 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrixVT: Efficient Multi-Camera to BEV Transformation for 3D Perception
Nov 19, 2022



This paper proposes an efficient multi-camera to Bird's-Eye-View (BEV) view transformation method for 3D perception, dubbed MatrixVT. Existing view transformers either suffer from poor transformation efficiency or rely on device-specific operators, hindering the broad application of BEV models. In contrast, our method generates BEV features efficiently with only convolutions and matrix multiplications (MatMul). Specifically, we propose describing the BEV feature as the MatMul of image feature and a sparse Feature Transporting Matrix (FTM). A Prime Extraction module is then introduced to compress the dimension of image features and reduce FTM's sparsity. Moreover, we propose the Ring \& Ray Decomposition to replace the FTM with two matrices and reformulate our pipeline to reduce calculation further. Compared to existing methods, MatrixVT enjoys a faster speed and less memory footprint while remaining deploy-friendly. Extensive experiments on the nuScenes benchmark demonstrate that our method is highly efficient but obtains results on par with the SOTA method in object detection and map segmentation tasks
BEVStereo: Enhancing Depth Estimation in Multi-view 3D Object Detection with Dynamic Temporal Stereo
Sep 21, 2022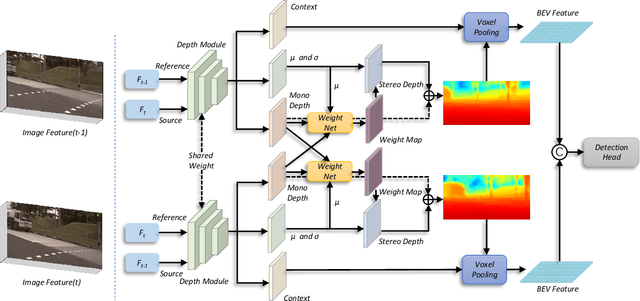

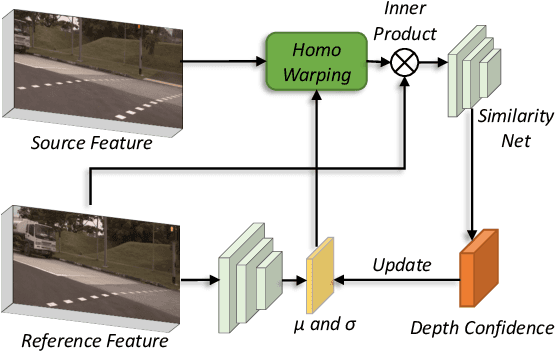
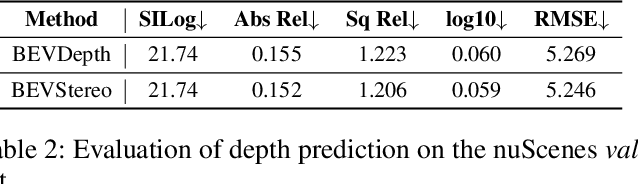
Bounded by the inherent ambiguity of depth perception, contemporary camera-based 3D object detection methods fall into the performance bottleneck. Intuitively, leveraging temporal multi-view stereo (MVS) technology is the natural knowledge for tackling this ambiguity. However, traditional attempts of MVS are flawed in two aspects when applying to 3D object detection scenes: 1) The affinity measurement among all views suffers expensive computation cost; 2) It is difficult to deal with outdoor scenarios where objects are often mobile. To this end, we introduce an effective temporal stereo method to dynamically select the scale of matching candidates, enable to significantly reduce computation overhead. Going one step further, we design an iterative algorithm to update more valuable candidates, making it adaptive to moving candidates. We instantiate our proposed method to multi-view 3D detector, namely BEVStereo. BEVStereo achieves the new state-of-the-art performance (i.e., 52.5% mAP and 61.0% NDS) on the camera-only track of nuScenes dataset. Meanwhile, extensive experiments reflect our method can deal with complex outdoor scenarios better than contemporary MVS approaches. Codes have been released at https://github.com/Megvii-BaseDetection/BEVStereo.
Quality Matters: Embracing Quality Clues for Robust 3D Multi-Object Tracking
Aug 23, 2022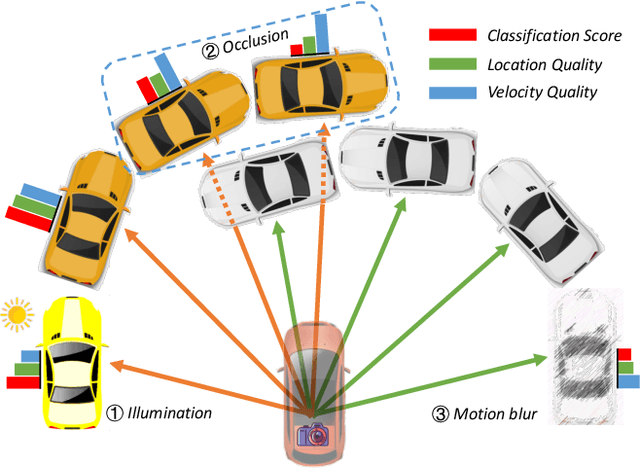
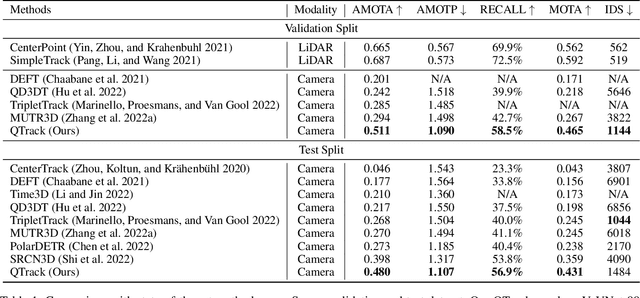

3D Multi-Object Tracking (MOT) has achieved tremendous achievement thanks to the rapid development of 3D object detection and 2D MOT. Recent advanced works generally employ a series of object attributes, e.g., position, size, velocity, and appearance, to provide the clues for the association in 3D MOT. However, these cues may not be reliable due to some visual noise, such as occlusion and blur, leading to tracking performance bottleneck. To reveal the dilemma, we conduct extensive empirical analysis to expose the key bottleneck of each clue and how they correlate with each other. The analysis results motivate us to efficiently absorb the merits among all cues, and adaptively produce an optimal tacking manner. Specifically, we present Location and Velocity Quality Learning, which efficiently guides the network to estimate the quality of predicted object attributes. Based on these quality estimations, we propose a quality-aware object association (QOA) strategy to leverage the quality score as an important reference factor for achieving robust association. Despite its simplicity, extensive experiments indicate that the proposed strategy significantly boosts tracking performance by 2.2% AMOTA and our method outperforms all existing state-of-the-art works on nuScenes by a large margin. Moreover, QTrack achieves 48.0% and 51.1% AMOTA tracking performance on the nuScenes validation and test sets, which significantly reduces the performance gap between pure camera and LiDAR based trackers.
STS: Surround-view Temporal Stereo for Multi-view 3D Detection
Aug 22, 2022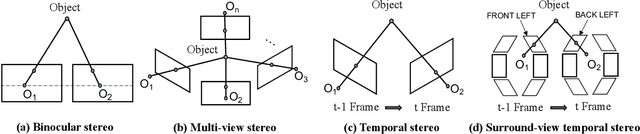
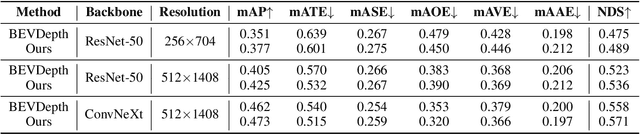
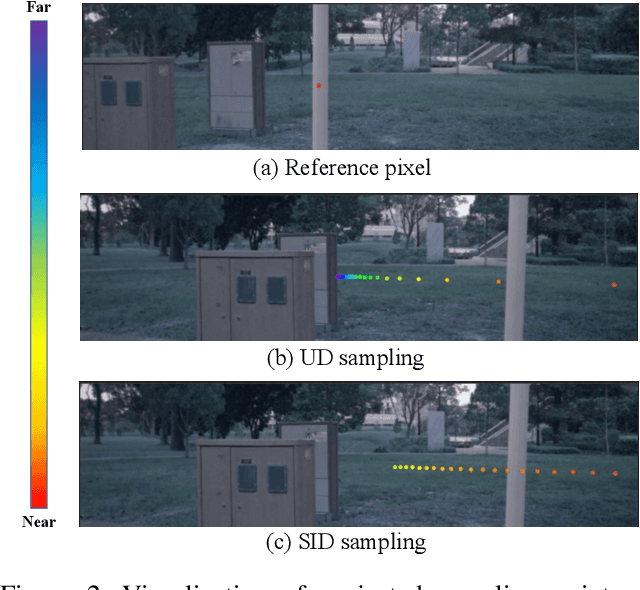
Learning accurate depth is essential to multi-view 3D object detection. Recent approaches mainly learn depth from monocular images, which confront inherent difficulties due to the ill-posed nature of monocular depth learning. Instead of using a sole monocular depth method, in this work, we propose a novel Surround-view Temporal Stereo (STS) technique that leverages the geometry correspondence between frames across time to facilitate accurate depth learning. Specifically, we regard the field of views from all cameras around the ego vehicle as a unified view, namely surroundview, and conduct temporal stereo matching on it. The resulting geometrical correspondence between different frames from STS is utilized and combined with the monocular depth to yield final depth prediction. Comprehensive experiments on nuScenes show that STS greatly boosts 3D detection ability, notably for medium and long distance objects. On BEVDepth with ResNet-50 backbone, STS improves mAP and NDS by 2.6% and 1.4%, respectively. Consistent improvements are observed when using a larger backbone and a larger image resolution, demonstrating its effectiveness
PersDet: Monocular 3D Detection in Perspective Bird's-Eye-View
Aug 19, 2022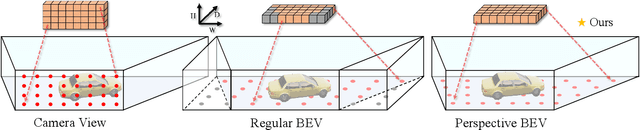
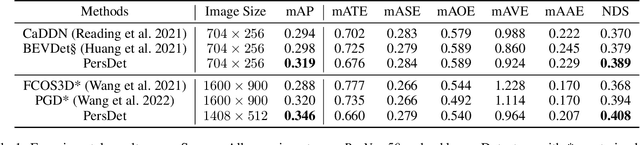
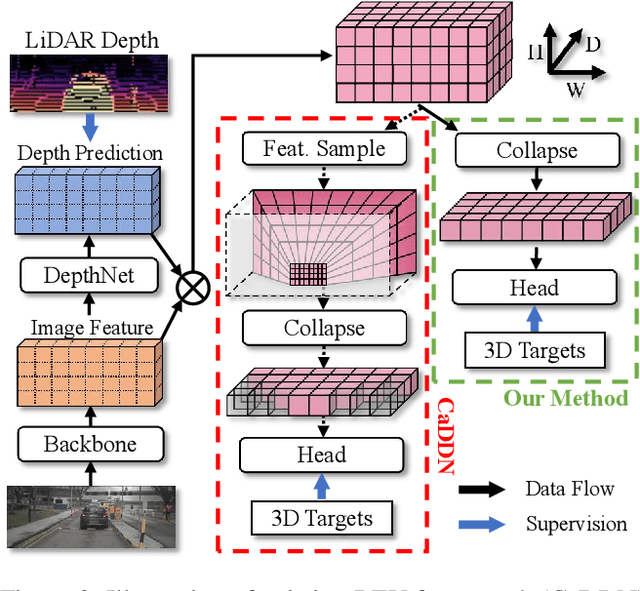
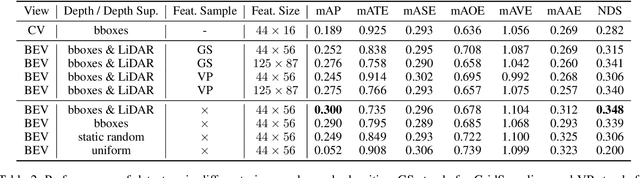
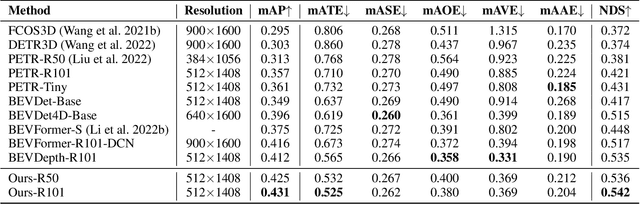
Currently, detecting 3D objects in Bird's-Eye-View (BEV) is superior to other 3D detectors for autonomous driving and robotics. However, transforming image features into BEV necessitates special operators to conduct feature sampling. These operators are not supported on many edge devices, bringing extra obstacles when deploying detectors. To address this problem, we revisit the generation of BEV representation and propose detecting objects in perspective BEV -- a new BEV representation that does not require feature sampling. We demonstrate that perspective BEV features can likewise enjoy the benefits of the BEV paradigm. Moreover, the perspective BEV improves detection performance by addressing issues caused by feature sampling. We propose PersDet for high-performance object detection in perspective BEV space based on this discovery. While implementing a simple and memory-efficient structure, PersDet outperforms existing state-of-the-art monocular methods on the nuScenes benchmark, reaching 34.6% mAP and 40.8% NDS when using ResNet-50 as the backbone.
DBQ-SSD: Dynamic Ball Query for Efficient 3D Object Detection
Jul 22, 2022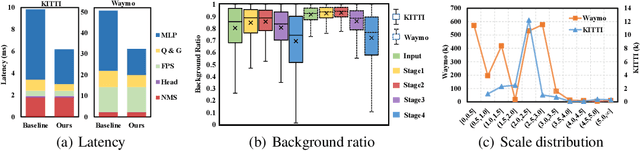
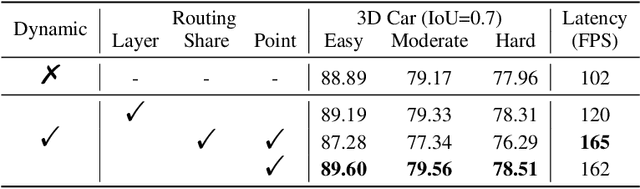
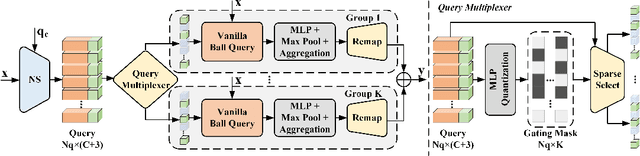
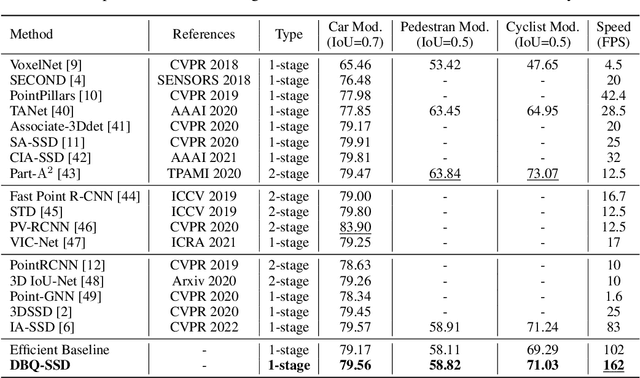
Many point-based 3D detectors adopt point-feature sampling strategies to drop some points for efficient inference. These strategies are typically based on fixed and handcrafted rules, making difficult to handle complicated scenes. Different from them, we propose a Dynamic Ball Query (DBQ) network to adaptively select a subset of input points according to the input features, and assign the feature transform with suitable receptive field for each selected point. It can be embedded into some state-of-the-art 3D detectors and trained in an end-to-end manner, which significantly reduces the computational cost. Extensive experiments demonstrate that our method can reduce latency by 30%-60% on KITTI and Waymo datasets. Specifically, the inference speed of our detector can reach 162 FPS and 30 FPS with negligible performance degradation on KITTI and Waymo datasets, respectively.
StreamYOLO: Real-time Object Detection for Streaming Perception
Jul 21, 2022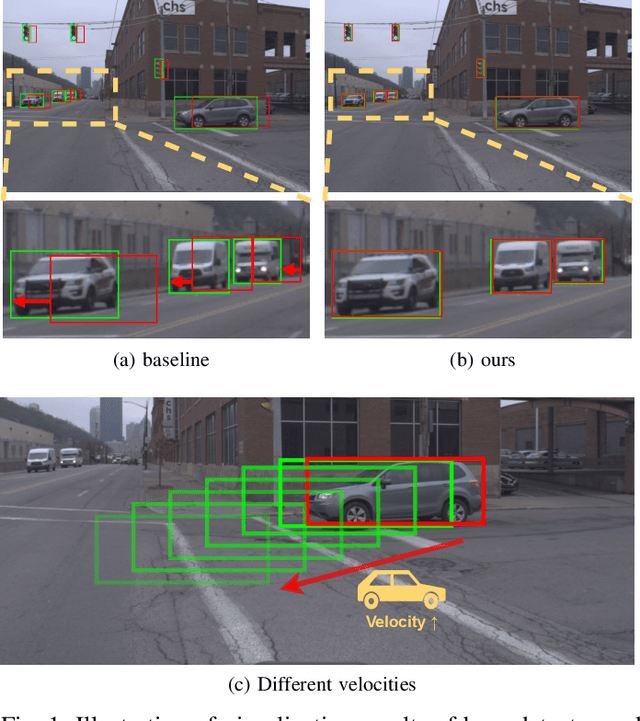
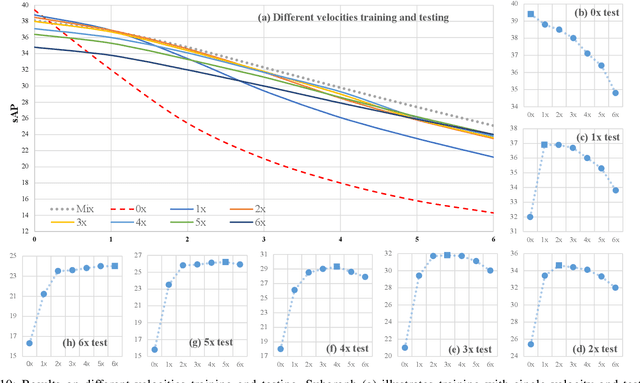
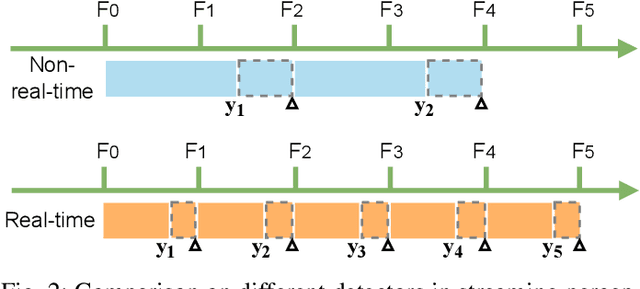
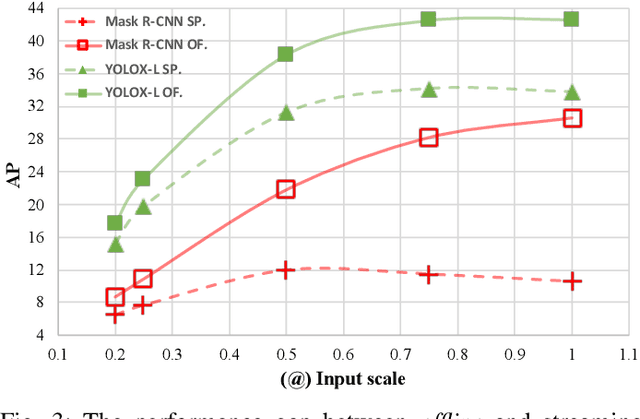
The perceptive models of autonomous driving require fast inference within a low latency for safety. While existing works ignore the inevitable environmental changes after processing, streaming perception jointly evaluates the latency and accuracy into a single metric for video online perception, guiding the previous works to search trade-offs between accuracy and speed. In this paper, we explore the performance of real time models on this metric and endow the models with the capacity of predicting the future, significantly improving the results for streaming perception. Specifically, we build a simple framework with two effective modules. One is a Dual Flow Perception module (DFP). It consists of dynamic flow and static flow in parallel to capture moving tendency and basic detection feature, respectively. Trend Aware Loss (TAL) is the other module which adaptively generates loss weight for each object with its moving speed. Realistically, we consider multiple velocities driving scene and further propose Velocity-awared streaming AP (VsAP) to jointly evaluate the accuracy. In this realistic setting, we design a efficient mix-velocity training strategy to guide detector perceive any velocities. Our simple method achieves the state-of-the-art performance on Argoverse-HD dataset and improves the sAP and VsAP by 4.7% and 8.2% respectively compared to the strong baseline, validating its effectiveness.
Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
Jul 19, 2022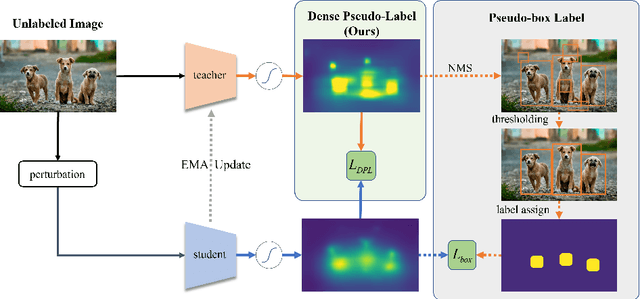
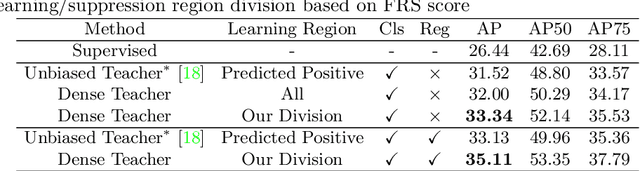
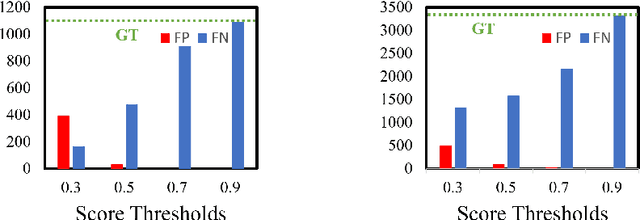
To date, the most powerful semi-supervised object detectors (SS-OD) are based on pseudo-boxes, which need a sequence of post-processing with fine-tuned hyper-parameters. In this work, we propose replacing the sparse pseudo-boxes with the dense prediction as a united and straightforward form of pseudo-label. Compared to the pseudo-boxes, our Dense Pseudo-Label (DPL) does not involve any post-processing method, thus retaining richer information. We also introduce a region selection technique to highlight the key information while suppressing the noise carried by dense labels. We name our proposed SS-OD algorithm that leverages the DPL as Dense Teacher. On COCO and VOC, Dense Teacher shows superior performance under various settings compared with the pseudo-box-based methods.
DSPNet: Towards Slimmable Pretrained Networks based on Discriminative Self-supervised Learning
Jul 13, 2022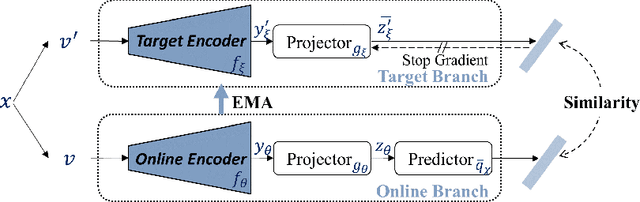
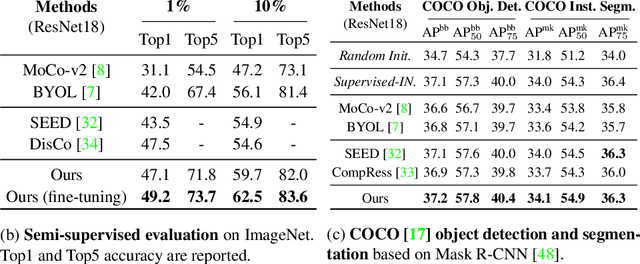
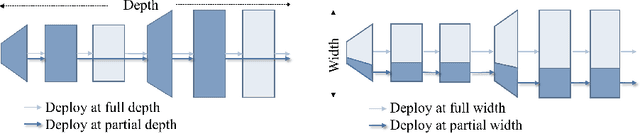
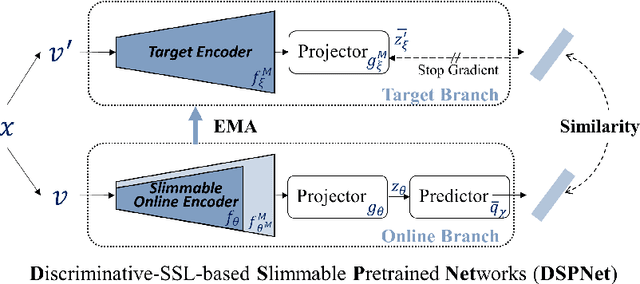
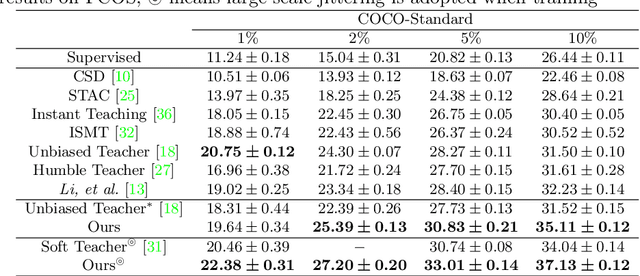
Self-supervised learning (SSL) has achieved promising downstream performance. However, when facing various resource budgets in real-world applications, it costs a huge computation burden to pretrain multiple networks of various sizes one by one. In this paper, we propose Discriminative-SSL-based Slimmable Pretrained Networks (DSPNet), which can be trained at once and then slimmed to multiple sub-networks of various sizes, each of which faithfully learns good representation and can serve as good initialization for downstream tasks with various resource budgets. Specifically, we extend the idea of slimmable networks to a discriminative SSL paradigm, by integrating SSL and knowledge distillation gracefully. We show comparable or improved performance of DSPNet on ImageNet to the networks individually pretrained one by one under the linear evaluation and semi-supervised evaluation protocols, while reducing large training cost. The pretrained models also generalize well on downstream detection and segmentation tasks. Code will be made public.
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
Jun 21, 2022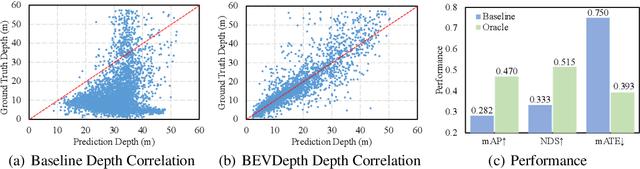
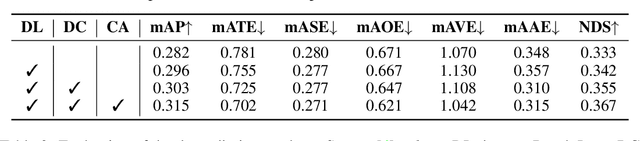
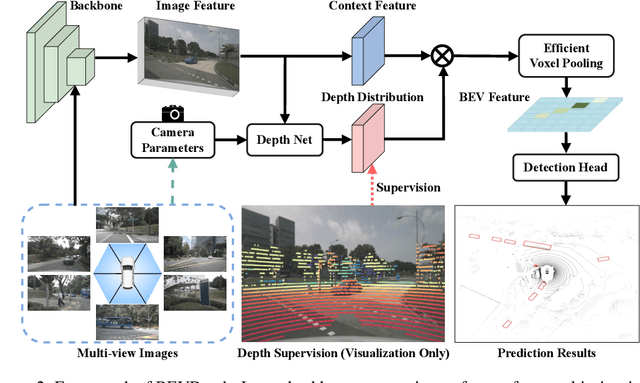
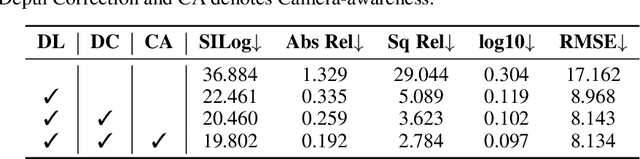
In this research, we propose a new 3D object detector with a trustworthy depth estimation, dubbed BEVDepth, for camera-based Bird's-Eye-View (BEV) 3D object detection. By a thorough analysis of recent approaches, we discover that the depth estimation is implicitly learned without camera information, making it the de-facto fake-depth for creating the following pseudo point cloud. BEVDepth gets explicit depth supervision utilizing encoded intrinsic and extrinsic parameters. A depth correction sub-network is further introduced to counteract projecting-induced disturbances in depth ground truth. To reduce the speed bottleneck while projecting features from image-view into BEV using estimated depth, a quick view-transform operation is also proposed. Besides, our BEVDepth can be easily extended with input from multi-frame. Without any bells and whistles, BEVDepth achieves the new state-of-the-art 60.0% NDS on the challenging nuScenes test set while maintaining high efficiency. For the first time, the performance gap between the camera and LiDAR is largely reduced within 10% NDS.