 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generalization of Spiking Neural Networks Through Temporal Regularization
Jun 24, 2025Spiking Neural Networks (SNNs) have received widespread attention due to their event-driven and low-power characteristics, making them particularly effective for processing event-based neuromorphic data. Recent studies have shown that directly trained SNNs suffer from severe overfitting issues due to the limited scale of neuromorphic datasets and the gradient mismatching problem, which fundamentally constrain their generalization performance. In this paper, we propose a temporal regularization training (TRT) method by introducing a time-dependent regularization mechanism to enforce stronger constraints on early timesteps. We compare the performance of TRT with other state-of-the-art methods performance on datasets including CIFAR10/100, ImageNet100, DVS-CIFAR10, and N-Caltech101. To validate the effectiveness of TRT, we conducted ablation studies and analyses including loss landscape visualization and learning curve analysis, demonstrating that TRT can effectively mitigate overfitting and flatten the training loss landscape, thereby enhancing generalizability. Furthermore, we establish a theoretical interpretation of TRT's temporal regularization mechanism based on the results of Fisher information analysis. We analyze the temporal information dynamics inside SNNs by tracking Fisher information during the TRT training process, revealing the Temporal Information Concentration (TIC) phenomenon, where Fisher information progressively concentrates in early timesteps. The time-decaying regularization mechanism implemented in TRT effectively guides the network to learn robust features in early timesteps with rich information, thereby leading to significant improvements in model generalization. Code is available at https://github.com/ZBX05/Temporal-Regularization-Training.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025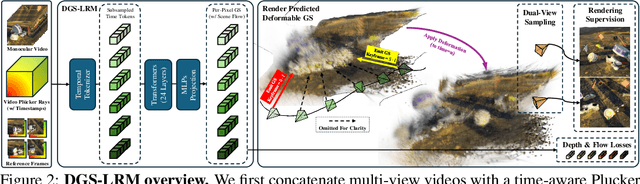
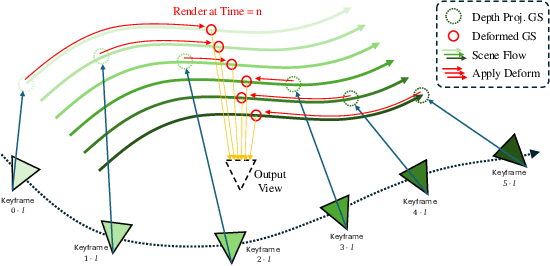
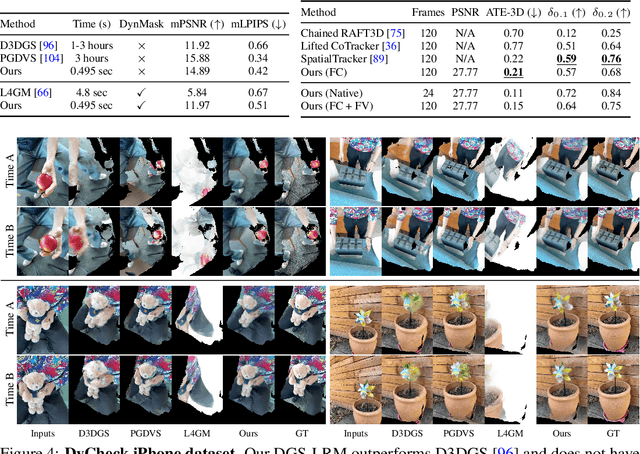

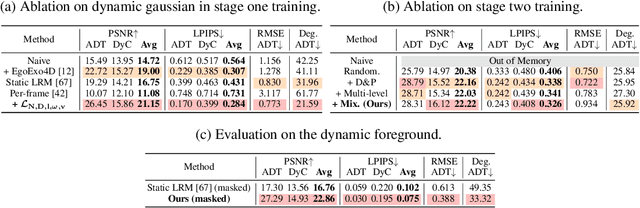
We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos
Jun 09, 2025


We propose 4DGT, a 4D Gaussian-based Transformer model for dynamic scene reconstruction, trained entirely on real-world monocular posed videos. Using 4D Gaussian as an inductive bias, 4DGT unifies static and dynamic components, enabling the modeling of complex, time-varying environments with varying object lifespans. We proposed a novel density control strategy in training, which enables our 4DGT to handle longer space-time input and remain efficient rendering at runtime. Our model processes 64 consecutive posed frames in a rolling-window fashion, predicting consistent 4D Gaussians in the scene. Unlike optimization-based methods, 4DGT performs purely feed-forward inference, reducing reconstruction time from hours to seconds and scaling effectively to long video sequences. Trained only on large-scale monocular posed video datasets, 4DGT can outperform prior Gaussian-based networks significantly in real-world videos and achieve on-par accuracy with optimization-based methods on cross-domain videos. Project page: https://4dgt.github.io
FreeTimeGS: Free Gaussian Primitives at Anytime and Anywhere for Dynamic Scene Reconstruction
Jun 06, 2025



This paper addresses the challenge of reconstructing dynamic 3D scenes with complex motions. Some recent works define 3D Gaussian primitives in the canonical space and use deformation fields to map canonical primitives to observation spaces, achieving real-time dynamic view synthesis. However, these methods often struggle to handle scenes with complex motions due to the difficulty of optimizing deformation fields. To overcome this problem, we propose FreeTimeGS, a novel 4D representation that allows Gaussian primitives to appear at arbitrary time and locations. In contrast to canonical Gaussian primitives, our representation possesses the strong flexibility, thus improving the ability to model dynamic 3D scenes. In addition, we endow each Gaussian primitive with an motion function, allowing it to move to neighboring regions over time, which reduces the temporal redundancy. Experiments results on several datasets show that the rendering quality of our method outperforms recent methods by a large margin. Project page: https://zju3dv.github.io/freetimegs/ .
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025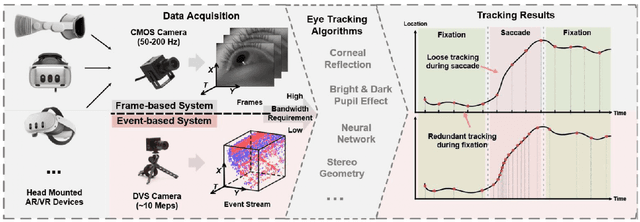
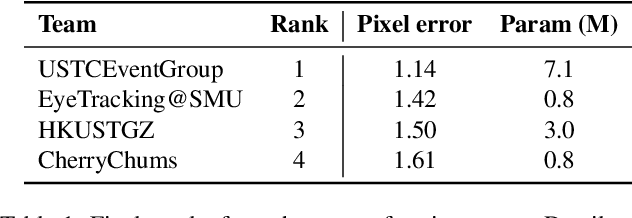
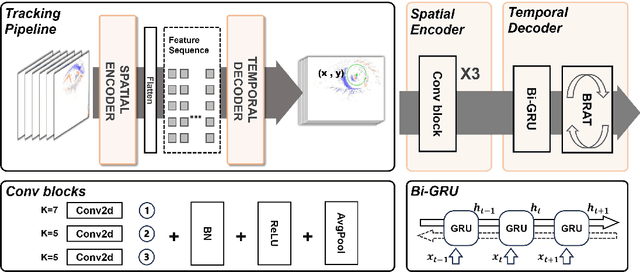

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Application of Deep Generative Models for Anomaly Detection in Complex Financial Transactions
Apr 21, 2025This study proposes an algorithm for detecting suspicious behaviors in large payment flows based on deep generative models. By combining Generative Adversarial Networks (GAN) and Variational Autoencoders (VAE), the algorithm is designed to detect abnormal behaviors in financial transactions. First, the GAN is used to generate simulated data that approximates normal payment flows. The discriminator identifies anomalous patterns in transactions, enabling the detection of potential fraud and money laundering behaviors. Second, a VAE is introduced to model the latent distribution of payment flows, ensuring that the generated data more closely resembles real transaction features, thus improving the model's detection accuracy. The method optimizes the generative capabilities of both GAN and VAE, ensuring that the model can effectively capture suspicious behaviors even in sparse data conditions. Experimental results show that the proposed method significantly outperforms traditional machine learning algorithms and other deep learning models across various evaluation metrics, especially in detecting rare fraudulent behaviors. Furthermore, this study provides a detailed comparison of performance in recognizing different transaction patterns (such as normal, money laundering, and fraud) in large payment flows, validating the advantages of generative models in handling complex financial data.
LLM-Sketch: Enhancing Network Sketches with LLM
Feb 11, 2025Network stream mining is fundamental to many network operations. Sketches, as compact data structures that offer low memory overhead with bounded accuracy, have emerged as a promising solution for network stream mining. Recent studies attempt to optimize sketches using machine learning; however, these approaches face the challenges of lacking adaptivity to dynamic networks and incurring high training costs. In this paper, we propose LLM-Sketch, based on the insight that fields beyond the flow IDs in packet headers can also help infer flow sizes. By using a two-tier data structure and separately recording large and small flows, LLM-Sketch improves accuracy while minimizing memory usage. Furthermore, it leverages fine-tuned large language models (LLMs) to reliably estimate flow sizes. We evaluate LLM-Sketch on three representative tasks, and the results demonstrate that LLM-Sketch outperforms state-of-the-art methods by achieving a $7.5\times$ accuracy improvement.
Scalable In-Context Learning on Tabular Data via Retrieval-Augmented Large Language Models
Feb 05, 2025



Recent studies have shown that large language models (LLMs), when customized with post-training on tabular data, can acquire general tabular in-context learning (TabICL) capabilities. These models are able to transfer effectively across diverse data schemas and different task domains. However, existing LLM-based TabICL approaches are constrained to few-shot scenarios due to the sequence length limitations of LLMs, as tabular instances represented in plain text consume substantial tokens. To address this limitation and enable scalable TabICL for any data size, we propose retrieval-augmented LLMs tailored to tabular data. Our approach incorporates a customized retrieval module, combined with retrieval-guided instruction-tuning for LLMs. This enables LLMs to effectively leverage larger datasets, achieving significantly improved performance across 69 widely recognized datasets and demonstrating promising scaling behavior. Extensive comparisons with state-of-the-art tabular models reveal that, while LLM-based TabICL still lags behind well-tuned numeric models in overall performance, it uncovers powerful algorithms under limited contexts, enhances ensemble diversity, and excels on specific datasets. These unique properties underscore the potential of language as a universal and accessible interface for scalable tabular data learning.
Leveraging Convolutional Neural Network-Transformer Synergy for Predictive Modeling in Risk-Based Applications
Dec 24, 2024



With the development of the financial industry, credit default prediction, as an important task in financial risk management, has received increasing attention. Traditional credit default prediction methods mostly rely on machine learning models, such as decision trees and random forests, but these methods have certain limitations in processing complex data and capturing potential risk patterns. To this end, this paper proposes a deep learning model based on the combination of convolutional neural networks (CNN) and Transformer for credit user default prediction. The model combines the advantages of CNN in local feature extraction with the ability of Transformer in global dependency modeling, effectively improving the accuracy and robustness of credit default prediction. Through experiments on public credit default datasets, the results show that the CNN+Transformer model outperforms traditional machine learning models, such as random forests and XGBoost, in multiple evaluation indicators such as accuracy, AUC, and KS value, demonstrating its powerful ability in complex financial data modeling. Further experimental analysis shows that appropriate optimizer selection and learning rate adjustment play a vital role in improving model performance. In addition, the ablation experiment of the model verifies the advantages of the combination of CNN and Transformer and proves the complementarity of the two in credit default prediction. This study provides a new idea for credit default prediction and provides strong support for risk assessment and intelligent decision-making in the financial field. Future research can further improve the prediction effect and generalization ability by introducing more unstructured data and improving the model architecture.
EnvGS: Modeling View-Dependent Appearance with Environment Gaussian
Dec 19, 2024



Reconstructing complex reflections in real-world scenes from 2D images is essential for achieving photorealistic novel view synthesis. Existing methods that utilize environment maps to model reflections from distant lighting often struggle with high-frequency reflection details and fail to account for near-field reflections. In this work, we introduce EnvGS, a novel approach that employs a set of Gaussian primitives as an explicit 3D representation for capturing reflections of environments. These environment Gaussian primitives are incorporated with base Gaussian primitives to model the appearance of the whole scene. To efficiently render these environment Gaussian primitives, we developed a ray-tracing-based renderer that leverages the GPU's RT core for fast rendering. This allows us to jointly optimize our model for high-quality reconstruction while maintaining real-time rendering speeds. Results from multiple real-world and synthetic datasets demonstrate that our method produces significantly more detailed reflections, achieving the best rendering quality in real-time novel view synthesis.