 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022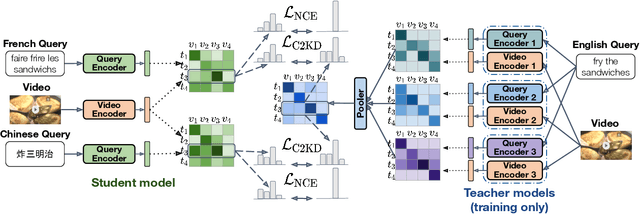
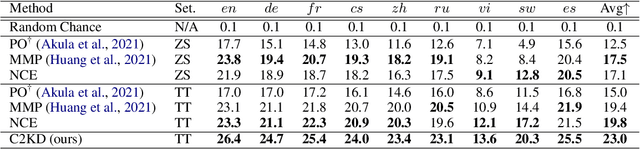

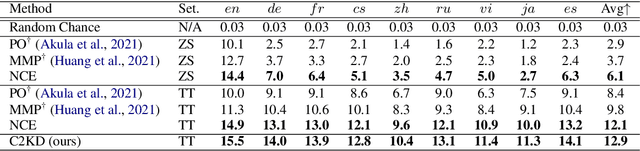
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Apr 21, 2022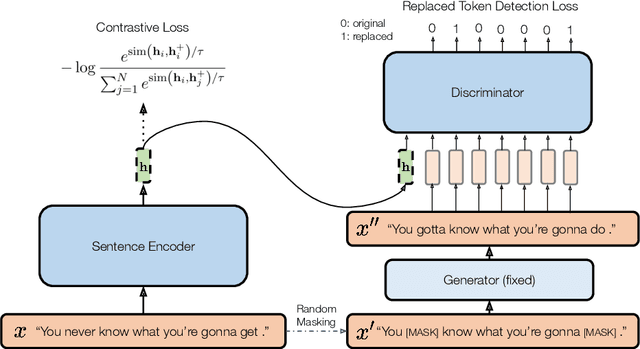
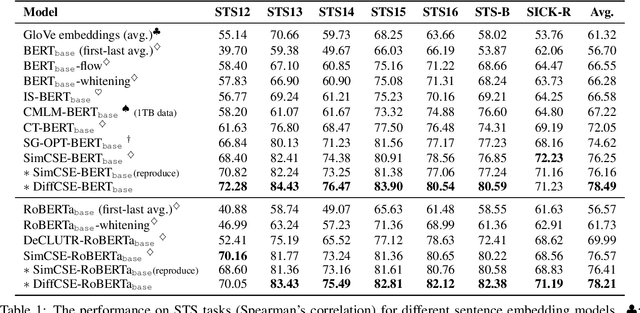
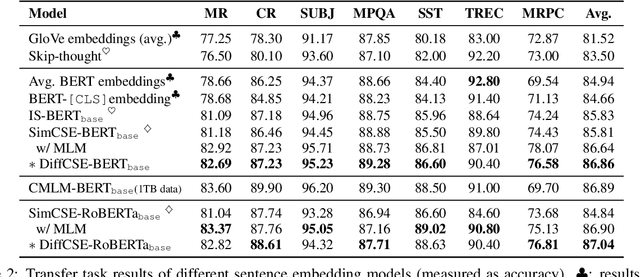
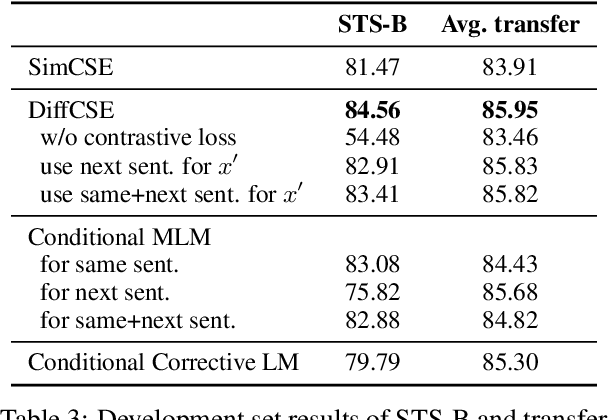
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022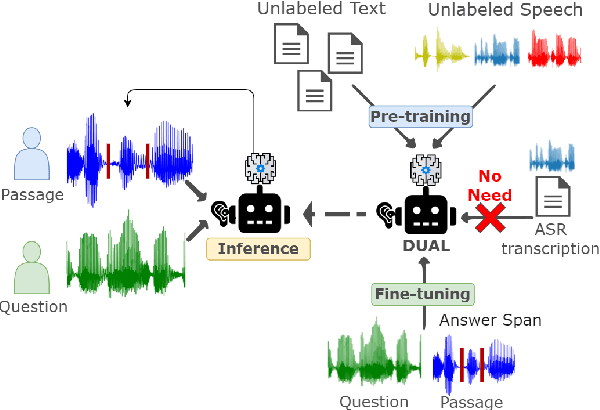
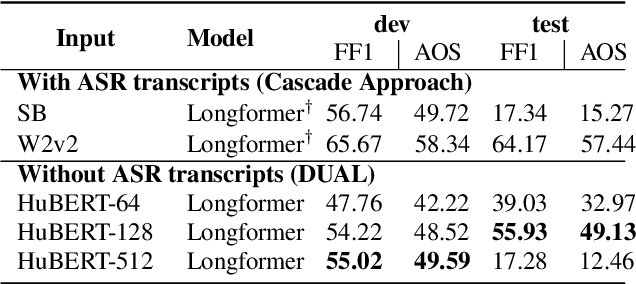
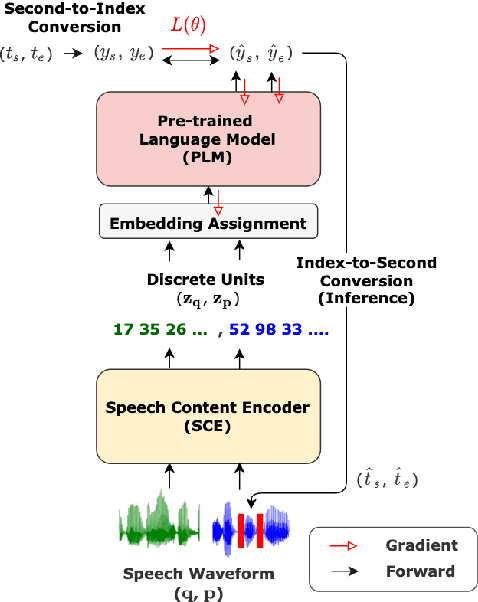
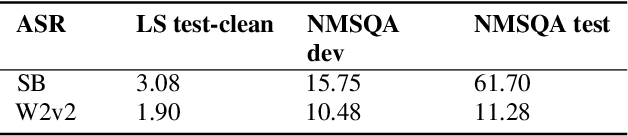
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
Oct 04, 2021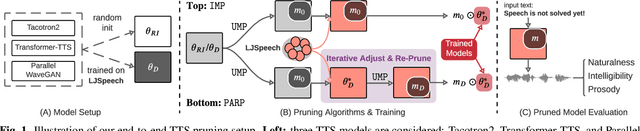
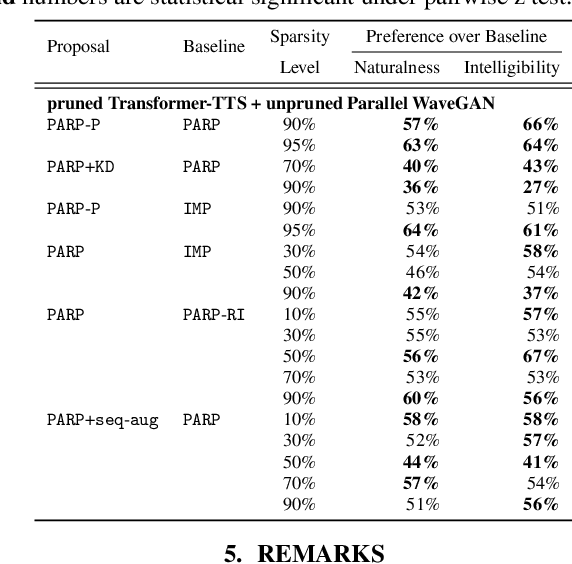
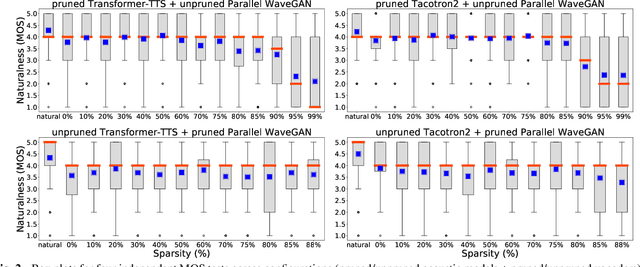
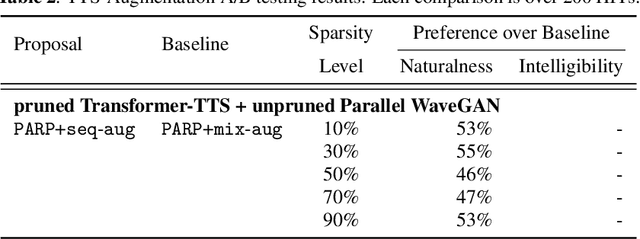
Are end-to-end text-to-speech (TTS) models over-parametrized? To what extent can these models be pruned, and what happens to their synthesis capabilities? This work serves as a starting point to explore pruning both spectrogram prediction networks and vocoders. We thoroughly investigate the tradeoffs between sparstiy and its subsequent effects on synthetic speech. Additionally, we explored several aspects of TTS pruning: amount of finetuning data versus sparsity, TTS-Augmentation to utilize unspoken text, and combining knowledge distillation and pruning. Our findings suggest that not only are end-to-end TTS models highly prunable, but also, perhaps surprisingly, pruned TTS models can produce synthetic speech with equal or higher naturalness and intelligibility, with similar prosody. All of our experiments are conducted on publicly available models, and findings in this work are backed by large-scale subjective tests and objective measures. Code and 200 pruned models are made available to facilitate future research on efficiency in TTS.
Mitigating Biases in Toxic Language Detection through Invariant Rationalization
Jun 14, 2021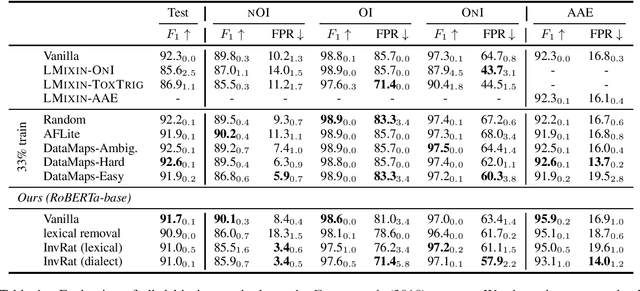


Automatic detection of toxic language plays an essential role in protecting social media users, especially minority groups, from verbal abuse. However, biases toward some attributes, including gender, race, and dialect, exist in most training datasets for toxicity detection. The biases make the learned models unfair and can even exacerbate the marginalization of people. Considering that current debiasing methods for general natural language understanding tasks cannot effectively mitigate the biases in the toxicity detectors, we propose to use invariant rationalization (InvRat), a game-theoretic framework consisting of a rationale generator and a predictor, to rule out the spurious correlation of certain syntactic patterns (e.g., identity mentions, dialect) to toxicity labels. We empirically show that our method yields lower false positive rate in both lexical and dialectal attributes than previous debiasing methods.
PARP: Prune, Adjust and Re-Prune for Self-Supervised Speech Recognition
Jun 10, 2021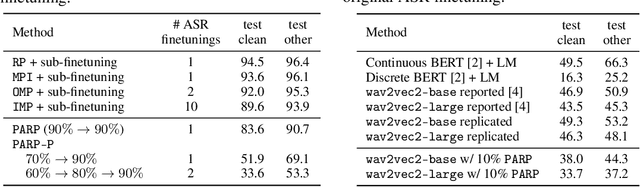
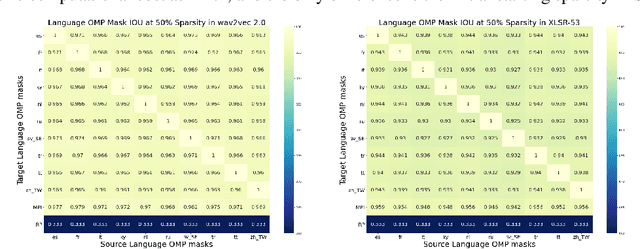
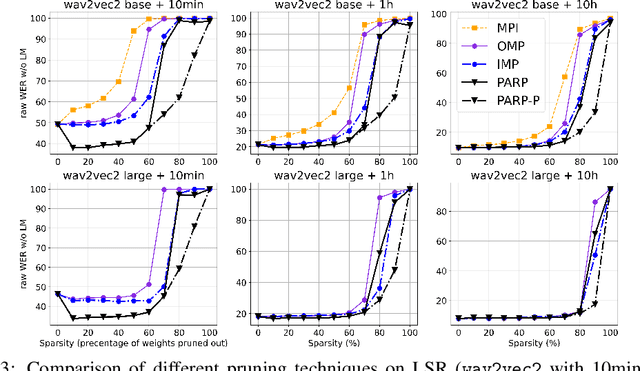
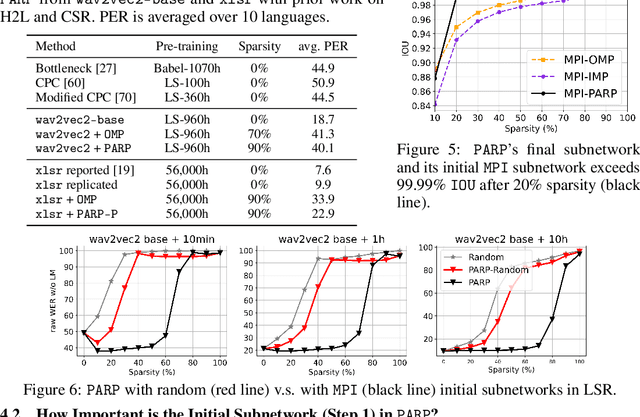
Recent work on speech self-supervised learning (speech SSL) demonstrated the benefits of scale in learning rich and transferable representations for Automatic Speech Recognition (ASR) with limited parallel data. It is then natural to investigate the existence of sparse and transferrable subnetworks in pre-trained speech SSL models that can achieve even better low-resource ASR performance. However, directly applying widely adopted pruning methods such as the Lottery Ticket Hypothesis (LTH) is suboptimal in the computational cost needed. Moreover, contrary to what LTH predicts, the discovered subnetworks yield minimal performance gain compared to the original dense network. In this work, we propose Prune-Adjust- Re-Prune (PARP), which discovers and finetunes subnetworks for much better ASR performance, while only requiring a single downstream finetuning run. PARP is inspired by our surprising observation that subnetworks pruned for pre-training tasks only needed to be slightly adjusted to achieve a sizeable performance boost in downstream ASR tasks. Extensive experiments on low-resource English and multi-lingual ASR show (1) sparse subnetworks exist in pre-trained speech SSL, and (2) the computational advantage and performance gain of PARP over baseline pruning methods. On the 10min Librispeech split without LM decoding, PARP discovers subnetworks from wav2vec 2.0 with an absolute 10.9%/12.6% WER decrease compared to the full model. We demonstrate PARP mitigates performance degradation in cross-lingual mask transfer, and investigate the possibility of discovering a single subnetwork for 10 spoken languages in one run.
Meta-learning for downstream aware and agnostic pretraining
Jun 06, 2021Neural network pretraining is gaining attention due to its outstanding performance in natural language processing applications. However, pretraining usually leverages predefined task sequences to learn general linguistic clues. The lack of mechanisms in choosing proper tasks during pretraining makes the learning and knowledge encoding inefficient. We thus propose using meta-learning to select tasks that provide the most informative learning signals in each episode of pretraining. With the proposed method, we aim to achieve better efficiency in computation and memory usage for the pretraining process and resulting networks while maintaining the performance. In this preliminary work, we discuss the algorithm of the method and its two variants, downstream-aware and downstream-agnostic pretraining. Our experiment plan is also summarized, while empirical results will be shared in our future works.
* Extended abstract
Investigating the Reordering Capability in CTC-based Non-Autoregressive End-to-End Speech Translation
May 11, 2021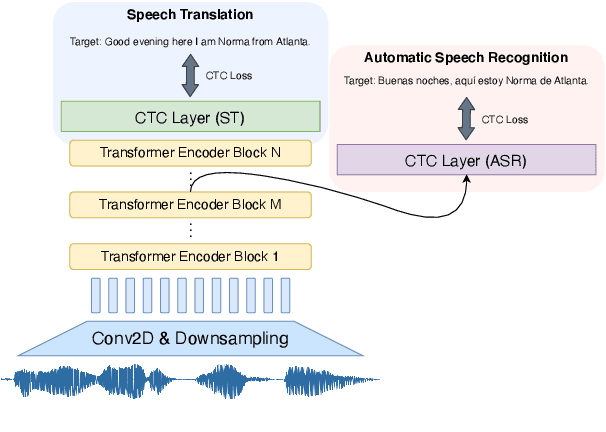
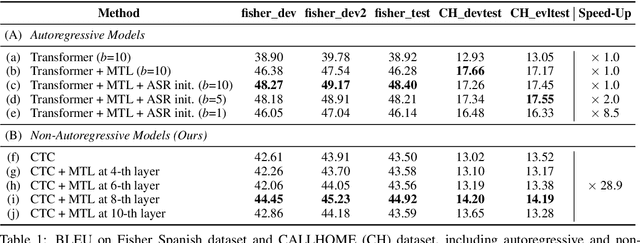
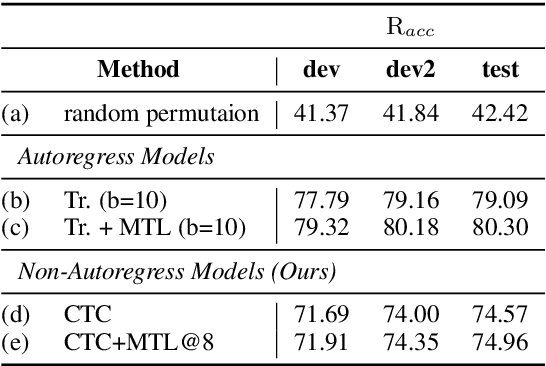
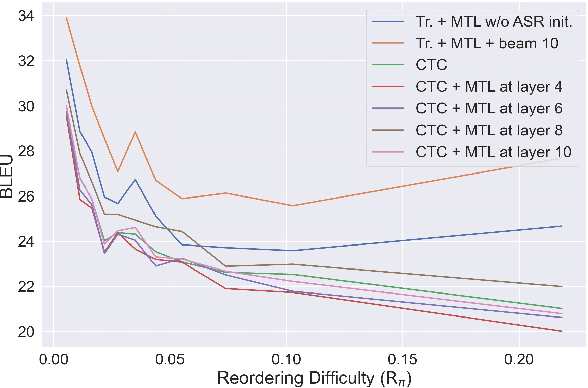
We study the possibilities of building a non-autoregressive speech-to-text translation model using connectionist temporal classification (CTC), and use CTC-based automatic speech recognition as an auxiliary task to improve the performance. CTC's success on translation is counter-intuitive due to its monotonicity assumption, so we analyze its reordering capability. Kendall's tau distance is introduced as the quantitative metric, and gradient-based visualization provides an intuitive way to take a closer look into the model. Our analysis shows that transformer encoders have the ability to change the word order and points out the future research direction that worth being explored more on non-autoregressive speech translation.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021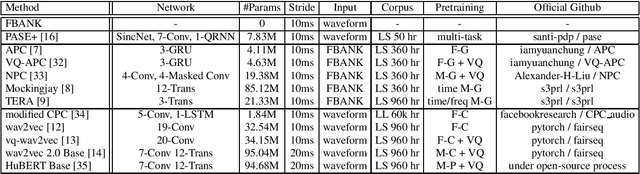
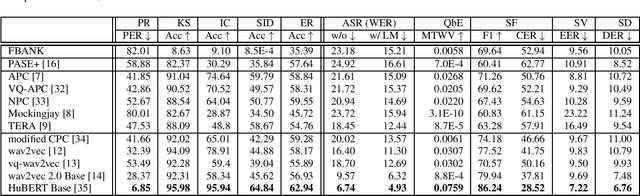
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.
Semi-Supervised Spoken Language Understanding via Self-Supervised Speech and Language Model Pretraining
Oct 26, 2020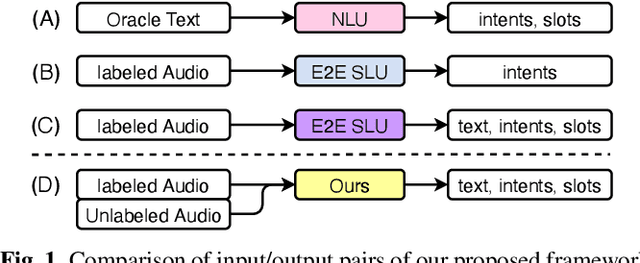
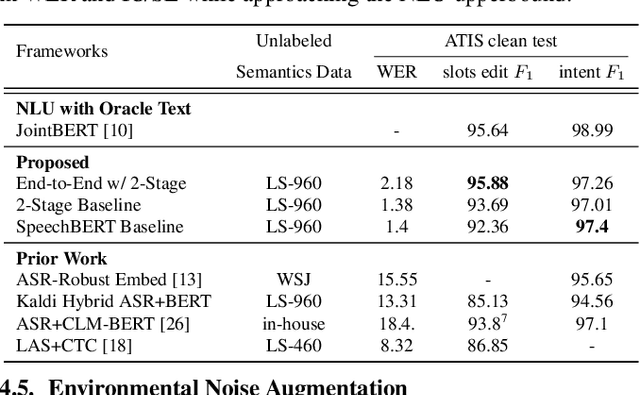
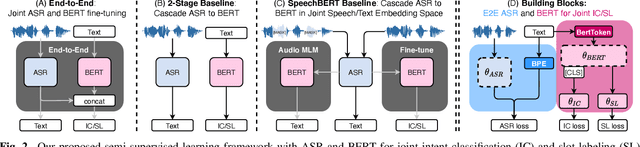
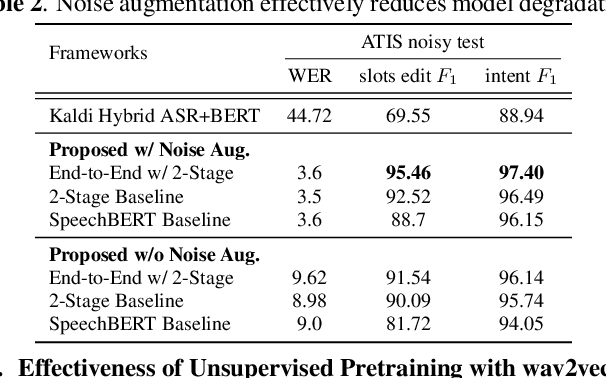
Much recent work on Spoken Language Understanding (SLU) is limited in at least one of three ways: models were trained on oracle text input and neglected ASR errors, models were trained to predict only intents without the slot values, or models were trained on a large amount of in-house data. In this paper, we propose a clean and general framework to learn semantics directly from speech with semi-supervision from transcribed or untranscribed speech to address these issues. Our framework is built upon pretrained end-to-end (E2E) ASR and self-supervised language models, such as BERT, and fine-tuned on a limited amount of target SLU data. We study two semi-supervised settings for the ASR component: supervised pretraining on transcribed speech, and unsupervised pretraining by replacing the ASR encoder with self-supervised speech representations, such as wav2vec. In parallel, we identify two essential criteria for evaluating SLU models: environmental noise-robustness and E2E semantics evaluation. Experiments on ATIS show that our SLU framework with speech as input can perform on par with those using oracle text as input in semantics understanding, even though environmental noise is present and a limited amount of labeled semantics data is available for training.