 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
Mar 31, 2025Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human preferences. While recent research has focused on algorithmic improvements, the importance of prompt-data construction has been overlooked. This paper addresses this gap by exploring data-driven bottlenecks in RLHF performance scaling, particularly reward hacking and decreasing response diversity. We introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. We also propose a novel prompt-selection method, Pre-PPO, to maintain response diversity and enhance learning effectiveness. Additionally, we find that prioritizing mathematical and coding tasks early in RLHF training significantly improves performance. Experiments across two model sizes validate our methods' effectiveness and scalability. Results show that RTV is most resistant to reward hacking, followed by GenRM with ground truth, and then GenRM with SFT Best-of-N responses. Our strategies enable rapid capture of subtle task-specific distinctions, leading to substantial improvements in overall RLHF performance. This work highlights the importance of careful data construction and provides practical methods to overcome performance barriers in RLHF.
CardiacMamba: A Multimodal RGB-RF Fusion Framework with State Space Models for Remote Physiological Measurement
Feb 19, 2025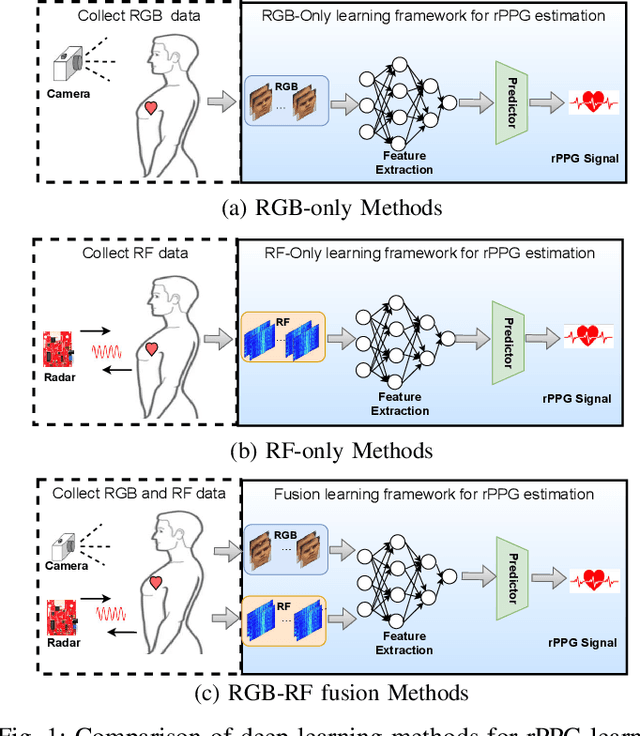
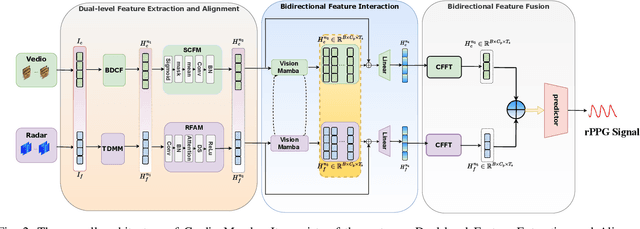
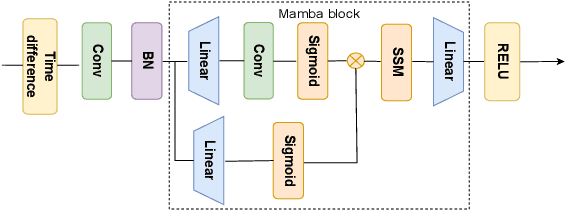
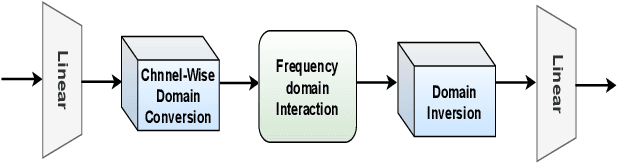
Heart rate (HR) estimation via remote photoplethysmography (rPPG) offers a non-invasive solution for health monitoring. However, traditional single-modality approaches (RGB or Radio Frequency (RF)) face challenges in balancing robustness and accuracy due to lighting variations, motion artifacts, and skin tone bias. In this paper, we propose CardiacMamba, a multimodal RGB-RF fusion framework that leverages the complementary strengths of both modalities. It introduces the Temporal Difference Mamba Module (TDMM) to capture dynamic changes in RF signals using timing differences between frames, enhancing the extraction of local and global features. Additionally, CardiacMamba employs a Bidirectional SSM for cross-modal alignment and a Channel-wise Fast Fourier Transform (CFFT) to effectively capture and refine the frequency domain characteristics of RGB and RF signals, ultimately improving heart rate estimation accuracy and periodicity detection. Extensive experiments on the EquiPleth dataset demonstrate state-of-the-art performance, achieving marked improvements in accuracy and robustness. CardiacMamba significantly mitigates skin tone bias, reducing performance disparities across demographic groups, and maintains resilience under missing-modality scenarios. By addressing critical challenges in fairness, adaptability, and precision, the framework advances rPPG technology toward reliable real-world deployment in healthcare. The codes are available at: https://github.com/WuZheng42/CardiacMamba.
Physics-Aware Robotic Palletization with Online Masking Inference
Feb 19, 2025The efficient planning of stacking boxes, especially in the online setting where the sequence of item arrivals is unpredictable, remains a critical challenge in modern warehouse and logistics management. Existing solutions often address box size variations, but overlook their intrinsic and physical properties, such as density and rigidity, which are crucial for real-world applications. We use reinforcement learning (RL) to solve this problem by employing action space masking to direct the RL policy toward valid actions. Unlike previous methods that rely on heuristic stability assessments which are difficult to assess in physical scenarios, our framework utilizes online learning to dynamically train the action space mask, eliminating the need for manual heuristic design. Extensive experiments demonstrate that our proposed method outperforms existing state-of-the-arts. Furthermore, we deploy our learned task planner in a real-world robotic palletizer, validating its practical applicability in operational settings.
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
Oct 28, 2024



Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024



Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization
Oct 11, 2024



Reinforcement Learning (RL) plays a crucial role in aligning large language models (LLMs) with human preferences and improving their ability to perform complex tasks. However, current approaches either require significant computational resources due to the use of multiple models and extensive online sampling for training (e.g., PPO) or are framed as bandit problems (e.g., DPO, DRO), which often struggle with multi-step reasoning tasks, such as math problem-solving and complex reasoning that involve long chains of thought. To overcome these limitations, we introduce Direct Q-function Optimization (DQO), which formulates the response generation process as a Markov Decision Process (MDP) and utilizes the soft actor-critic (SAC) framework to optimize a Q-function directly parameterized by the language model. The MDP formulation of DQO offers structural advantages over bandit-based methods, enabling more effective process supervision. Experimental results on two math problem-solving datasets, GSM8K and MATH, demonstrate that DQO outperforms previous methods, establishing it as a promising offline reinforcement learning approach for aligning language models.
Efficient Reinforcement Learning of Task Planners for Robotic Palletization through Iterative Action Masking Learning
Apr 07, 2024



The development of robotic systems for palletization in logistics scenarios is of paramount importance, addressing critical efficiency and precision demands in supply chain management. This paper investigates the application of Reinforcement Learning (RL) in enhancing task planning for such robotic systems. Confronted with the substantial challenge of a vast action space, which is a significant impediment to efficiently apply out-of-the-shelf RL methods, our study introduces a novel method of utilizing supervised learning to iteratively prune and manage the action space effectively. By reducing the complexity of the action space, our approach not only accelerates the learning phase but also ensures the effectiveness and reliability of the task planning in robotic palletization. The experimental results underscore the efficacy of this method, highlighting its potential in improving the performance of RL applications in complex and high-dimensional environments like logistics palletization.
DBPF: A Framework for Efficient and Robust Dynamic Bin-Picking
Mar 25, 2024



Efficiency and reliability are critical in robotic bin-picking as they directly impact the productivity of automated industrial processes. However, traditional approaches, demanding static objects and fixed collisions, lead to deployment limitations, operational inefficiencies, and process unreliability. This paper introduces a Dynamic Bin-Picking Framework (DBPF) that challenges traditional static assumptions. The DBPF endows the robot with the reactivity to pick multiple moving arbitrary objects while avoiding dynamic obstacles, such as the moving bin. Combined with scene-level pose generation, the proposed pose selection metric leverages the Tendency-Aware Manipulability Network optimizing suction pose determination. Heuristic task-specific designs like velocity-matching, dynamic obstacle avoidance, and the resight policy, enhance the picking success rate and reliability. Empirical experiments demonstrate the importance of these components. Our method achieves an average 84% success rate, surpassing the 60% of the most comparable baseline, crucially, with zero collisions. Further evaluations under diverse dynamic scenarios showcase DBPF's robust performance in dynamic bin-picking. Results suggest that our framework offers a promising solution for efficient and reliable robotic bin-picking under dynamics.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Efficient Sim-to-real Transfer of Contact-Rich Manipulation Skills with Online Admittance Residual Learning
Oct 16, 2023Learning contact-rich manipulation skills is essential. Such skills require the robots to interact with the environment with feasible manipulation trajectories and suitable compliance control parameters to enable safe and stable contact. However, learning these skills is challenging due to data inefficiency in the real world and the sim-to-real gap in simulation. In this paper, we introduce a hybrid offline-online framework to learn robust manipulation skills. We employ model-free reinforcement learning for the offline phase to obtain the robot motion and compliance control parameters in simulation \RV{with domain randomization}. Subsequently, in the online phase, we learn the residual of the compliance control parameters to maximize robot performance-related criteria with force sensor measurements in real time. To demonstrate the effectiveness and robustness of our approach, we provide comparative results against existing methods for assembly, pivoting, and screwing tasks.