 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
May 19, 2026We present GoLongRL, a fully open-source, capability-oriented post-training recipe for long-context reinforcement learning with verifiable rewards (RLVR). Existing long-context RL methods often treat data construction as a matter of designing increasingly complex retrieval paths, leading to homogeneous task coverage and reward formulations that inadequately reflect practical long-context requirements. Our work offers two contributions. (1) Capability-oriented data construction with full open release. We openly release a dataset of 23K RLVR samples, the complete construction pipeline, and all training code. Guided by a taxonomy of long-context capabilities, the dataset spans 9 task types, each paired with its natural evaluation metric. It comprises curated open-source samples from established corpora and synthetic samples whose QA pairs are generated from real source documents such as books, academic papers, and multi-turn dialogues. Under the same vanilla GRPO setup, our dataset alone outperforms the closed-source QwenLong-L1.5 dataset. Moreover, our Qwen3-30B-A3B model trained on this data delivers long-context performance comparable to DeepSeek-R1-0528 and Qwen3-235B-A22B-Thinking-2507, suggesting that broader coverage and greater reward diversity substantially benefit long-context capability improvement. (2) TMN-Reweight for heterogeneous multitask optimization. To address optimization challenges from heterogeneous rewards, we propose TMN-Reweight, which combines task-level mean normalization for cross-task reward scale alignment with difficulty-adaptive weighting for more reliable advantage estimation. TMN-Reweight further improves average performance over vanilla GRPO, with general capabilities preserved or improved across reported evaluations.
Good Reasoning Makes Good Demonstrations: Implicit Reasoning Quality Supervision via In-Context Reinforcement Learning
Mar 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) improves reasoning in large language models but treats all correct solutions equally, potentially reinforcing flawed traces that get correct answers by chance. We observe that better reasoning are better teachers: high-quality solutions serve as more effective demonstrations than low-quality ones. We term this teaching ability Demonstration Utility, and show that the policy model's own in-context learning ability provides an efficient way to measure it, yielding a quality signal termed Evidence Gain. To employ this signal during training, we introduce In-Context RLVR. By Bayesian analysis, we show that this objective implicitly reweights rewards by Evidence Gain, assigning higher weights to high-quality traces and lower weights to low-quality ones, without requiring costly computation or external evaluators. Experiments on mathematical benchmarks show improvements in both accuracy and reasoning quality over standard RLVR.
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Aug 12, 2025



We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model's exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
LightRetriever: A LLM-based Hybrid Retrieval Architecture with 1000x Faster Query Inference
May 18, 2025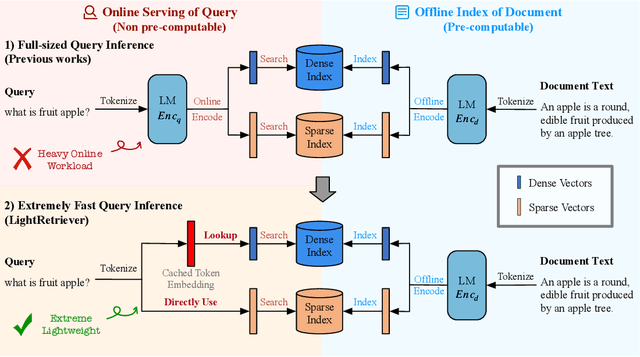
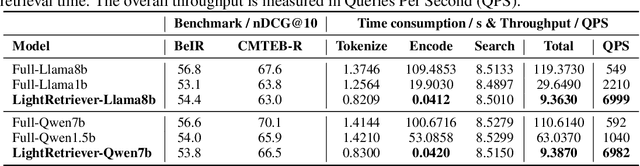

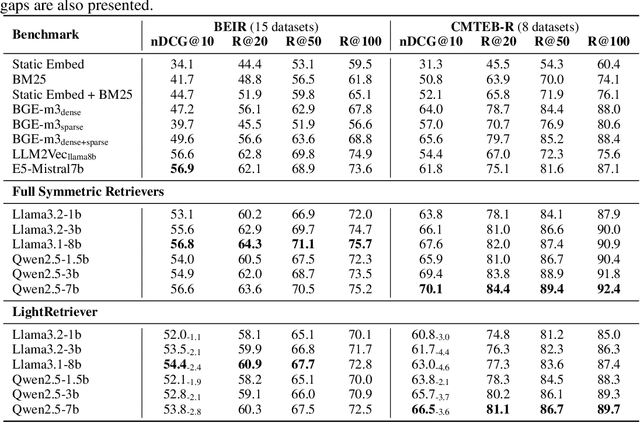
Large Language Models (LLMs)-based hybrid retrieval uses LLMs to encode queries and documents into low-dimensional dense or high-dimensional sparse vectors. It retrieves documents relevant to search queries based on vector similarities. Documents are pre-encoded offline, while queries arrive in real-time, necessitating an efficient online query encoder. Although LLMs significantly enhance retrieval capabilities, serving deeply parameterized LLMs slows down query inference throughput and increases demands for online deployment resources. In this paper, we propose LightRetriever, a novel LLM-based hybrid retriever with extremely lightweight query encoders. Our method retains a full-sized LLM for document encoding, but reduces the workload of query encoding to no more than an embedding lookup. Compared to serving a full-sized LLM on an H800 GPU, our approach achieves over a 1000x speedup for query inference with GPU acceleration, and even a 20x speedup without GPU. Experiments on large-scale retrieval benchmarks demonstrate that our method generalizes well across diverse retrieval tasks, retaining an average of 95% full-sized performance.
Finedeep: Mitigating Sparse Activation in Dense LLMs via Multi-Layer Fine-Grained Experts
Feb 18, 2025



Large language models have demonstrated exceptional performance across a wide range of tasks. However, dense models usually suffer from sparse activation, where many activation values tend towards zero (i.e., being inactivated). We argue that this could restrict the efficient exploration of model representation space. To mitigate this issue, we propose Finedeep, a deep-layered fine-grained expert architecture for dense models. Our framework partitions the feed-forward neural network layers of traditional dense models into small experts, arranges them across multiple sub-layers. A novel routing mechanism is proposed to determine each expert's contribution. We conduct extensive experiments across various model sizes, demonstrating that our approach significantly outperforms traditional dense architectures in terms of perplexity and benchmark performance while maintaining a comparable number of parameters and floating-point operations. Moreover, we find that Finedeep achieves optimal results when balancing depth and width, specifically by adjusting the number of expert sub-layers and the number of experts per sub-layer. Empirical results confirm that Finedeep effectively alleviates sparse activation and efficiently utilizes representation capacity in dense models.
DSMoE: Matrix-Partitioned Experts with Dynamic Routing for Computation-Efficient Dense LLMs
Feb 18, 2025As large language models continue to scale, computational costs and resource consumption have emerged as significant challenges. While existing sparsification methods like pruning reduce computational overhead, they risk losing model knowledge through parameter removal. This paper proposes DSMoE (Dynamic Sparse Mixture-of-Experts), a novel approach that achieves sparsification by partitioning pre-trained FFN layers into computational blocks. We implement adaptive expert routing using sigmoid activation and straight-through estimators, enabling tokens to flexibly access different aspects of model knowledge based on input complexity. Additionally, we introduce a sparsity loss term to balance performance and computational efficiency. Extensive experiments on LLaMA models demonstrate that under equivalent computational constraints, DSMoE achieves superior performance compared to existing pruning and MoE approaches across language modeling and downstream tasks, particularly excelling in generation tasks. Analysis reveals that DSMoE learns distinctive layerwise activation patterns, providing new insights for future MoE architecture design.
CartesianMoE: Boosting Knowledge Sharing among Experts via Cartesian Product Routing in Mixture-of-Experts
Oct 21, 2024Large language models (LLM) have been attracting much attention from the community recently, due to their remarkable performance in all kinds of downstream tasks. According to the well-known scaling law, scaling up a dense LLM enhances its capabilities, but also significantly increases the computational complexity. Mixture-of-Experts (MoE) models address that by allowing the model size to grow without substantially raising training or inference costs. Yet MoE models face challenges regarding knowledge sharing among experts, making their performance somehow sensitive to routing accuracy. To tackle that, previous works introduced shared experts and combined their outputs with those of the top $K$ routed experts in an ``addition'' manner. In this paper, inspired by collective matrix factorization to learn shared knowledge among data, we propose CartesianMoE, which implements more effective knowledge sharing among experts in more like a ``multiplication'' manner. Extensive experimental results indicate that CartesianMoE outperforms previous MoE models for building LLMs, in terms of both perplexity and downstream task performance. And we also find that CartesianMoE achieves better expert routing robustness.
Task-level Distributionally Robust Optimization for Large Language Model-based Dense Retrieval
Aug 20, 2024



Large Language Model-based Dense Retrieval (LLM-DR) optimizes over numerous heterogeneous fine-tuning collections from different domains. However, the discussion about its training data distribution is still minimal. Previous studies rely on empirically assigned dataset choices or sampling ratios, which inevitably leads to sub-optimal retrieval performances. In this paper, we propose a new task-level Distributionally Robust Optimization (tDRO) algorithm for LLM-DR fine-tuning, targeted at improving the universal domain generalization ability by end-to-end reweighting the data distribution of each task. The tDRO parameterizes the domain weights and updates them with scaled domain gradients. The optimized weights are then transferred to the LLM-DR fine-tuning to train more robust retrievers. Experiments show optimal improvements in large-scale retrieval benchmarks and reduce up to 30% dataset usage after applying our optimization algorithm with a series of different-sized LLM-DR models.
MaskMoE: Boosting Token-Level Learning via Routing Mask in Mixture-of-Experts
Jul 13, 2024Scaling model capacity enhances its capabilities but significantly increases computation. Mixture-of-Experts models (MoEs) address this by allowing model capacity to scale without substantially increasing training or inference costs. Despite their promising results, MoE models encounter several challenges. Primarily, the dispersion of training tokens across multiple experts can lead to underfitting, particularly for infrequent tokens. Additionally, while fixed routing mechanisms can mitigate this issue, they compromise on the diversity of representations. In this paper, we propose MaskMoE, a method designed to enhance token-level learning by employing a routing masking technique within the Mixture-of-Experts model. MaskMoE is capable of maintaining representation diversity while achieving more comprehensive training. Experimental results demonstrate that our method outperforms previous dominant Mixture-of-Experts models in both perplexity (PPL) and downstream tasks.
Scaffold-BPE: Enhancing Byte Pair Encoding with Simple and Effective Scaffold Token Removal
Apr 27, 2024



Byte Pair Encoding (BPE) serves as a foundation method for text tokenization in the Natural Language Processing (NLP) field. Despite its wide adoption, the original BPE algorithm harbors an inherent flaw: it inadvertently introduces a frequency imbalance for tokens in the text corpus. Since BPE iteratively merges the most frequent token pair in the text corpus while keeping all tokens that have been merged in the vocabulary, it unavoidably holds tokens that primarily represent subwords of complete words and appear infrequently on their own in the text corpus. We term such tokens as Scaffold Tokens. Due to their infrequent appearance in the text corpus, Scaffold Tokens pose a learning imbalance issue for language models. To address that issue, we propose Scaffold-BPE, which incorporates a dynamic scaffold token removal mechanism by parameter-free, computation-light, and easy-to-implement modifications to the original BPE. This novel approach ensures the exclusion of low-frequency Scaffold Tokens from the token representations for the given texts, thereby mitigating the issue of frequency imbalance and facilitating model training. On extensive experiments across language modeling tasks and machine translation tasks, Scaffold-BPE consistently outperforms the original BPE, well demonstrating its effectiveness and superiority.