 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Conversion Rate Fluctuation during Sales Promotions: A Novel Historical Data Reuse Approach
May 22, 2023



Conversion rate (CVR) prediction is one of the core components in online recommender systems, and various approaches have been proposed to obtain accurate and well-calibrated CVR estimation. However, we observe that a well-trained CVR prediction model often performs sub-optimally during sales promotions. This can be largely ascribed to the problem of the data distribution shift, in which the conventional methods no longer work. To this end, we seek to develop alternative modeling techniques for CVR prediction. Observing similar purchase patterns across different promotions, we propose reusing the historical promotion data to capture the promotional conversion patterns. Herein, we propose a novel \textbf{H}istorical \textbf{D}ata \textbf{R}euse (\textbf{HDR}) approach that first retrieves historically similar promotion data and then fine-tunes the CVR prediction model with the acquired data for better adaptation to the promotion mode. HDR consists of three components: an automated data retrieval module that seeks similar data from historical promotions, a distribution shift correction module that re-weights the retrieved data for better aligning with the target promotion, and a TransBlock module that quickly fine-tunes the original model for better adaptation to the promotion mode. Experiments conducted with real-world data demonstrate the effectiveness of HDR, as it improves both ranking and calibration metrics to a large extent. HDR has also been deployed on the display advertising system in Alibaba, bringing a lift of $9\%$ RPM and $16\%$ CVR during Double 11 Sales in 2022.
Edit As You Wish: Video Description Editing with Multi-grained Commands
May 15, 2023Automatically narrating a video with natural language can assist people in grasping and managing massive videos on the Internet. From the perspective of video uploaders, they may have varied preferences for writing the desired video description to attract more potential followers, e.g. catching customers' attention for product videos. The Controllable Video Captioning task is therefore proposed to generate a description conditioned on the user demand and video content. However, existing works suffer from two shortcomings: 1) the control signal is fixed and can only express single-grained control; 2) the video description can not be further edited to meet dynamic user demands. In this paper, we propose a novel Video Description Editing (VDEdit) task to automatically revise an existing video description guided by flexible user requests. Inspired by human writing-revision habits, we design the user command as a {operation, position, attribute} triplet to cover multi-grained use requirements, which can express coarse-grained control (e.g. expand the description) as well as fine-grained control (e.g. add specified details in specified position) in a unified format. To facilitate the VDEdit task, we first automatically construct a large-scale benchmark dataset namely VATEX-EDIT in the open domain describing diverse human activities. Considering the real-life application scenario, we further manually collect an e-commerce benchmark dataset called EMMAD-EDIT. We propose a unified framework to convert the {operation, position, attribute} triplet into a textual control sequence to handle multi-grained editing commands. For VDEdit evaluation, we adopt comprehensive metrics to measure three aspects of model performance, including caption quality, caption-command consistency, and caption-video alignment.
Primal-Dual Contextual Bayesian Optimization for Control System Online Optimization with Time-Average Constraints
Apr 12, 2023

This paper studies the problem of online performance optimization of constrained closed-loop control systems, where both the objective and the constraints are unknown black-box functions affected by exogenous time-varying contextual disturbances. A primal-dual contextual Bayesian optimization algorithm is proposed that achieves sublinear cumulative regret with respect to the dynamic optimal solution under certain regularity conditions. Furthermore, the algorithm achieves zero time-average constraint violation, ensuring that the average value of the constraint function satisfies the desired constraint. The method is applied to both sampled instances from Gaussian processes and a continuous stirred tank reactor parameter tuning problem; simulation results show that the method simultaneously provides close-to-optimal performance and maintains constraint feasibility on average. This contrasts current state-of-the-art methods, which either suffer from large cumulative regret or severe constraint violations for the case studies presented.
CF-Font: Content Fusion for Few-shot Font Generation
Apr 04, 2023Content and style disentanglement is an effective way to achieve few-shot font generation. It allows to transfer the style of the font image in a source domain to the style defined with a few reference images in a target domain. However, the content feature extracted using a representative font might not be optimal. In light of this, we propose a content fusion module (CFM) to project the content feature into a linear space defined by the content features of basis fonts, which can take the variation of content features caused by different fonts into consideration. Our method also allows to optimize the style representation vector of reference images through a lightweight iterative style-vector refinement (ISR) strategy. Moreover, we treat the 1D projection of a character image as a probability distribution and leverage the distance between two distributions as the reconstruction loss (namely projected character loss, PCL). Compared to L2 or L1 reconstruction loss, the distribution distance pays more attention to the global shape of characters. We have evaluated our method on a dataset of 300 fonts with 6.5k characters each. Experimental results verify that our method outperforms existing state-of-the-art few-shot font generation methods by a large margin. The source code can be found at https://github.com/wangchi95/CF-Font.
Unsupervised Domain Adaption with Pixel-level Discriminator for Image-aware Layout Generation
Mar 25, 2023



Layout is essential for graphic design and poster generation. Recently, applying deep learning models to generate layouts has attracted increasing attention. This paper focuses on using the GAN-based model conditioned on image contents to generate advertising poster graphic layouts, which requires an advertising poster layout dataset with paired product images and graphic layouts. However, the paired images and layouts in the existing dataset are collected by inpainting and annotating posters, respectively. There exists a domain gap between inpainted posters (source domain data) and clean product images (target domain data). Therefore, this paper combines unsupervised domain adaption techniques to design a GAN with a novel pixel-level discriminator (PD), called PDA-GAN, to generate graphic layouts according to image contents. The PD is connected to the shallow level feature map and computes the GAN loss for each input-image pixel. Both quantitative and qualitative evaluations demonstrate that PDA-GAN can achieve state-of-the-art performances and generate high-quality image-aware graphic layouts for advertising posters.
Video Object of Interest Segmentation
Dec 06, 2022



In this work, we present a new computer vision task named video object of interest segmentation (VOIS). Given a video and a target image of interest, our objective is to simultaneously segment and track all objects in the video that are relevant to the target image. This problem combines the traditional video object segmentation task with an additional image indicating the content that users are concerned with. Since no existing dataset is perfectly suitable for this new task, we specifically construct a large-scale dataset called LiveVideos, which contains 2418 pairs of target images and live videos with instance-level annotations. In addition, we propose a transformer-based method for this task. We revisit Swin Transformer and design a dual-path structure to fuse video and image features. Then, a transformer decoder is employed to generate object proposals for segmentation and tracking from the fused features. Extensive experiments on LiveVideos dataset show the superiority of our proposed method.
CONFIG: Constrained Efficient Global Optimization for Closed-Loop Control System Optimization with Unmodeled Constraints
Nov 21, 2022



In this paper, the CONFIG algorithm, a simple and provably efficient constrained global optimization algorithm, is applied to optimize the closed-loop control performance of an unknown system with unmodeled constraints. Existing Gaussian process based closed-loop optimization methods, either can only guarantee local convergence (e.g., SafeOPT), or have no known optimality guarantee (e.g., constrained expected improvement) at all, whereas the recently introduced CONFIG algorithm has been proven to enjoy a theoretical global optimality guarantee. In this study, we demonstrate the effectiveness of CONFIG algorithm in the applications. The algorithm is first applied to an artificial numerical benchmark problem to corroborate its effectiveness. It is then applied to a classical constrained steady-state optimization problem of a continuous stirred-tank reactor. Simulation results show that our CONFIG algorithm can achieve performance competitive with the popular CEI (Constrained Expected Improvement) algorithm, which has no known optimality guarantee. As such, the CONFIG algorithm offers a new tool, with both a provable global optimality guarantee and competitive empirical performance, to optimize the closed-loop control performance for a system with soft unmodeled constraints. Last, but not least, the open-source code is available as a python package to facilitate future applications.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022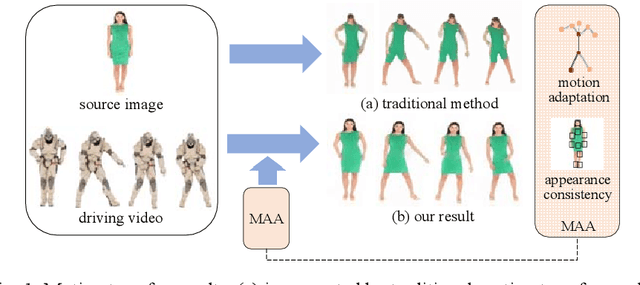
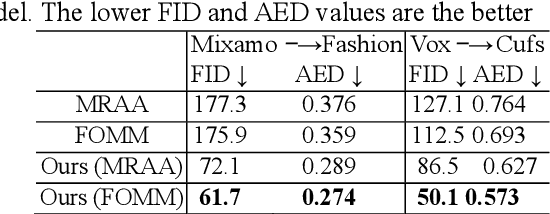
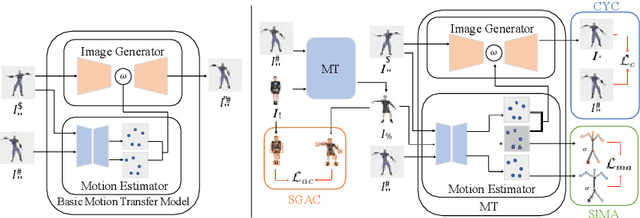
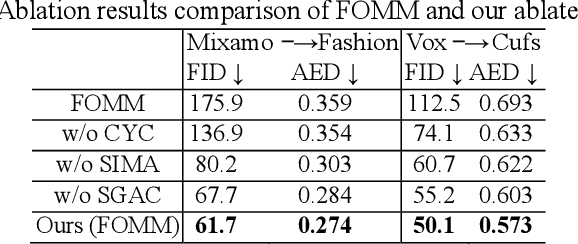
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Federated Reinforcement Learning for Real-Time Electric Vehicle Charging and Discharging Control
Oct 04, 2022
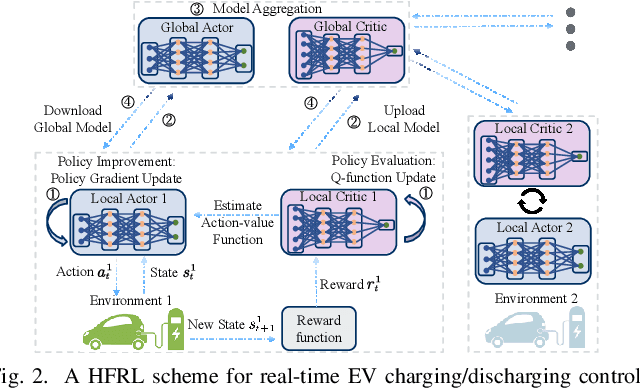
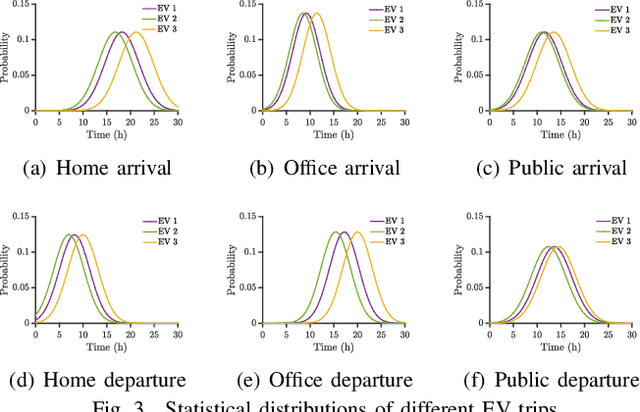
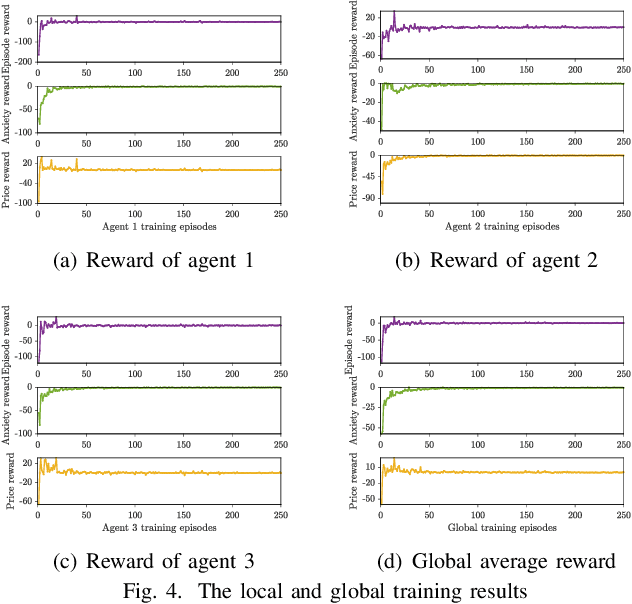
With the recent advances in mobile energy storage technologies, electric vehicles (EVs) have become a crucial part of smart grids. When EVs participate in the demand response program, the charging cost can be significantly reduced by taking full advantage of the real-time pricing signals. However, many stochastic factors exist in the dynamic environment, bringing significant challenges to design an optimal charging/discharging control strategy. This paper develops an optimal EV charging/discharging control strategy for different EV users under dynamic environments to maximize EV users' benefits. We first formulate this problem as a Markov decision process (MDP). Then we consider EV users with different behaviors as agents in different environments. Furthermore, a horizontal federated reinforcement learning (HFRL)-based method is proposed to fit various users' behaviors and dynamic environments. This approach can learn an optimal charging/discharging control strategy without sharing users' profiles. Simulation results illustrate that the proposed real-time EV charging/discharging control strategy can perform well among various stochastic factors.
Motion Transformer for Unsupervised Image Animation
Sep 28, 2022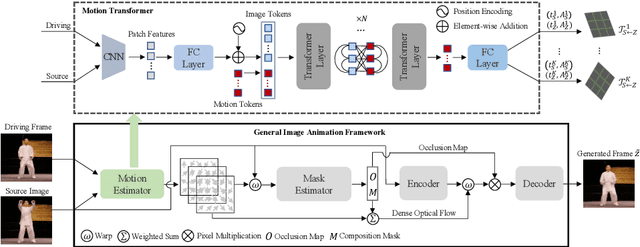
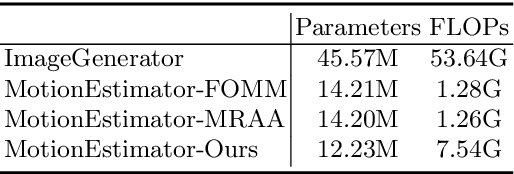


Image animation aims to animate a source image by using motion learned from a driving video. Current state-of-the-art methods typically use convolutional neural networks (CNNs) to predict motion information, such as motion keypoints and corresponding local transformations. However, these CNN based methods do not explicitly model the interactions between motions; as a result, the important underlying motion relationship may be neglected, which can potentially lead to noticeable artifacts being produced in the generated animation video. To this end, we propose a new method, the motion transformer, which is the first attempt to build a motion estimator based on a vision transformer. More specifically, we introduce two types of tokens in our proposed method: i) image tokens formed from patch features and corresponding position encoding; and ii) motion tokens encoded with motion information. Both types of tokens are sent into vision transformers to promote underlying interactions between them through multi-head self attention blocks. By adopting this process, the motion information can be better learned to boost the model performance. The final embedded motion tokens are then used to predict the corresponding motion keypoints and local transformations. Extensive experiments on benchmark datasets show that our proposed method achieves promising results to the state-of-the-art baselines. Our source code will be public available.