 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning
Jan 29, 2026Character image animation aims to synthesize high-fidelity videos by transferring motion from a driving sequence to a static reference image. Despite recent advancements, existing methods suffer from two fundamental challenges: (1) suboptimal motion injection strategies that lead to a trade-off between identity preservation and motion consistency, manifesting as a "see-saw", and (2) an over-reliance on explicit pose priors (e.g., skeletons), which inadequately capture intricate dynamics and hinder generalization to arbitrary, non-humanoid characters. To address these challenges, we present DreamActor-M2, a universal animation framework that reimagines motion conditioning as an in-context learning problem. Our approach follows a two-stage paradigm. First, we bridge the input modality gap by fusing reference appearance and motion cues into a unified latent space, enabling the model to jointly reason about spatial identity and temporal dynamics by leveraging the generative prior of foundational models. Second, we introduce a self-bootstrapped data synthesis pipeline that curates pseudo cross-identity training pairs, facilitating a seamless transition from pose-dependent control to direct, end-to-end RGB-driven animation. This strategy significantly enhances generalization across diverse characters and motion scenarios. To facilitate comprehensive evaluation, we further introduce AW Bench, a versatile benchmark encompassing a wide spectrum of characters types and motion scenarios. Extensive experiments demonstrate that DreamActor-M2 achieves state-of-the-art performance, delivering superior visual fidelity and robust cross-domain generalization. Project Page: https://grisoon.github.io/DreamActor-M2/
OmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025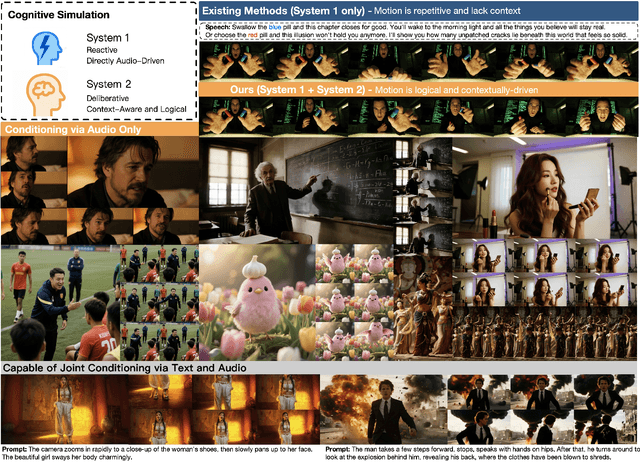
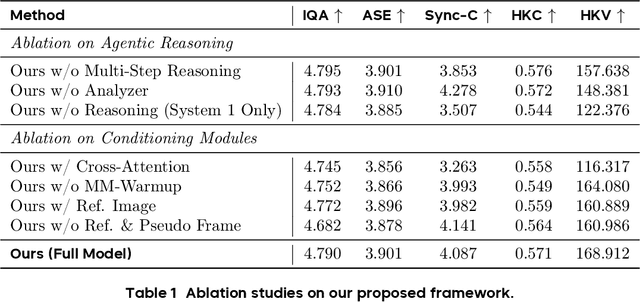
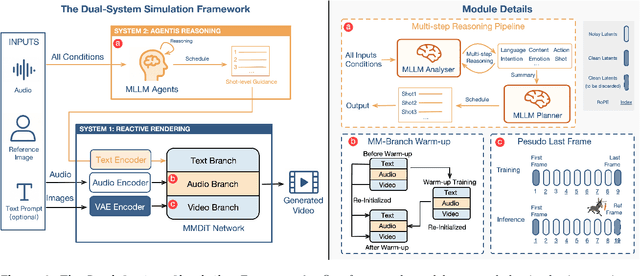

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
Image Reconstruction with B0 Inhomogeneity using an Interpretable Deep Unrolled Network on an Open-bore MRI-Linac
Apr 15, 2024



MRI-Linac systems require fast image reconstruction with high geometric fidelity to localize and track tumours for radiotherapy treatments. However, B0 field inhomogeneity distortions and slow MR acquisition potentially limit the quality of the image guidance and tumour treatments. In this study, we develop an interpretable unrolled network, referred to as RebinNet, to reconstruct distortion-free images from B0 inhomogeneity-corrupted k-space for fast MRI-guided radiotherapy applications. RebinNet includes convolutional neural network (CNN) blocks to perform image regularizations and nonuniform fast Fourier Transform (NUFFT) modules to incorporate B0 inhomogeneity information. The RebinNet was trained on a publicly available MR dataset from eleven healthy volunteers for both fully sampled and subsampled acquisitions. Grid phantom and human brain images acquired from an open-bore 1T MRI-Linac scanner were used to evaluate the performance of the proposed network. The RebinNet was compared with the conventional regularization algorithm and our recently developed UnUNet method in terms of root mean squared error (RMSE), structural similarity (SSIM), residual distortions, and computation time. Imaging results demonstrated that the RebinNet reconstructed images with lowest RMSE (<0.05) and highest SSIM (>0.92) at four-time acceleration for simulated brain images. The RebinNet could better preserve structural details and substantially improve the computational efficiency (ten-fold faster) compared to the conventional regularization methods, and had better generalization ability than the UnUNet method. The proposed RebinNet can achieve rapid image reconstruction and overcome the B0 inhomogeneity distortions simultaneously, which would facilitate accurate and fast image guidance in radiotherapy treatments.