 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-GRPO: Co-Optimized Group Relative Policy Optimization for Masked Diffusion Model
Dec 25, 2025Recently, Masked Diffusion Models (MDMs) have shown promising potential across vision, language, and cross-modal generation. However, a notable discrepancy exists between their training and inference procedures. In particular, MDM inference is a multi-step, iterative process governed not only by the model itself but also by various schedules that dictate the token-decoding trajectory (e.g., how many tokens to decode at each step). In contrast, MDMs are typically trained using a simplified, single-step BERT-style objective that masks a subset of tokens and predicts all of them simultaneously. This step-level simplification fundamentally disconnects the training paradigm from the trajectory-level nature of inference, leaving the inference schedules never optimized during training. In this paper, we introduce Co-GRPO, which reformulates MDM generation as a unified Markov Decision Process (MDP) that jointly incorporates both the model and the inference schedule. By applying Group Relative Policy Optimization at the trajectory level, Co-GRPO cooperatively optimizes model parameters and schedule parameters under a shared reward, without requiring costly backpropagation through the multi-step generation process. This holistic optimization aligns training with inference more thoroughly and substantially improves generation quality. Empirical results across four benchmarks-ImageReward, HPS, GenEval, and DPG-Bench-demonstrate the effectiveness of our approach. For more details, please refer to our project page: https://co-grpo.github.io/ .
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
Step by Step Network
Nov 18, 2025Scaling up network depth is a fundamental pursuit in neural architecture design, as theory suggests that deeper models offer exponentially greater capability. Benefiting from the residual connections, modern neural networks can scale up to more than one hundred layers and enjoy wide success. However, as networks continue to deepen, current architectures often struggle to realize their theoretical capacity improvements, calling for more advanced designs to further unleash the potential of deeper networks. In this paper, we identify two key barriers that obstruct residual models from scaling deeper: shortcut degradation and limited width. Shortcut degradation hinders deep-layer learning, while the inherent depth-width trade-off imposes limited width. To mitigate these issues, we propose a generalized residual architecture dubbed Step by Step Network (StepsNet) to bridge the gap between theoretical potential and practical performance of deep models. Specifically, we separate features along the channel dimension and let the model learn progressively via stacking blocks with increasing width. The resulting method mitigates the two identified problems and serves as a versatile macro design applicable to various models. Extensive experiments show that our method consistently outperforms residual models across diverse tasks, including image classification, object detection, semantic segmentation, and language modeling. These results position StepsNet as a superior generalization of the widely adopted residual architecture.
Deep learning EPI-TIRF cross-modality enables background subtraction and axial super-resolution for widefield fluorescence microscopy
Nov 10, 2025


The resolving ability of wide-field fluorescence microscopy is fundamentally limited by out-of-focus background owing to its low axial resolution, particularly for densely labeled biological samples. To address this, we developed ET2dNet, a deep learning-based EPI-TIRF cross-modality network that achieves TIRF-comparable background subtraction and axial super-resolution from a single wide-field image without requiring hardware modifications. The model employs a physics-informed hybrid architecture, synergizing supervised learning with registered EPI-TIRF image pairs and self-supervised physical modeling via convolution with the point spread function. This framework ensures exceptional generalization across microscope objectives, enabling few-shot adaptation to new imaging setups. Rigorous validation on cellular and tissue samples confirms ET2dNet's superiority in background suppression and axial resolution enhancement, while maintaining compatibility with deconvolution techniques for lateral resolution improvement. Furthermore, by extending this paradigm through knowledge distillation, we developed ET3dNet, a dedicated three-dimensional reconstruction network that produces artifact-reduced volumetric results. ET3dNet effectively removes out-of-focus background signals even when the input image stack lacks the source of background. This framework makes axial super-resolution imaging more accessible by providing an easy-to-deploy algorithm that avoids additional hardware costs and complexity, showing great potential for live cell studies and clinical histopathology.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
LGE-Guided Cross-Modality Contrastive Learning for Gadolinium-Free Cardiomyopathy Screening in Cine CMR
Aug 23, 2025Cardiomyopathy, a principal contributor to heart failure and sudden cardiac mortality, demands precise early screening. Cardiac Magnetic Resonance (CMR), recognized as the diagnostic 'gold standard' through multiparametric protocols, holds the potential to serve as an accurate screening tool. However, its reliance on gadolinium contrast and labor-intensive interpretation hinders population-scale deployment. We propose CC-CMR, a Contrastive Learning and Cross-Modal alignment framework for gadolinium-free cardiomyopathy screening using cine CMR sequences. By aligning the latent spaces of cine CMR and Late Gadolinium Enhancement (LGE) sequences, our model encodes fibrosis-specific pathology into cine CMR embeddings. A Feature Interaction Module concurrently optimizes diagnostic precision and cross-modal feature congruence, augmented by an uncertainty-guided adaptive training mechanism that dynamically calibrates task-specific objectives to ensure model generalizability. Evaluated on multi-center data from 231 subjects, CC-CMR achieves accuracy of 0.943 (95% CI: 0.886-0.986), outperforming state-of-the-art cine-CMR-only models by 4.3% while eliminating gadolinium dependency, demonstrating its clinical viability for wide range of populations and healthcare environments.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025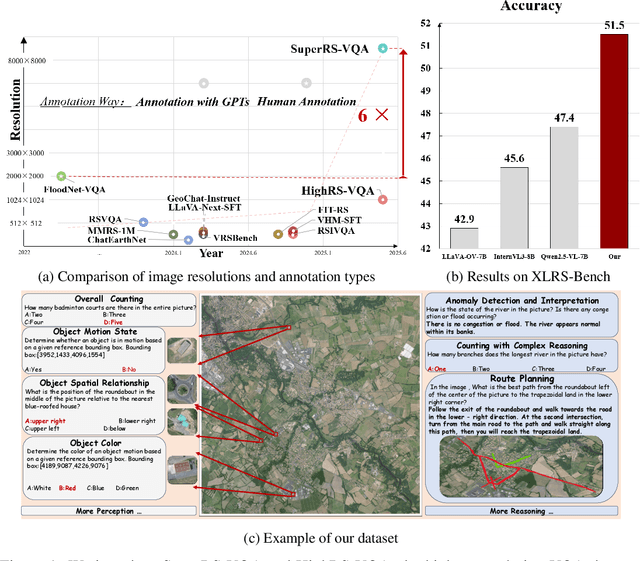

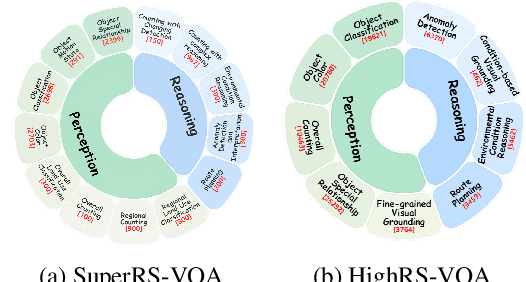

Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
CheXWorld: Exploring Image World Modeling for Radiograph Representation Learning
Apr 18, 2025



Humans can develop internal world models that encode common sense knowledge, telling them how the world works and predicting the consequences of their actions. This concept has emerged as a promising direction for establishing general-purpose machine-learning models in recent preliminary works, e.g., for visual representation learning. In this paper, we present CheXWorld, the first effort towards a self-supervised world model for radiographic images. Specifically, our work develops a unified framework that simultaneously models three aspects of medical knowledge essential for qualified radiologists, including 1) local anatomical structures describing the fine-grained characteristics of local tissues (e.g., architectures, shapes, and textures); 2) global anatomical layouts describing the global organization of the human body (e.g., layouts of organs and skeletons); and 3) domain variations that encourage CheXWorld to model the transitions across different appearance domains of radiographs (e.g., varying clarity, contrast, and exposure caused by collecting radiographs from different hospitals, devices, or patients). Empirically, we design tailored qualitative and quantitative analyses, revealing that CheXWorld successfully captures these three dimensions of medical knowledge. Furthermore, transfer learning experiments across eight medical image classification and segmentation benchmarks showcase that CheXWorld significantly outperforms existing SSL methods and large-scale medical foundation models. Code & pre-trained models are available at https://github.com/LeapLabTHU/CheXWorld.
EchoWorld: Learning Motion-Aware World Models for Echocardiography Probe Guidance
Apr 17, 2025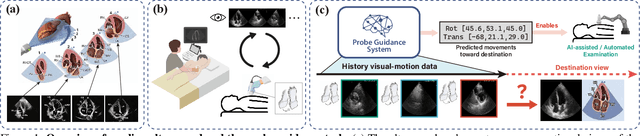


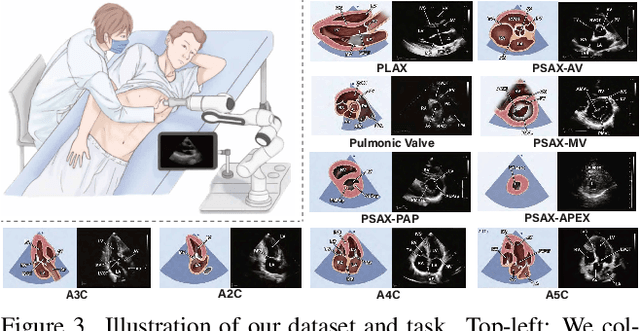
Echocardiography is crucial for cardiovascular disease detection but relies heavily on experienced sonographers. Echocardiography probe guidance systems, which provide real-time movement instructions for acquiring standard plane images, offer a promising solution for AI-assisted or fully autonomous scanning. However, developing effective machine learning models for this task remains challenging, as they must grasp heart anatomy and the intricate interplay between probe motion and visual signals. To address this, we present EchoWorld, a motion-aware world modeling framework for probe guidance that encodes anatomical knowledge and motion-induced visual dynamics, while effectively leveraging past visual-motion sequences to enhance guidance precision. EchoWorld employs a pre-training strategy inspired by world modeling principles, where the model predicts masked anatomical regions and simulates the visual outcomes of probe adjustments. Built upon this pre-trained model, we introduce a motion-aware attention mechanism in the fine-tuning stage that effectively integrates historical visual-motion data, enabling precise and adaptive probe guidance. Trained on more than one million ultrasound images from over 200 routine scans, EchoWorld effectively captures key echocardiographic knowledge, as validated by qualitative analysis. Moreover, our method significantly reduces guidance errors compared to existing visual backbones and guidance frameworks, excelling in both single-frame and sequential evaluation protocols. Code is available at https://github.com/LeapLabTHU/EchoWorld.
XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery?
Mar 31, 2025The astonishing breakthrough of multimodal large language models (MLLMs) has necessitated new benchmarks to quantitatively assess their capabilities, reveal their limitations, and indicate future research directions. However, this is challenging in the context of remote sensing (RS), since the imagery features ultra-high resolution that incorporates extremely complex semantic relationships. Existing benchmarks usually adopt notably smaller image sizes than real-world RS scenarios, suffer from limited annotation quality, and consider insufficient dimensions of evaluation. To address these issues, we present XLRS-Bench: a comprehensive benchmark for evaluating the perception and reasoning capabilities of MLLMs in ultra-high-resolution RS scenarios. XLRS-Bench boasts the largest average image size (8500$\times$8500) observed thus far, with all evaluation samples meticulously annotated manually, assisted by a novel semi-automatic captioner on ultra-high-resolution RS images. On top of the XLRS-Bench, 16 sub-tasks are defined to evaluate MLLMs' 10 kinds of perceptual capabilities and 6 kinds of reasoning capabilities, with a primary emphasis on advanced cognitive processes that facilitate real-world decision-making and the capture of spatiotemporal changes. The results of both general and RS-focused MLLMs on XLRS-Bench indicate that further efforts are needed for real-world RS applications. We have open-sourced XLRS-Bench to support further research in developing more powerful MLLMs for remote sensing.