 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjection-Volume Fidelity Divergence: Diagnosing and Controlling Optimization Drift in Sparse-View 3D Gaussian Tomography
Jun 21, 2026Sparse-view computed tomography is a severely ill-posed inverse problem, where recent 3D Gaussian Splatting methods offer an efficient explicit representation for tomographic reconstruction. However, we find that projection-domain optimization can be misleading in this setting: the rendered projections may continue to improve while the reconstructed volume deteriorates. We identify this failure mode as Projection-Volume Fidelity Divergence (PVFD), a representation-level optimization drift caused by anisotropic Gaussian deformation and view-specific primitive co-adaptation under sparse Radon constraints. To characterize this behavior, we introduce geometry- and volume-level diagnostics that measure needle-like Gaussian degeneration and the stability of the voxelized density field. Based on these observations, we propose LADES, a ground-truth-free optimization controller for sparse-view Gaussian tomography. LADES combines Linearly Annealed Dropout, which applies strong stochastic masking in early training to disrupt premature primitive co-adaptation and gradually restores full capacity for structural consolidation, with Structure-Aware Early Stopping, which terminates densification according to the saturation of Gaussian population growth rather than validation PSNR. Experiments on sparse-view CT reconstruction show that LADES improves volumetric fidelity, suppresses structural degeneration, and substantially reduces training time while maintaining competitive projection accuracy. These results suggest that robust Gaussian-based tomography requires monitoring and controlling volumetric structure, rather than optimizing projection fit alone.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025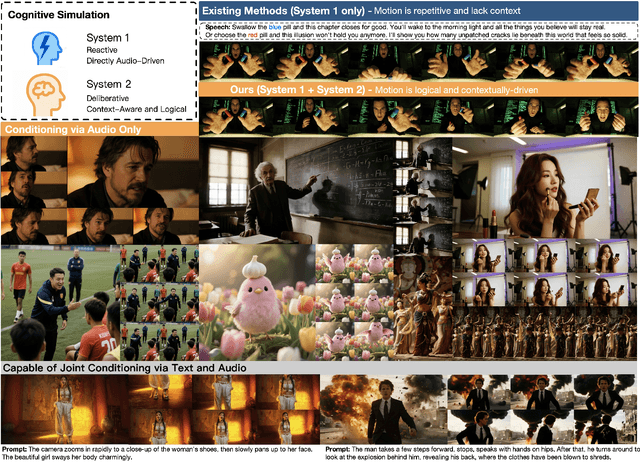
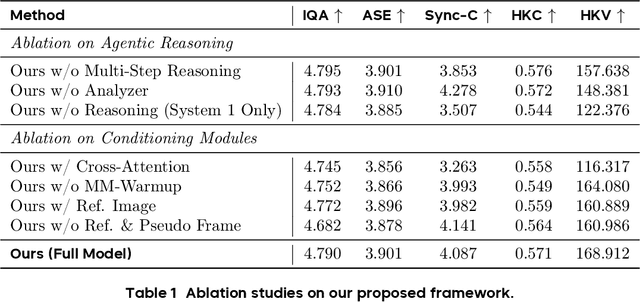
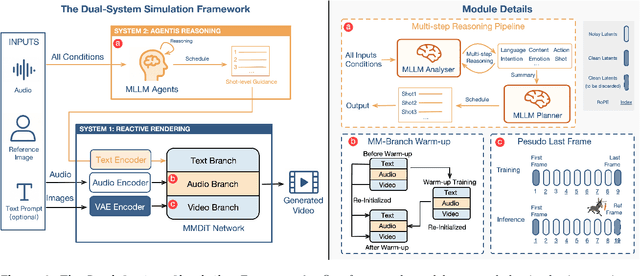

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
When Single Event Upset Meets Deep Neural Networks: Observations, Explorations, and Remedies
Sep 10, 2019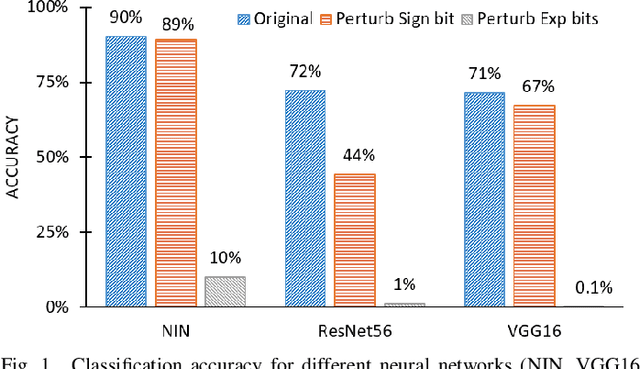
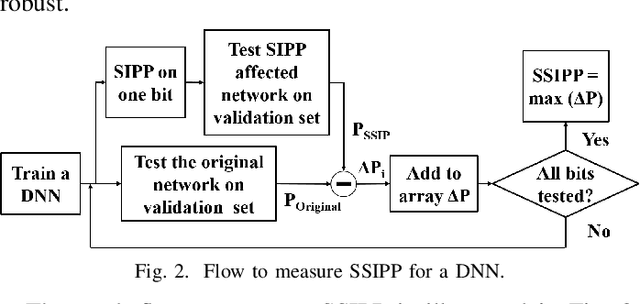
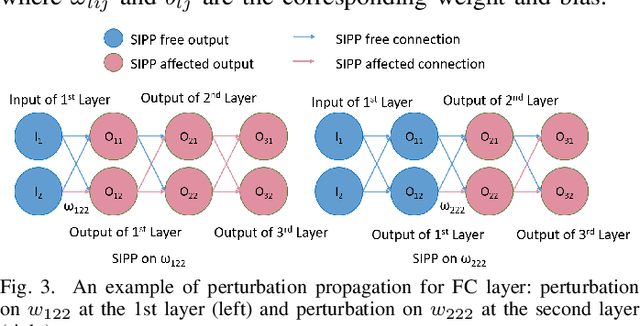
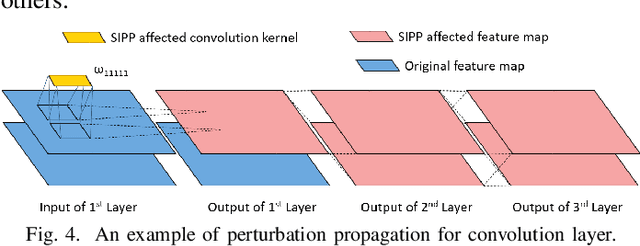
Deep Neural Network has proved its potential in various perception tasks and hence become an appealing option for interpretation and data processing in security sensitive systems. However, security-sensitive systems demand not only high perception performance, but also design robustness under various circumstances. Unlike prior works that study network robustness from software level, we investigate from hardware perspective about the impact of Single Event Upset (SEU) induced parameter perturbation (SIPP) on neural networks. We systematically define the fault models of SEU and then provide the definition of sensitivity to SIPP as the robustness measure for the network. We are then able to analytically explore the weakness of a network and summarize the key findings for the impact of SIPP on different types of bits in a floating point parameter, layer-wise robustness within the same network and impact of network depth. Based on those findings, we propose two remedy solutions to protect DNNs from SIPPs, which can mitigate accuracy degradation from 28% to 0.27% for ResNet with merely 0.24-bit SRAM area overhead per parameter.