 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Foundation Model for Calcium-imaging Population Dynamics
Apr 03, 2026Recent work suggests that large-scale, multi-animal modeling can significantly improve neural recording analysis. However, for functional calcium traces, existing approaches remain task-specific, limiting transfer across common neuroscience objectives. To address this challenge, we propose \textbf{CalM}, a self-supervised neural foundation model trained solely on neuronal calcium traces and adaptable to multiple downstream tasks, including forecasting and decoding. Our key contribution is a pretraining framework, composed of a high-performance tokenizer mapping single-neuron traces into a shared discrete vocabulary, and a dual-axis autoregressive transformer modeling dependencies along both the neural and the temporal axis. We evaluate CalM on a large-scale, multi-animal, multi-session dataset. On the neural population dynamics forecasting task, CalM outperforms strong specialized baselines after pretraining. With a task-specific head, CalM further adapts to the behavior decoding task and achieves superior results compared with supervised decoding models. Moreover, linear analyses of CalM representations reveal interpretable functional structures beyond predictive accuracy. Taken together, we propose a novel and effective self-supervised pretraining paradigm for foundation models based on calcium traces, paving the way for scalable pretraining and broad applications in functional neural analysis. Code will be released soon.
AdaFocusV3: On Unified Spatial-temporal Dynamic Video Recognition
Sep 27, 2022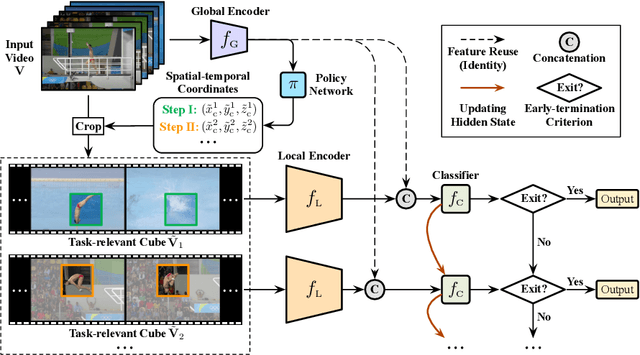
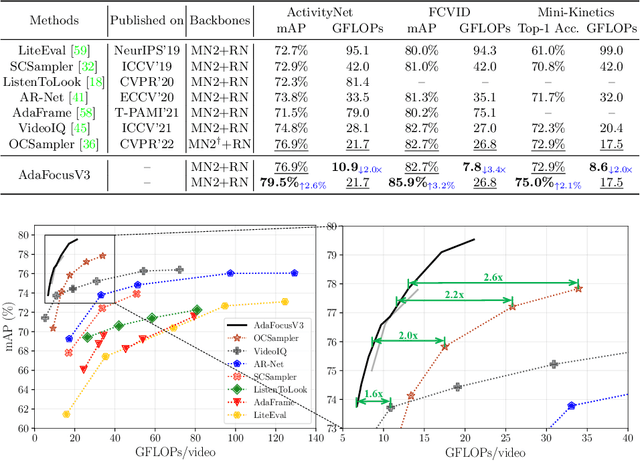
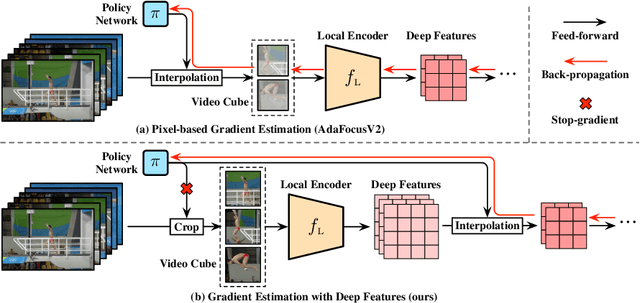
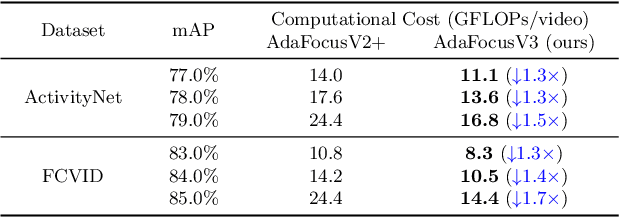
Recent research has revealed that reducing the temporal and spatial redundancy are both effective approaches towards efficient video recognition, e.g., allocating the majority of computation to a task-relevant subset of frames or the most valuable image regions of each frame. However, in most existing works, either type of redundancy is typically modeled with another absent. This paper explores the unified formulation of spatial-temporal dynamic computation on top of the recently proposed AdaFocusV2 algorithm, contributing to an improved AdaFocusV3 framework. Our method reduces the computational cost by activating the expensive high-capacity network only on some small but informative 3D video cubes. These cubes are cropped from the space formed by frame height, width, and video duration, while their locations are adaptively determined with a light-weighted policy network on a per-sample basis. At test time, the number of the cubes corresponding to each video is dynamically configured, i.e., video cubes are processed sequentially until a sufficiently reliable prediction is produced. Notably, AdaFocusV3 can be effectively trained by approximating the non-differentiable cropping operation with the interpolation of deep features. Extensive empirical results on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2 and Diving48) demonstrate that our model is considerably more efficient than competitive baselines.