance improvement over baseline LLMs. The further analysis highlights the generalization ability of MemGraph across various LLMs, both in-domain and out-of-domain, and its capacity to enhance the internal reasoning processes of LLMs during patent matching. All data and codes are available at https://github.com/NEUIR/MemGraph.
Judge as A Judge: Improving the Evaluation of Retrieval-Augmented Generation through the Judge-Consistency of Large Language Models
Feb 26, 2025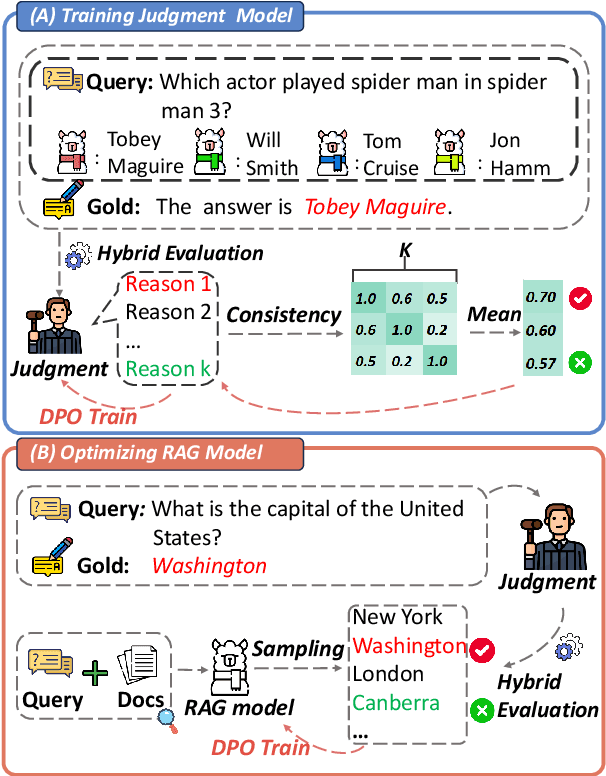
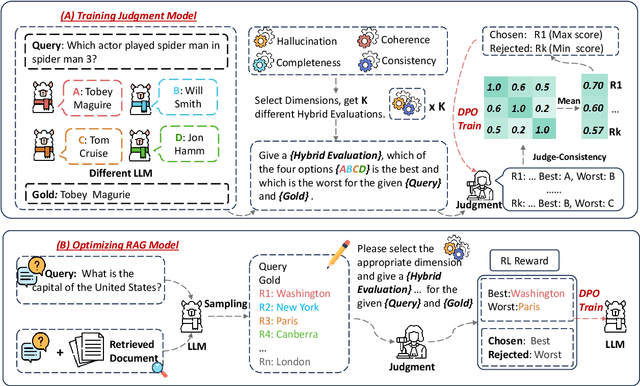
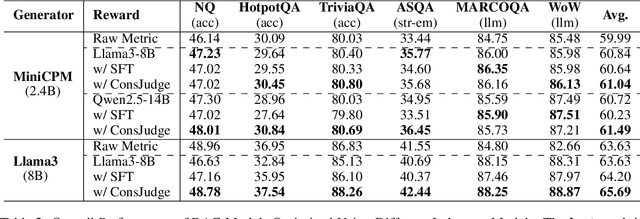
Retrieval-Augmented Generation (RAG) has proven its effectiveness in alleviating hallucinations for Large Language Models (LLMs). However, existing automated evaluation metrics cannot fairly evaluate the outputs generated by RAG models during training and evaluation. LLM-based judgment models provide the potential to produce high-quality judgments, but they are highly sensitive to evaluation prompts, leading to inconsistencies when judging the output of RAG models. This paper introduces the Judge-Consistency (ConsJudge) method, which aims to enhance LLMs to generate more accurate evaluations for RAG models. Specifically, ConsJudge prompts LLMs to generate different judgments based on various combinations of judgment dimensions, utilize the judge-consistency to evaluate these judgments and select the accepted and rejected judgments for DPO training. Our experiments show that ConsJudge can effectively provide more accurate judgments for optimizing RAG models across various RAG models and datasets. Further analysis reveals that judgments generated by ConsJudge have a high agreement with the superior LLM. All codes are available at https://github.com/OpenBMB/ConsJudge.
RankCoT: Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts
Feb 25, 2025Retrieval-Augmented Generation (RAG) enhances the performance of Large Language Models (LLMs) by incorporating external knowledge. However, LLMs still encounter challenges in effectively utilizing the knowledge from retrieved documents, often being misled by irrelevant or noisy information. To address this issue, we introduce RankCoT, a knowledge refinement method that incorporates reranking signals in generating CoT-based summarization for knowledge refinement based on given query and all retrieval documents. During training, RankCoT prompts the LLM to generate Chain-of-Thought (CoT) candidates based on the query and individual documents. It then fine-tunes the LLM to directly reproduce the best CoT from these candidate outputs based on all retrieved documents, which requires LLM to filter out irrelevant documents during generating CoT-style summarization. Additionally, RankCoT incorporates a self-reflection mechanism that further refines the CoT outputs, resulting in higher-quality training data. Our experiments demonstrate the effectiveness of RankCoT, showing its superior performance over other knowledge refinement models. Further analysis reveals that RankCoT can provide shorter but effective refinement results, enabling the generator to produce more accurate answers. All code and data are available at https://github.com/NEUIR/RankCoT.
HIPPO: Enhancing the Table Understanding Capability of Large Language Models through Hybrid-Modal Preference Optimization
Feb 24, 2025Tabular data contains rich structural semantics and plays a crucial role in organizing and manipulating information. To better capture these structural semantics, this paper introduces the HybrId-modal Preference oPtimizatiOn (HIPPO) model, which represents tables using both text and image, and optimizes MLLMs to effectively learn more comprehensive table information from these multiple modalities. Specifically, HIPPO samples model responses from hybrid-modal table representations and designs a modality-consistent sampling strategy to enhance response diversity and mitigate modality bias during DPO training. Experimental results on table question answering and table fact verification tasks demonstrate the effectiveness of HIPPO, achieving a 4% improvement over various table reasoning models. Further analysis reveals that HIPPO not only enhances reasoning abilities based on unimodal table representations but also facilitates the extraction of crucial and distinct semantics from different modal representations. All data and codes are available at https://github.com/NEUIR/HIPPO.
LLM-QE: Improving Query Expansion by Aligning Large Language Models with Ranking Preferences
Feb 24, 2025



Query expansion plays a crucial role in information retrieval, which aims to bridge the semantic gap between queries and documents to improve matching performance. This paper introduces LLM-QE, a novel approach that leverages Large Language Models (LLMs) to generate document-based query expansions, thereby enhancing dense retrieval models. Unlike traditional methods, LLM-QE designs both rank-based and answer-based rewards and uses these reward models to optimize LLMs to align with the ranking preferences of both retrievers and LLMs, thus mitigating the hallucination of LLMs during query expansion. Our experiments on the zero-shot dense retrieval model, Contriever, demonstrate the effectiveness of LLM-QE, achieving an improvement of over 8%. Furthermore, by incorporating answer-based reward modeling, LLM-QE generates more relevant and precise information related to the documents, rather than simply producing redundant tokens to maximize rank-based rewards. Notably, LLM-QE also improves the training process of dense retrievers, achieving a more than 5% improvement after fine-tuning. All codes are available at https://github.com/NEUIR/LLM-QE.
PIP-KAG: Mitigating Knowledge Conflicts in Knowledge-Augmented Generation via Parametric Pruning
Feb 21, 2025



Knowledge-Augmented Generation (KAG) has shown great promise in updating the internal memory of Large Language Models (LLMs) by integrating external knowledge. However, KAG inevitably faces knowledge conflicts when the internal memory contradicts external information. Current approaches to mitigating these conflicts mainly focus on improving external knowledge utilization. However, these methods have shown only limited effectiveness in mitigating the knowledge conflict problem, as internal knowledge continues to influence the generation process of LLMs. In this paper, we propose a ParametrIc Pruning-based Knowledge-Augmented Generation (PIP-KAG) approach, which prunes internal knowledge of LLMs and incorporates a plug-and-play adaptation module to help LLMs better leverage external sources. Additionally, we construct the CoConflictQA benchmark based on the hallucination of LLMs to better evaluate contextual faithfulness during answering questions. Experimental results on CoConflictQA demonstrate that PIP-KAG significantly reduces knowledge conflicts and improves context fidelity. Notably, PIP-KAG reduces LLM's parameters by 13%, enhancing parameter efficiency in LLMs within the KAG framework. All codes are available at https://github.com/OpenBMB/PIP-KAG.
Learning More Effective Representations for Dense Retrieval through Deliberate Thinking Before Search
Feb 18, 2025



Recent dense retrievers usually thrive on the emergency capabilities of Large Language Models (LLMs), using them to encode queries and documents into an embedding space for retrieval. These LLM-based dense retrievers have shown promising performance across various retrieval scenarios. However, relying on a single embedding to represent documents proves less effective in capturing different perspectives of documents for matching. In this paper, we propose Deliberate Thinking based Dense Retriever (DEBATER), which enhances these LLM-based retrievers by enabling them to learn more effective document representations through a step-by-step thinking process. DEBATER introduces the Chain-of-Deliberation mechanism to iteratively optimize document representations using a continuous chain of thought. To consolidate information from various thinking steps, DEBATER also incorporates the Self Distillation mechanism, which identifies the most informative thinking steps and integrates them into a unified text embedding. Experimental results show that DEBATER significantly outperforms existing methods across several retrieval benchmarks, demonstrating superior accuracy and robustness. All codes are available at https://github.com/OpenBMB/DEBATER.
PathRAG: Pruning Graph-based Retrieval Augmented Generation with Relational Paths
Feb 18, 2025Retrieval-augmented generation (RAG) improves the response quality of large language models (LLMs) by retrieving knowledge from external databases. Typical RAG approaches split the text database into chunks, organizing them in a flat structure for efficient searches. To better capture the inherent dependencies and structured relationships across the text database, researchers propose to organize textual information into an indexing graph, known asgraph-based RAG. However, we argue that the limitation of current graph-based RAG methods lies in the redundancy of the retrieved information, rather than its insufficiency. Moreover, previous methods use a flat structure to organize retrieved information within the prompts, leading to suboptimal performance. To overcome these limitations, we propose PathRAG, which retrieves key relational paths from the indexing graph, and converts these paths into textual form for prompting LLMs. Specifically, PathRAG effectively reduces redundant information with flow-based pruning, while guiding LLMs to generate more logical and coherent responses with path-based prompting. Experimental results show that PathRAG consistently outperforms state-of-the-art baselines across six datasets and five evaluation dimensions. The code is available at the following link: https://github.com/BUPT-GAMMA/PathRAG
KBAlign: Efficient Self Adaptation on Specific Knowledge Bases
Nov 25, 2024



Humans can utilize techniques to quickly acquire knowledge from specific materials in advance, such as creating self-assessment questions, enabling us to achieving related tasks more efficiently. In contrast, large language models (LLMs) usually relies on retrieval-augmented generation to exploit knowledge materials in an instant manner, or requires external signals such as human preference data and stronger LLM annotations to conduct knowledge adaptation. To unleash the self-learning potential of LLMs, we propose KBAlign, an approach designed for efficient adaptation to downstream tasks involving knowledge bases. Our method utilizes iterative training with self-annotated data such as Q&A pairs and revision suggestions, enabling the model to grasp the knowledge content efficiently. Experimental results on multiple datasets demonstrate the effectiveness of our approach, significantly boosting model performance in downstream tasks that require specific knowledge at a low cost. Notably, our approach achieves over 90% of the performance improvement that can be obtained by using GPT-4-turbo annotation, while relying entirely on self-supervision. We release our experimental data, models, and process analyses to the community for further exploration (https://github.com/thunlp/KBAlign).