 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAP-SAM: Towards Real-Time All-Purpose Segment Anything
Jan 18, 2024Advanced by transformer architecture, vision foundation models (VFMs) achieve remarkable progress in performance and generalization ability. Segment Anything Model (SAM) is one remarkable model that can achieve generalized segmentation. However, most VFMs cannot run in realtime, which makes it difficult to transfer them into several products. On the other hand, current real-time segmentation mainly has one purpose, such as semantic segmentation on the driving scene. We argue that diverse outputs are needed for real applications. Thus, this work explores a new real-time segmentation setting, named all-purpose segmentation in real-time, to transfer VFMs in real-time deployment. It contains three different tasks, including interactive segmentation, panoptic segmentation, and video segmentation. We aim to use one model to achieve the above tasks in real-time. We first benchmark several strong baselines. Then, we present Real-Time All Purpose SAM (RAP-SAM). It contains an efficient encoder and an efficient decoupled decoder to perform prompt-driven decoding. Moreover, we further explore different training strategies and tuning methods to boost co-training performance further. Our code and model are available at https://github.com/xushilin1/RAP-SAM/.
Towards Language-Driven Video Inpainting via Multimodal Large Language Models
Jan 18, 2024



We introduce a new task -- language-driven video inpainting, which uses natural language instructions to guide the inpainting process. This approach overcomes the limitations of traditional video inpainting methods that depend on manually labeled binary masks, a process often tedious and labor-intensive. We present the Remove Objects from Videos by Instructions (ROVI) dataset, containing 5,650 videos and 9,091 inpainting results, to support training and evaluation for this task. We also propose a novel diffusion-based language-driven video inpainting framework, the first end-to-end baseline for this task, integrating Multimodal Large Language Models to understand and execute complex language-based inpainting requests effectively. Our comprehensive results showcase the dataset's versatility and the model's effectiveness in various language-instructed inpainting scenarios. We will make datasets, code, and models publicly available.
DST-Det: Simple Dynamic Self-Training for Open-Vocabulary Object Detection
Oct 02, 2023



Open-vocabulary object detection (OVOD) aims to detect the objects beyond the set of categories observed during training. This work presents a simple yet effective strategy that leverages the zero-shot classification ability of pre-trained vision-language models (VLM), such as CLIP, to classify proposals for all possible novel classes directly. Unlike previous works that ignore novel classes during training and rely solely on the region proposal network (RPN) for novel object detection, our method selectively filters proposals based on specific design criteria. The resulting sets of identified proposals serve as pseudo-labels for novel classes during the training phase. It enables our self-training strategy to improve the recall and accuracy of novel classes in a self-training manner without requiring additional annotations or datasets. We further propose a simple offline pseudo-label generation strategy to refine the object detector. Empirical evaluations on three datasets, including LVIS, V3Det, and COCO, demonstrate significant improvements over the baseline performance without incurring additional parameters or computational costs during inference. In particular, compared with previous F-VLM, our method achieves a 1.7-2.0% improvement on LVIS dataset and 2.3-3.8% improvement on the recent challenging V3Det dataset. Our method also boosts the strong baseline by 6% mAP on COCO. The code and models will be publicly available at https://github.com/xushilin1/dst-det.
Mitigating Semantic Confusion from Hostile Neighborhood for Graph Active Learning
Aug 17, 2023



Graph Active Learning (GAL), which aims to find the most informative nodes in graphs for annotation to maximize the Graph Neural Networks (GNNs) performance, has attracted many research efforts but remains non-trivial challenges. One major challenge is that existing GAL strategies may introduce semantic confusion to the selected training set, particularly when graphs are noisy. Specifically, most existing methods assume all aggregating features to be helpful, ignoring the semantically negative effect between inter-class edges under the message-passing mechanism. In this work, we present Semantic-aware Active learning framework for Graphs (SAG) to mitigate the semantic confusion problem. Pairwise similarities and dissimilarities of nodes with semantic features are introduced to jointly evaluate the node influence. A new prototype-based criterion and query policy are also designed to maintain diversity and class balance of the selected nodes, respectively. Extensive experiments on the public benchmark graphs and a real-world financial dataset demonstrate that SAG significantly improves node classification performances and consistently outperforms previous methods. Moreover, comprehensive analysis and ablation study also verify the effectiveness of the proposed framework.
Towards Open Vocabulary Learning: A Survey
Jul 06, 2023



In the field of visual scene understanding, deep neural networks have made impressive advancements in various core tasks like segmentation, tracking, and detection. However, most approaches operate on the close-set assumption, meaning that the model can only identify pre-defined categories that are present in the training set. Recently, open vocabulary settings were proposed due to the rapid progress of vision language pre-training. These new approaches seek to locate and recognize categories beyond the annotated label space. The open vocabulary approach is more general, practical, and effective compared to weakly supervised and zero-shot settings. This paper provides a thorough review of open vocabulary learning, summarizing and analyzing recent developments in the field. In particular, we begin by comparing it to related concepts such as zero-shot learning, open-set recognition, and out-of-distribution detection. Then, we review several closely related tasks in the case of segmentation and detection, including long-tail problems, few-shot, and zero-shot settings. For the method survey, we first present the basic knowledge of detection and segmentation in close-set as the preliminary knowledge. Next, we examine various scenarios in which open vocabulary learning is used, identifying common design elements and core ideas. Then, we compare the recent detection and segmentation approaches in commonly used datasets and benchmarks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To our knowledge, this is the first comprehensive literature review of open vocabulary learning. We keep tracing related works at https://github.com/jianzongwu/Awesome-Open-Vocabulary.
PanopticPartFormer++: A Unified and Decoupled View for Panoptic Part Segmentation
Jan 03, 2023



Panoptic Part Segmentation (PPS) unifies panoptic segmentation and part segmentation into one task. Previous works utilize separated approaches to handle thing, stuff, and part predictions without shared computation and task association. We aim to unify these tasks at the architectural level, designing the first end-to-end unified framework named Panoptic-PartFormer. Moreover, we find the previous metric PartPQ biases to PQ. To handle both issues, we make the following contributions: Firstly, we design a meta-architecture that decouples part feature and things/stuff feature, respectively. We model things, stuff, and parts as object queries and directly learn to optimize all three forms of prediction as a unified mask prediction and classification problem. We term our model as Panoptic-PartFormer. Secondly, we propose a new metric Part-Whole Quality (PWQ) to better measure such task from both pixel-region and part-whole perspectives. It can also decouple the error for part segmentation and panoptic segmentation. Thirdly, inspired by Mask2Former, based on our meta-architecture, we propose Panoptic-PartFormer++ and design a new part-whole cross attention scheme to further boost part segmentation qualities. We design a new part-whole interaction method using masked cross attention. Finally, the extensive ablation studies and analysis demonstrate the effectiveness of both Panoptic-PartFormer and Panoptic-PartFormer++. Compared with previous Panoptic-PartFormer, our Panoptic-PartFormer++ achieves 2% PartPQ and 3% PWQ improvements on the Cityscapes PPS dataset and 5% PartPQ on the Pascal Context PPS dataset. On both datasets, Panoptic-PartFormer++ achieves new state-of-the-art results with a significant cost drop of 70% on GFlops and 50% on parameters. Our models can serve as a strong baseline and aid future research in PPS. Code will be available.
Betrayed by Captions: Joint Caption Grounding and Generation for Open Vocabulary Instance Segmentation
Jan 02, 2023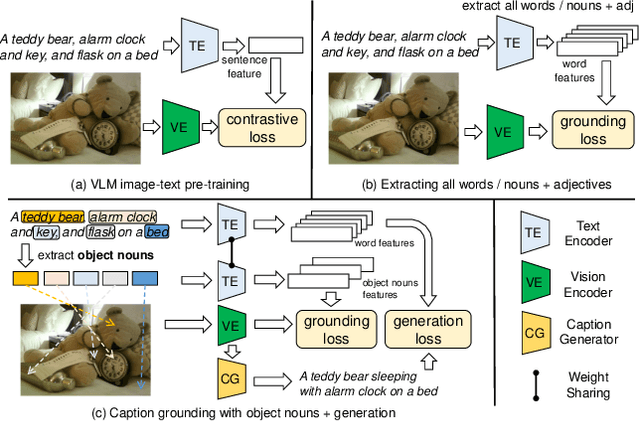
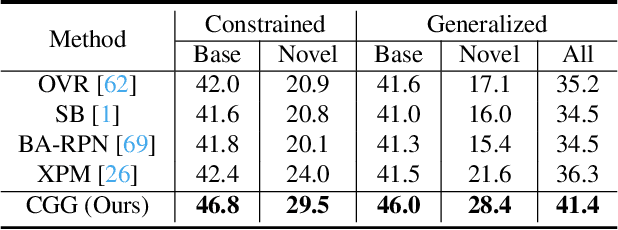

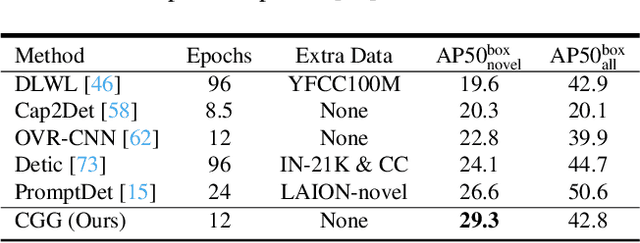
In this work, we focus on instance-level open vocabulary segmentation, intending to expand a segmenter for instance-wise novel categories without mask annotations. We investigate a simple yet effective framework with the help of image captions, focusing on exploiting thousands of object nouns in captions to discover instances of novel classes. Rather than adopting pretrained caption models or using massive caption datasets with complex pipelines, we propose an end-to-end solution from two aspects: caption grounding and caption generation. In particular, we devise a joint Caption Grounding and Generation (CGG) framework based on a Mask Transformer baseline. The framework has a novel grounding loss that performs explicit and implicit multi-modal feature alignments. We further design a lightweight caption generation head to allow for additional caption supervision. We find that grounding and generation complement each other, significantly enhancing the segmentation performance for novel categories. We conduct extensive experiments on the COCO dataset with two settings: Open Vocabulary Instance Segmentation (OVIS) and Open Set Panoptic Segmentation (OSPS). The results demonstrate the superiority of our CGG framework over previous OVIS methods, achieving a large improvement of 6.8% mAP on novel classes without extra caption data. Our method also achieves over 15% PQ improvements for novel classes on the OSPS benchmark under various settings.
Label-Efficient Interactive Time-Series Anomaly Detection
Dec 30, 2022Time-series anomaly detection is an important task and has been widely applied in the industry. Since manual data annotation is expensive and inefficient, most applications adopt unsupervised anomaly detection methods, but the results are usually sub-optimal and unsatisfactory to end customers. Weak supervision is a promising paradigm for obtaining considerable labels in a low-cost way, which enables the customers to label data by writing heuristic rules rather than annotating each instance individually. However, in the time-series domain, it is hard for people to write reasonable labeling functions as the time-series data is numerically continuous and difficult to be understood. In this paper, we propose a Label-Efficient Interactive Time-Series Anomaly Detection (LEIAD) system, which enables a user to improve the results of unsupervised anomaly detection by performing only a small amount of interactions with the system. To achieve this goal, the system integrates weak supervision and active learning collaboratively while generating labeling functions automatically using only a few labeled data. All of these techniques are complementary and can promote each other in a reinforced manner. We conduct experiments on three time-series anomaly detection datasets, demonstrating that the proposed system is superior to existing solutions in both weak supervision and active learning areas. Also, the system has been tested in a real scenario in industry to show its practicality.
Convolution-enhanced Evolving Attention Networks
Dec 16, 2022



Attention-based neural networks, such as Transformers, have become ubiquitous in numerous applications, including computer vision, natural language processing, and time-series analysis. In all kinds of attention networks, the attention maps are crucial as they encode semantic dependencies between input tokens. However, most existing attention networks perform modeling or reasoning based on representations, wherein the attention maps of different layers are learned separately without explicit interactions. In this paper, we propose a novel and generic evolving attention mechanism, which directly models the evolution of inter-token relationships through a chain of residual convolutional modules. The major motivations are twofold. On the one hand, the attention maps in different layers share transferable knowledge, thus adding a residual connection can facilitate the information flow of inter-token relationships across layers. On the other hand, there is naturally an evolutionary trend among attention maps at different abstraction levels, so it is beneficial to exploit a dedicated convolution-based module to capture this process. Equipped with the proposed mechanism, the convolution-enhanced evolving attention networks achieve superior performance in various applications, including time-series representation, natural language understanding, machine translation, and image classification. Especially on time-series representation tasks, Evolving Attention-enhanced Dilated Convolutional (EA-DC-) Transformer outperforms state-of-the-art models significantly, achieving an average of 17% improvement compared to the best SOTA. To the best of our knowledge, this is the first work that explicitly models the layer-wise evolution of attention maps. Our implementation is available at https://github.com/pkuyym/EvolvingAttention
Towards Robust Referring Image Segmentation
Sep 20, 2022
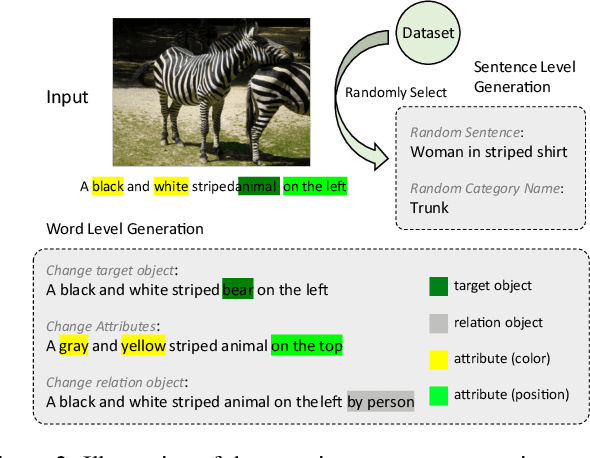
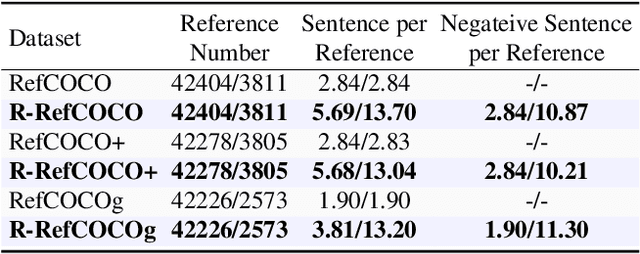
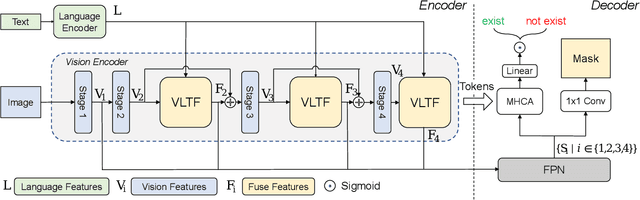
Referring Image Segmentation (RIS) aims to connect image and language via outputting the corresponding object masks given a text description, which is a fundamental vision-language task. Despite lots of works that have achieved considerable progress for RIS, in this work, we explore an essential question, "what if the description is wrong or misleading of the text description?". We term such a sentence as a negative sentence. However, we find that existing works cannot handle such settings. To this end, we propose a novel formulation of RIS, named Robust Referring Image Segmentation (R-RIS). It considers the negative sentence inputs besides the regularly given text inputs. We present three different datasets via augmenting the input negative sentences and a new metric to unify both input types. Furthermore, we design a new transformer-based model named RefSegformer, where we introduce a token-based vision and language fusion module. Such module can be easily extended to our R-RIS setting by adding extra blank tokens. Our proposed RefSegformer achieves the new state-of-the-art results on three regular RIS datasets and three R-RIS datasets, which serves as a new solid baseline for further research. The project page is at \url{https://lxtgh.github.io/project/robust_ref_seg/}.