 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum a Posteriori Policy Optimisation
Jun 14, 2018
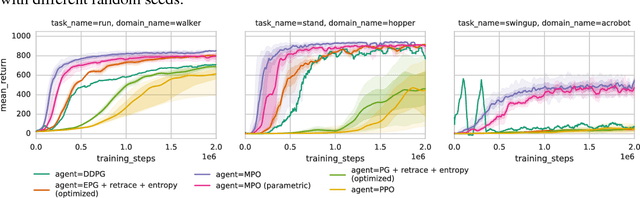
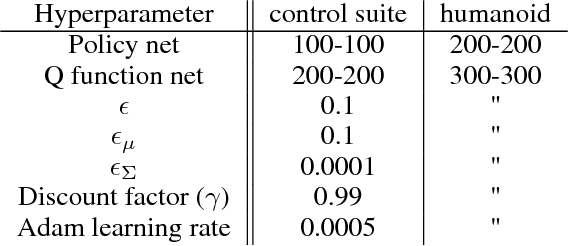
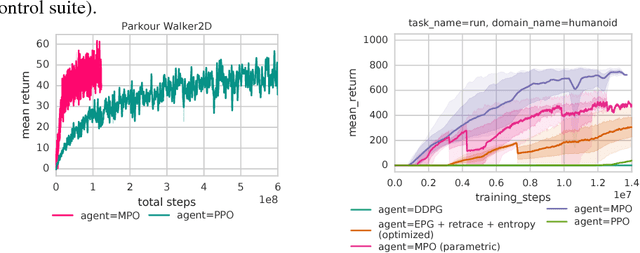
We introduce a new algorithm for reinforcement learning called Maximum aposteriori Policy Optimisation (MPO) based on coordinate ascent on a relative entropy objective. We show that several existing methods can directly be related to our derivation. We develop two off-policy algorithms and demonstrate that they are competitive with the state-of-the-art in deep reinforcement learning. In particular, for continuous control, our method outperforms existing methods with respect to sample efficiency, premature convergence and robustness to hyperparameter settings while achieving similar or better final performance.
Learning Awareness Models
Apr 17, 2018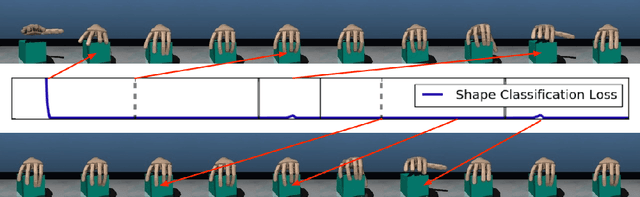
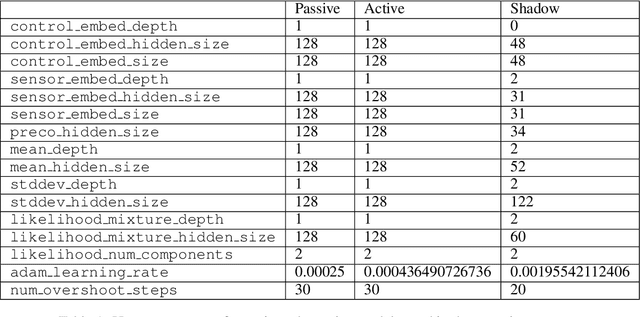

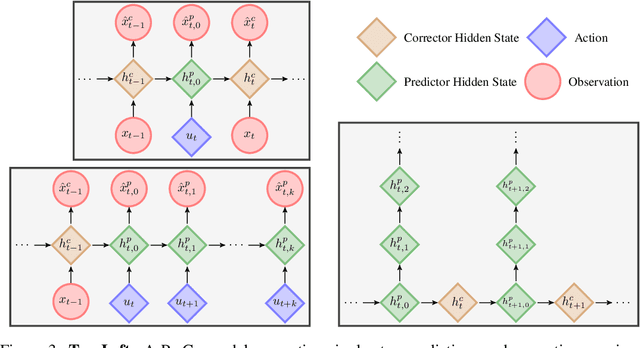
We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.
Safe Exploration in Continuous Action Spaces
Jan 26, 2018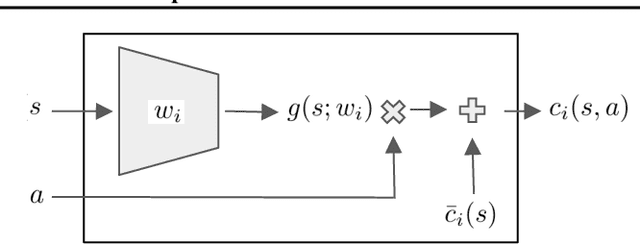
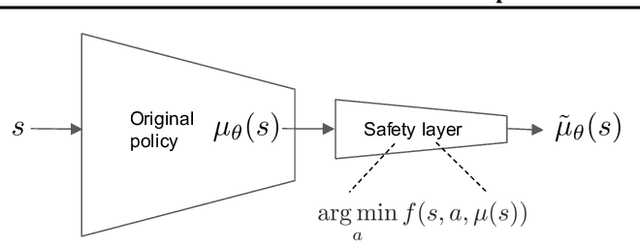


We address the problem of deploying a reinforcement learning (RL) agent on a physical system such as a datacenter cooling unit or robot, where critical constraints must never be violated. We show how to exploit the typically smooth dynamics of these systems and enable RL algorithms to never violate constraints during learning. Our technique is to directly add to the policy a safety layer that analytically solves an action correction formulation per each state. The novelty of obtaining an elegant closed-form solution is attained due to a linearized model, learned on past trajectories consisting of arbitrary actions. This is to mimic the real-world circumstances where data logs were generated with a behavior policy that is implausible to describe mathematically; such cases render the known safety-aware off-policy methods inapplicable. We demonstrate the efficacy of our approach on new representative physics-based environments, and prevail where reward shaping fails by maintaining zero constraint violations.
DeepMind Control Suite
Jan 02, 2018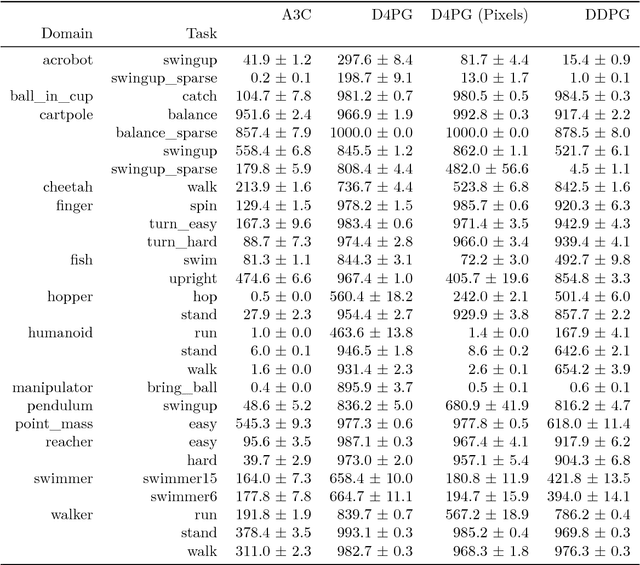
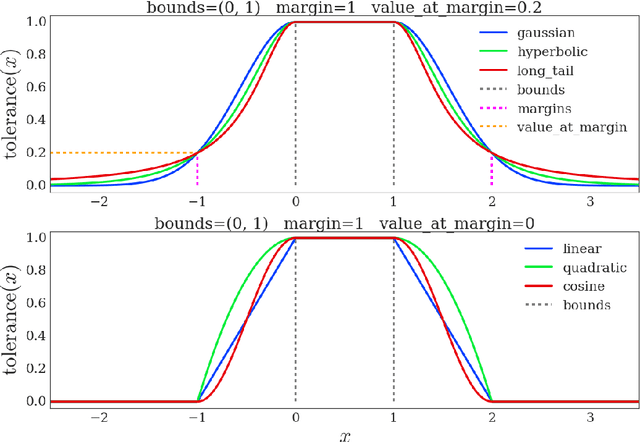
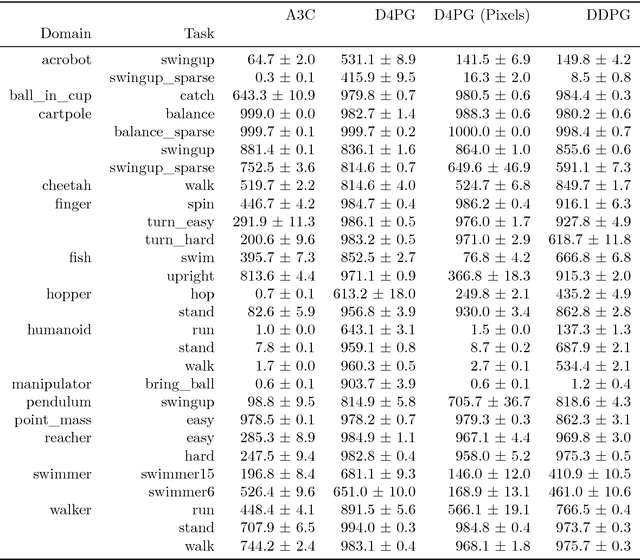
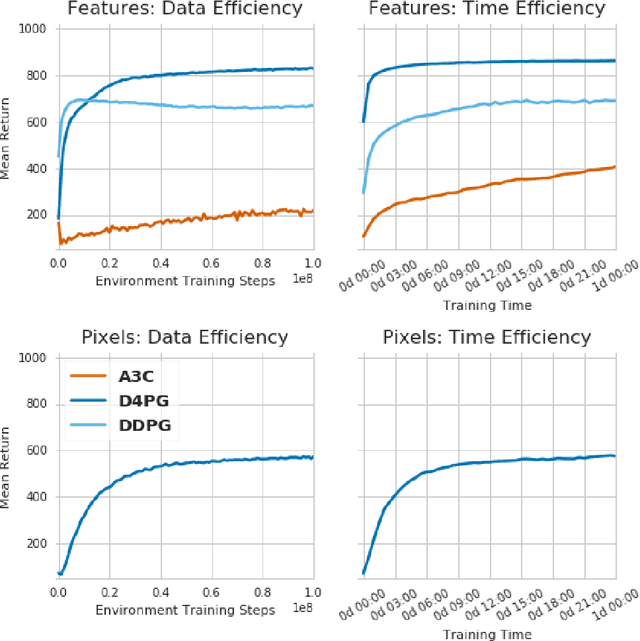
The DeepMind Control Suite is a set of continuous control tasks with a standardised structure and interpretable rewards, intended to serve as performance benchmarks for reinforcement learning agents. The tasks are written in Python and powered by the MuJoCo physics engine, making them easy to use and modify. We include benchmarks for several learning algorithms. The Control Suite is publicly available at https://www.github.com/deepmind/dm_control . A video summary of all tasks is available at http://youtu.be/rAai4QzcYbs .
Emergence of Locomotion Behaviours in Rich Environments
Jul 10, 2017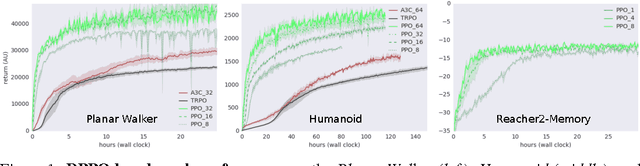


The reinforcement learning paradigm allows, in principle, for complex behaviours to be learned directly from simple reward signals. In practice, however, it is common to carefully hand-design the reward function to encourage a particular solution, or to derive it from demonstration data. In this paper explore how a rich environment can help to promote the learning of complex behavior. Specifically, we train agents in diverse environmental contexts, and find that this encourages the emergence of robust behaviours that perform well across a suite of tasks. We demonstrate this principle for locomotion -- behaviours that are known for their sensitivity to the choice of reward. We train several simulated bodies on a diverse set of challenging terrains and obstacles, using a simple reward function based on forward progress. Using a novel scalable variant of policy gradient reinforcement learning, our agents learn to run, jump, crouch and turn as required by the environment without explicit reward-based guidance. A visual depiction of highlights of the learned behavior can be viewed following https://youtu.be/hx_bgoTF7bs .
Learning human behaviors from motion capture by adversarial imitation
Jul 10, 2017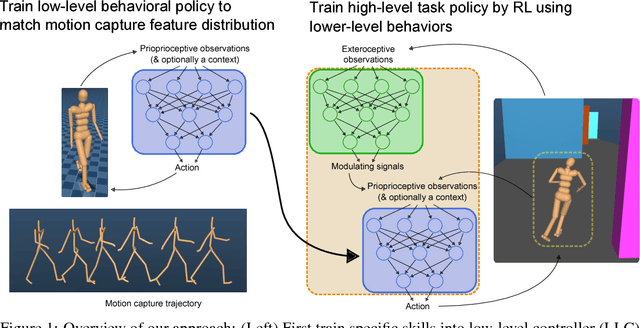
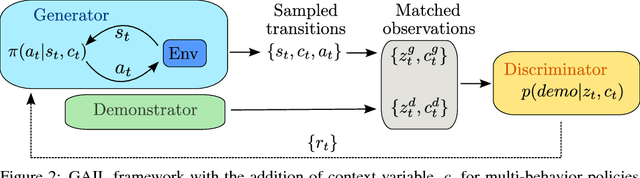
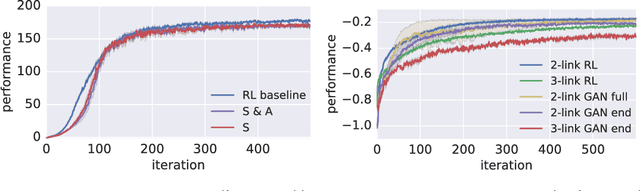
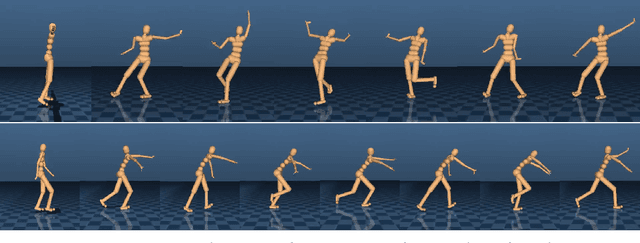
Rapid progress in deep reinforcement learning has made it increasingly feasible to train controllers for high-dimensional humanoid bodies. However, methods that use pure reinforcement learning with simple reward functions tend to produce non-humanlike and overly stereotyped movement behaviors. In this work, we extend generative adversarial imitation learning to enable training of generic neural network policies to produce humanlike movement patterns from limited demonstrations consisting only of partially observed state features, without access to actions, even when the demonstrations come from a body with different and unknown physical parameters. We leverage this approach to build sub-skill policies from motion capture data and show that they can be reused to solve tasks when controlled by a higher level controller.
Data-efficient Deep Reinforcement Learning for Dexterous Manipulation
Apr 10, 2017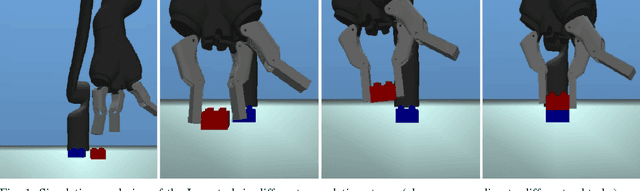
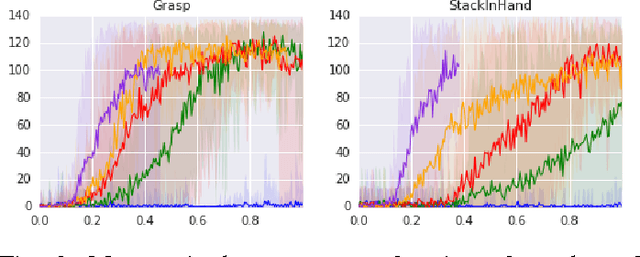
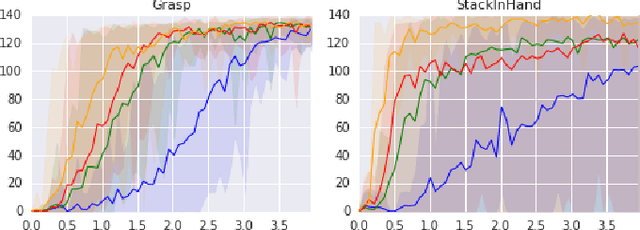
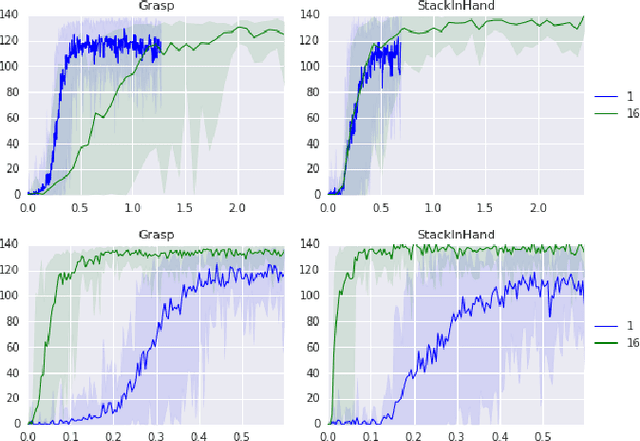
Deep learning and reinforcement learning methods have recently been used to solve a variety of problems in continuous control domains. An obvious application of these techniques is dexterous manipulation tasks in robotics which are difficult to solve using traditional control theory or hand-engineered approaches. One example of such a task is to grasp an object and precisely stack it on another. Solving this difficult and practically relevant problem in the real world is an important long-term goal for the field of robotics. Here we take a step towards this goal by examining the problem in simulation and providing models and techniques aimed at solving it. We introduce two extensions to the Deep Deterministic Policy Gradient algorithm (DDPG), a model-free Q-learning based method, which make it significantly more data-efficient and scalable. Our results show that by making extensive use of off-policy data and replay, it is possible to find control policies that robustly grasp objects and stack them. Further, our results hint that it may soon be feasible to train successful stacking policies by collecting interactions on real robots.
Learning and Transfer of Modulated Locomotor Controllers
Oct 17, 2016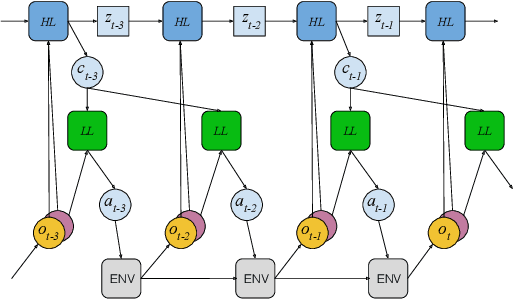


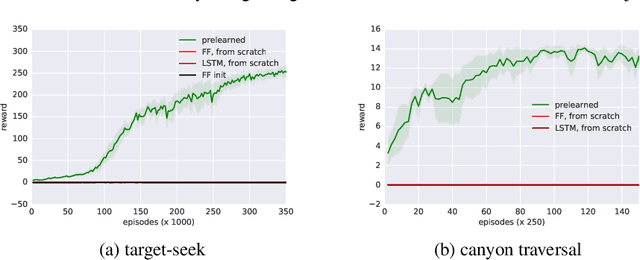
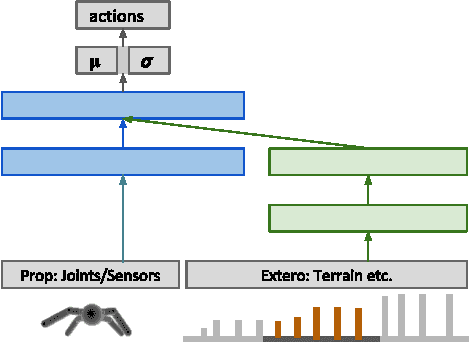
We study a novel architecture and training procedure for locomotion tasks. A high-frequency, low-level "spinal" network with access to proprioceptive sensors learns sensorimotor primitives by training on simple tasks. This pre-trained module is fixed and connected to a low-frequency, high-level "cortical" network, with access to all sensors, which drives behavior by modulating the inputs to the spinal network. Where a monolithic end-to-end architecture fails completely, learning with a pre-trained spinal module succeeds at multiple high-level tasks, and enables the effective exploration required to learn from sparse rewards. We test our proposed architecture on three simulated bodies: a 16-dimensional swimming snake, a 20-dimensional quadruped, and a 54-dimensional humanoid. Our results are illustrated in the accompanying video at https://youtu.be/sboPYvhpraQ
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
Aug 12, 2016
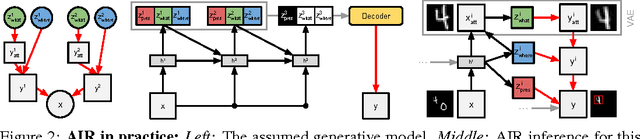

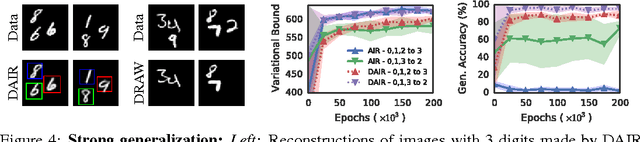
We present a framework for efficient inference in structured image models that explicitly reason about objects. We achieve this by performing probabilistic inference using a recurrent neural network that attends to scene elements and processes them one at a time. Crucially, the model itself learns to choose the appropriate number of inference steps. We use this scheme to learn to perform inference in partially specified 2D models (variable-sized variational auto-encoders) and fully specified 3D models (probabilistic renderers). We show that such models learn to identify multiple objects - counting, locating and classifying the elements of a scene - without any supervision, e.g., decomposing 3D images with various numbers of objects in a single forward pass of a neural network. We further show that the networks produce accurate inferences when compared to supervised counterparts, and that their structure leads to improved generalization.
Continuous control with deep reinforcement learning
Feb 29, 2016
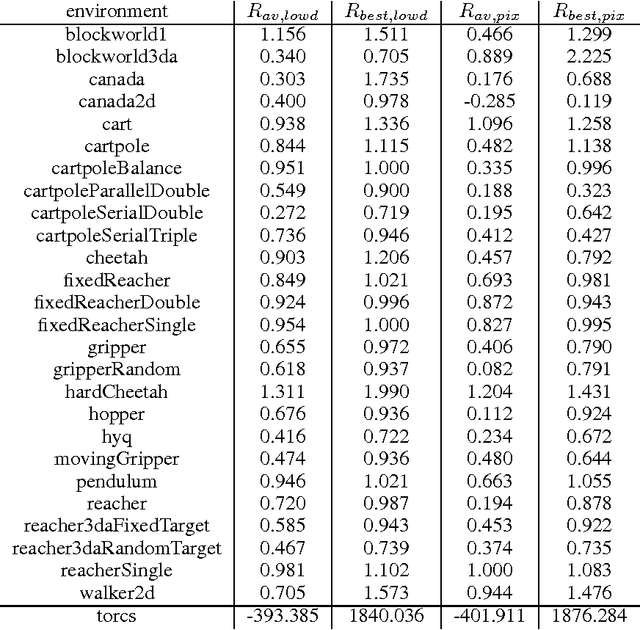
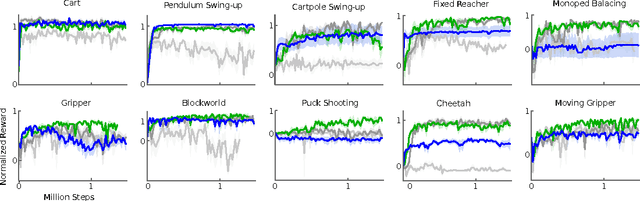
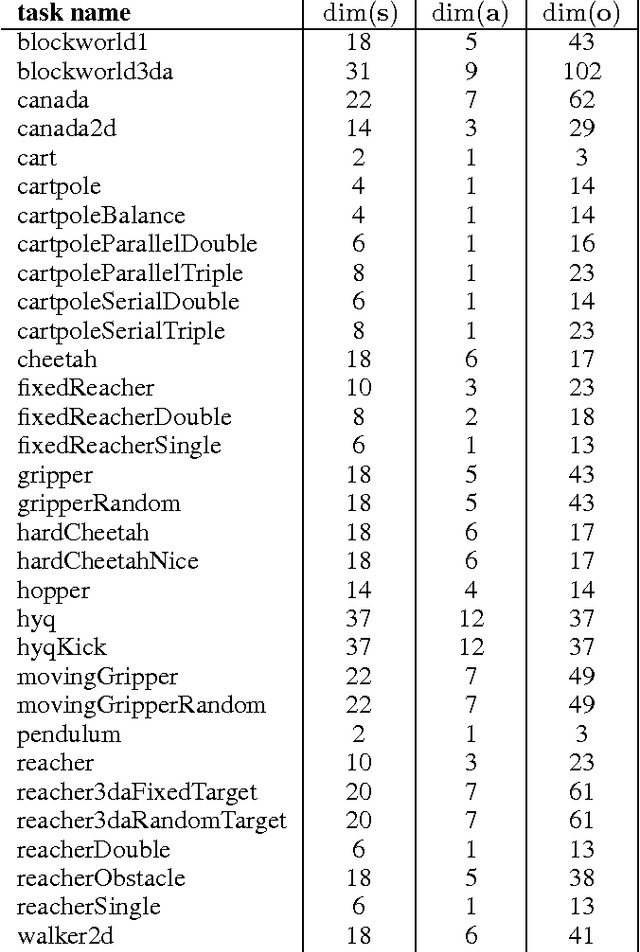
We adapt the ideas underlying the success of Deep Q-Learning to the continuous action domain. We present an actor-critic, model-free algorithm based on the deterministic policy gradient that can operate over continuous action spaces. Using the same learning algorithm, network architecture and hyper-parameters, our algorithm robustly solves more than 20 simulated physics tasks, including classic problems such as cartpole swing-up, dexterous manipulation, legged locomotion and car driving. Our algorithm is able to find policies whose performance is competitive with those found by a planning algorithm with full access to the dynamics of the domain and its derivatives. We further demonstrate that for many of the tasks the algorithm can learn policies end-to-end: directly from raw pixel inputs.