 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermoSplat: Cross-Modal 3D Gaussian Splatting with Feature Modulation and Geometry Decoupling
Jan 22, 2026Multi-modal scene reconstruction integrating RGB and thermal infrared data is essential for robust environmental perception across diverse lighting and weather conditions. However, extending 3D Gaussian Splatting (3DGS) to multi-spectral scenarios remains challenging. Current approaches often struggle to fully leverage the complementary information of multi-modal data, typically relying on mechanisms that either tend to neglect cross-modal correlations or leverage shared representations that fail to adaptively handle the complex structural correlations and physical discrepancies between spectrums. To address these limitations, we propose ThermoSplat, a novel framework that enables deep spectral-aware reconstruction through active feature modulation and adaptive geometry decoupling. First, we introduce a Cross-Modal FiLM Modulation mechanism that dynamically conditions shared latent features on thermal structural priors, effectively guiding visible texture synthesis with reliable cross-modal geometric cues. Second, to accommodate modality-specific geometric inconsistencies, we propose a Modality-Adaptive Geometric Decoupling scheme that learns independent opacity offsets and executes an independent rasterization pass for the thermal branch. Additionally, a hybrid rendering pipeline is employed to integrate explicit Spherical Harmonics with implicit neural decoding, ensuring both semantic consistency and high-frequency detail preservation. Extensive experiments on the RGBT-Scenes dataset demonstrate that ThermoSplat achieves state-of-the-art rendering quality across both visible and thermal spectrums.
SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Jun 11, 2025Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
Parametric Gaussian Human Model: Generalizable Prior for Efficient and Realistic Human Avatar Modeling
Jun 07, 2025Photorealistic and animatable human avatars are a key enabler for virtual/augmented reality, telepresence, and digital entertainment. While recent advances in 3D Gaussian Splatting (3DGS) have greatly improved rendering quality and efficiency, existing methods still face fundamental challenges, including time-consuming per-subject optimization and poor generalization under sparse monocular inputs. In this work, we present the Parametric Gaussian Human Model (PGHM), a generalizable and efficient framework that integrates human priors into 3DGS for fast and high-fidelity avatar reconstruction from monocular videos. PGHM introduces two core components: (1) a UV-aligned latent identity map that compactly encodes subject-specific geometry and appearance into a learnable feature tensor; and (2) a disentangled Multi-Head U-Net that predicts Gaussian attributes by decomposing static, pose-dependent, and view-dependent components via conditioned decoders. This design enables robust rendering quality under challenging poses and viewpoints, while allowing efficient subject adaptation without requiring multi-view capture or long optimization time. Experiments show that PGHM is significantly more efficient than optimization-from-scratch methods, requiring only approximately 20 minutes per subject to produce avatars with comparable visual quality, thereby demonstrating its practical applicability for real-world monocular avatar creation.
3D Gaussian Parametric Head Model
Jul 21, 2024



Creating high-fidelity 3D human head avatars is crucial for applications in VR/AR, telepresence, digital human interfaces, and film production. Recent advances have leveraged morphable face models to generate animated head avatars from easily accessible data, representing varying identities and expressions within a low-dimensional parametric space. However, existing methods often struggle with modeling complex appearance details, e.g., hairstyles and accessories, and suffer from low rendering quality and efficiency. This paper introduces a novel approach, 3D Gaussian Parametric Head Model, which employs 3D Gaussians to accurately represent the complexities of the human head, allowing precise control over both identity and expression. Additionally, it enables seamless face portrait interpolation and the reconstruction of detailed head avatars from a single image. Unlike previous methods, the Gaussian model can handle intricate details, enabling realistic representations of varying appearances and complex expressions. Furthermore, this paper presents a well-designed training framework to ensure smooth convergence, providing a guarantee for learning the rich content. Our method achieves high-quality, photo-realistic rendering with real-time efficiency, making it a valuable contribution to the field of parametric head models.
LayGA: Layered Gaussian Avatars for Animatable Clothing Transfer
May 12, 2024



Animatable clothing transfer, aiming at dressing and animating garments across characters, is a challenging problem. Most human avatar works entangle the representations of the human body and clothing together, which leads to difficulties for virtual try-on across identities. What's worse, the entangled representations usually fail to exactly track the sliding motion of garments. To overcome these limitations, we present Layered Gaussian Avatars (LayGA), a new representation that formulates body and clothing as two separate layers for photorealistic animatable clothing transfer from multi-view videos. Our representation is built upon the Gaussian map-based avatar for its excellent representation power of garment details. However, the Gaussian map produces unstructured 3D Gaussians distributed around the actual surface. The absence of a smooth explicit surface raises challenges in accurate garment tracking and collision handling between body and garments. Therefore, we propose two-stage training involving single-layer reconstruction and multi-layer fitting. In the single-layer reconstruction stage, we propose a series of geometric constraints to reconstruct smooth surfaces and simultaneously obtain the segmentation between body and clothing. Next, in the multi-layer fitting stage, we train two separate models to represent body and clothing and utilize the reconstructed clothing geometries as 3D supervision for more accurate garment tracking. Furthermore, we propose geometry and rendering layers for both high-quality geometric reconstruction and high-fidelity rendering. Overall, the proposed LayGA realizes photorealistic animations and virtual try-on, and outperforms other baseline methods. Our project page is https://jsnln.github.io/layga/index.html.
CaPhy: Capturing Physical Properties for Animatable Human Avatars
Aug 11, 2023



We present CaPhy, a novel method for reconstructing animatable human avatars with realistic dynamic properties for clothing. Specifically, we aim for capturing the geometric and physical properties of the clothing from real observations. This allows us to apply novel poses to the human avatar with physically correct deformations and wrinkles of the clothing. To this end, we combine unsupervised training with physics-based losses and 3D-supervised training using scanned data to reconstruct a dynamic model of clothing that is physically realistic and conforms to the human scans. We also optimize the physical parameters of the underlying physical model from the scans by introducing gradient constraints of the physics-based losses. In contrast to previous work on 3D avatar reconstruction, our method is able to generalize to novel poses with realistic dynamic cloth deformations. Experiments on several subjects demonstrate that our method can estimate the physical properties of the garments, resulting in superior quantitative and qualitative results compared with previous methods.
DeepCloth: Neural Garment Representation for Shape and Style Editing
Nov 30, 2020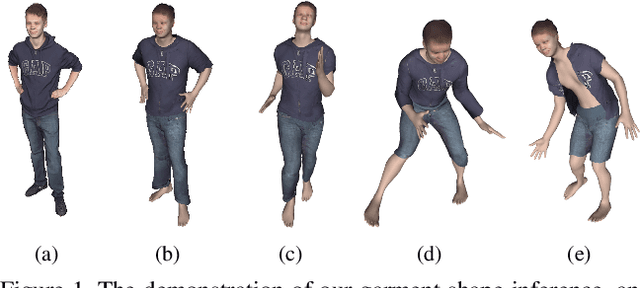
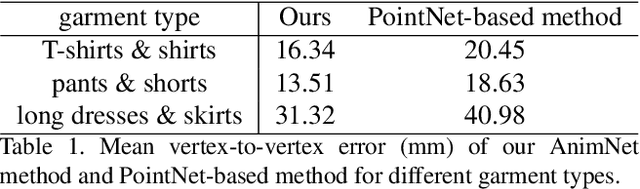
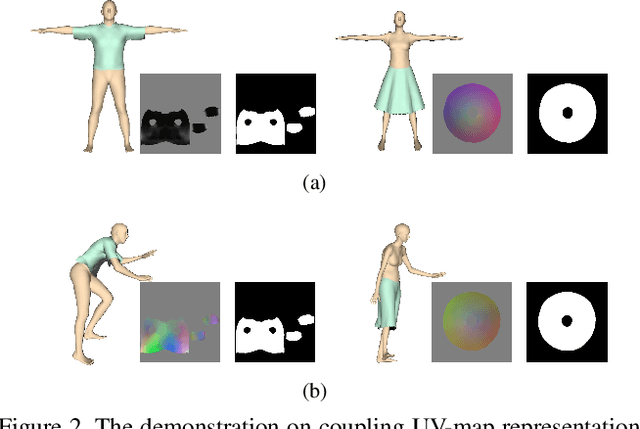
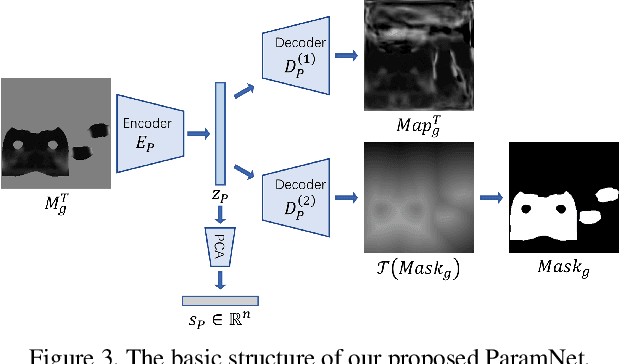
Garment representation, animation and editing is a challenging topic in the area of computer vision and graphics. Existing methods cannot perform smooth and reasonable garment transition under different shape styles and topologies. In this work, we introduce a novel method, termed as DeepCloth, to establish a unified garment representation framework enabling free and smooth garment style transition. Our key idea is to represent garment geometry by a "UV-position map with mask", which potentially allows the description of various garments with different shapes and topologies. Furthermore, we learn a continuous feature space mapped from the above UV space, enabling garment shape editing and transition by controlling the garment features. Finally, we demonstrate applications of garment animation, reconstruction and editing based on our neural garment representation and encoding method. To conclude, with the proposed DeepCloth, we move a step forward on establishing a more flexible and general 3D garment digitization framework. Experiments demonstrate that our method can achieve the state-of-the-art garment modeling results compared with the previous methods.
MulayCap: Multi-layer Human Performance Capture Using A Monocular Video Camera
Apr 19, 2020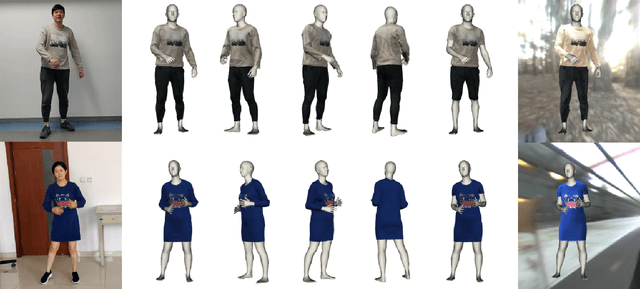
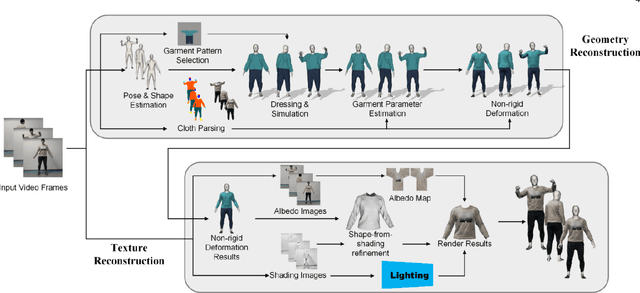
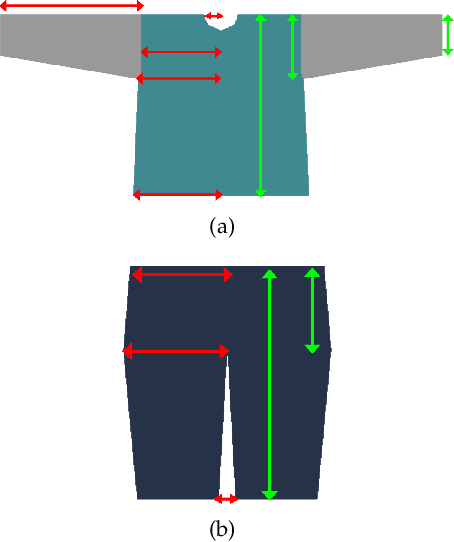
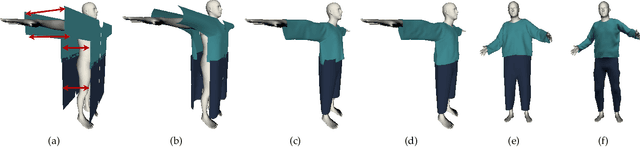
We introduce MulayCap, a novel human performance capture method using a monocular video camera without the need for pre-scanning. The method uses "multi-layer" representations for geometry reconstruction and texture rendering, respectively. For geometry reconstruction, we decompose the clothed human into multiple geometry layers, namely a body mesh layer and a garment piece layer. The key technique behind is a Garment-from-Video (GfV) method for optimizing the garment shape and reconstructing the dynamic cloth to fit the input video sequence, based on a cloth simulation model which is effectively solved with gradient descent. For texture rendering, we decompose each input image frame into a shading layer and an albedo layer, and propose a method for fusing a fixed albedo map and solving for detailed garment geometry using the shading layer. Compared with existing single view human performance capture systems, our "multi-layer" approach bypasses the tedious and time consuming scanning step for obtaining a human specific mesh template. Experimental results demonstrate that MulayCap produces realistic rendering of dynamically changing details that has not been achieved in any previous monocular video camera systems. Benefiting from its fully semantic modeling, MulayCap can be applied to various important editing applications, such as cloth editing, re-targeting, relighting, and AR applications.