 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-AGCNet: An End-to-End Framework for Joint Speech Enhancement and Loudness Control in Meeting Scenarios
Jun 24, 2026Conventional audio pipelines typically treat speech enhancement (SE) and automatic gain control (AGC) as discrete modules, which often limits overall performance. For instance, applying AGC before SE may inadvertently amplify background noise, while prioritizing SE tends to over-suppress low-volume speech. To address these limitations, we propose SE-AGCNet, an end-to-end framework that jointly optimizes SE and AGC. Tailored for meeting scenarios with significant volume variations, SE-AGCNet leverages the synergy between the two tasks: SE preserves quiet speech, thereby facilitating effective volume adjustment by the AGC component. Furthermore, we propose a specialized data simulation pipeline, SE-AGC-DataGen, and incorporate standardized loudness evaluation metrics: integrated loudness (LUFS), short-term loudness (St LUFS), and LRA. Experiments show that SE-AGCNet consistently achieves target loudness while improving speech quality and ASR accuracy over competitive baselines.
Pareto-Guided Optimization for Uncertainty-Aware Medical Image Segmentation
Jan 27, 2026Uncertainty in medical image segmentation is inherently non-uniform, with boundary regions exhibiting substantially higher ambiguity than interior areas. Conventional training treats all pixels equally, leading to unstable optimization during early epochs when predictions are unreliable. We argue that this instability hinders convergence toward Pareto-optimal solutions and propose a region-wise curriculum strategy that prioritizes learning from certain regions and gradually incorporates uncertain ones, reducing gradient variance. Methodologically, we introduce a Pareto-consistent loss that balances trade-offs between regional uncertainties by adaptively reshaping the loss landscape and constraining convergence dynamics between interior and boundary regions; this guides the model toward Pareto-approximate solutions. To address boundary ambiguity, we further develop a fuzzy labeling mechanism that maintains binary confidence in non-boundary areas while enabling smooth transitions near boundaries, stabilizing gradients, and expanding flat regions in the loss surface. Experiments on brain metastasis and non-metastatic tumor segmentation show consistent improvements across multiple configurations, with our method outperforming traditional crisp-set approaches in all tumor subregions.
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
May 28, 2025Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys -- the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
VisAlgae 2023: A Dataset and Challenge for Algae Detection in Microscopy Images
May 27, 2025Microalgae, vital for ecological balance and economic sectors, present challenges in detection due to their diverse sizes and conditions. This paper summarizes the second "Vision Meets Algae" (VisAlgae 2023) Challenge, aiming to enhance high-throughput microalgae cell detection. The challenge, which attracted 369 participating teams, includes a dataset of 1000 images across six classes, featuring microalgae of varying sizes and distinct features. Participants faced tasks such as detecting small targets, handling motion blur, and complex backgrounds. The top 10 methods, outlined here, offer insights into overcoming these challenges and maximizing detection accuracy. This intersection of algae research and computer vision offers promise for ecological understanding and technological advancement. The dataset can be accessed at: https://github.com/juntaoJianggavin/Visalgae2023/.
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
May 22, 2025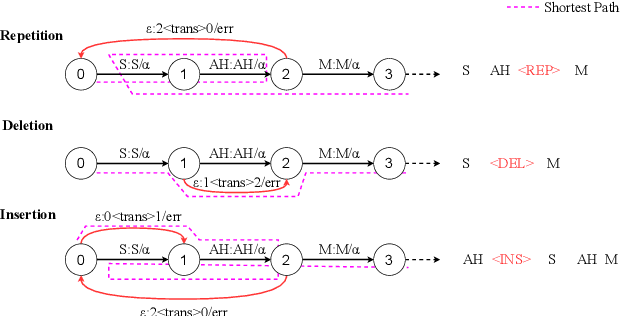

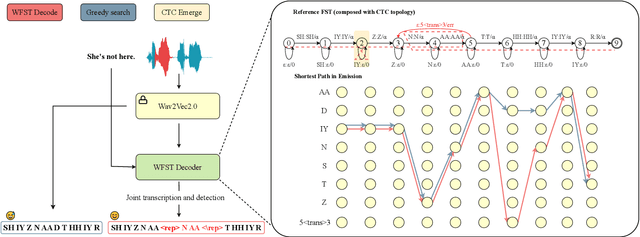
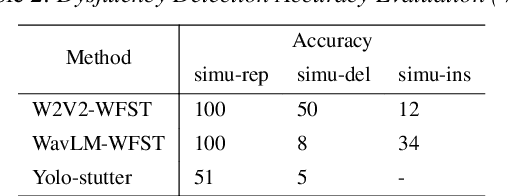
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.
Learning to Play Like Humans: A Framework for LLM Adaptation in Interactive Fiction Games
May 18, 2025Interactive Fiction games (IF games) are where players interact through natural language commands. While recent advances in Artificial Intelligence agents have reignited interest in IF games as a domain for studying decision-making, existing approaches prioritize task-specific performance metrics over human-like comprehension of narrative context and gameplay logic. This work presents a cognitively inspired framework that guides Large Language Models (LLMs) to learn and play IF games systematically. Our proposed **L**earning to **P**lay **L**ike **H**umans (LPLH) framework integrates three key components: (1) structured map building to capture spatial and narrative relationships, (2) action learning to identify context-appropriate commands, and (3) feedback-driven experience analysis to refine decision-making over time. By aligning LLMs-based agents' behavior with narrative intent and commonsense constraints, LPLH moves beyond purely exploratory strategies to deliver more interpretable, human-like performance. Crucially, this approach draws on cognitive science principles to more closely simulate how human players read, interpret, and respond within narrative worlds. As a result, LPLH reframes the IF games challenge as a learning problem for LLMs-based agents, offering a new path toward robust, context-aware gameplay in complex text-based environments.
TS-SatMVSNet: Slope Aware Height Estimation for Large-Scale Earth Terrain Multi-view Stereo
Jan 02, 2025



3D terrain reconstruction with remote sensing imagery achieves cost-effective and large-scale earth observation and is crucial for safeguarding natural disasters, monitoring ecological changes, and preserving the environment.Recently, learning-based multi-view stereo~(MVS) methods have shown promise in this task. However, these methods simply modify the general learning-based MVS framework for height estimation, which overlooks the terrain characteristics and results in insufficient accuracy. Considering that the Earth's surface generally undulates with no drastic changes and can be measured by slope, integrating slope considerations into MVS frameworks could enhance the accuracy of terrain reconstructions. To this end, we propose an end-to-end slope-aware height estimation network named TS-SatMVSNet for large-scale remote sensing terrain reconstruction.To effectively obtain the slope representation, drawing from mathematical gradient concepts, we innovatively proposed a height-based slope calculation strategy to first calculate a slope map from a height map to measure the terrain undulation. To fully integrate slope information into the MVS pipeline, we separately design two slope-guided modules to enhance reconstruction outcomes at both micro and macro levels. Specifically, at the micro level, we designed a slope-guided interval partition module for refined height estimation using slope values. At the macro level, a height correction module is proposed, using a learnable Gaussian smoothing operator to amend the inaccurate height values. Additionally, to enhance the efficacy of height estimation, we proposed a slope direction loss for implicitly optimizing height estimation results. Extensive experiments on the WHU-TLC dataset and MVS3D dataset show that our proposed method achieves state-of-the-art performance and demonstrates competitive generalization ability.
MLD-EA: Check and Complete Narrative Coherence by Introducing Emotions and Actions
Dec 03, 2024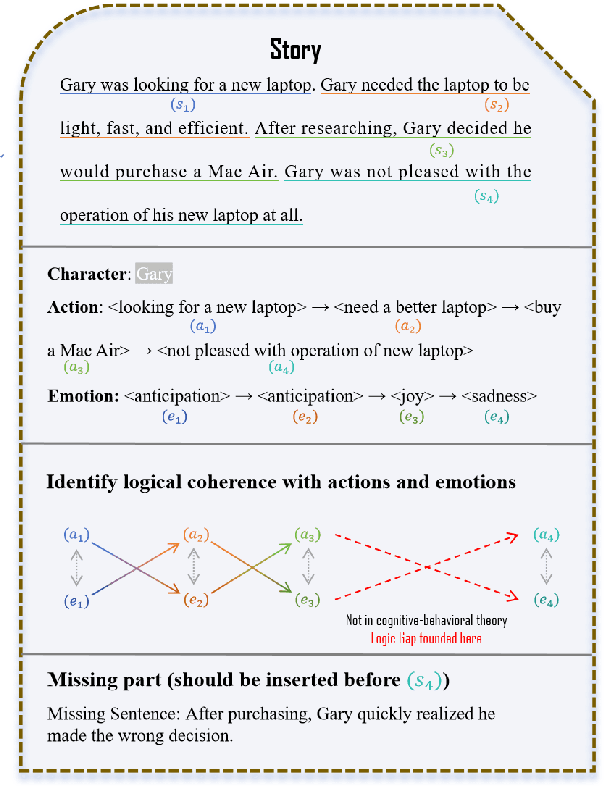
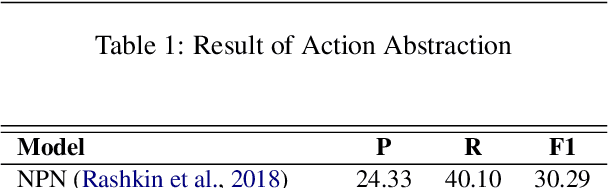
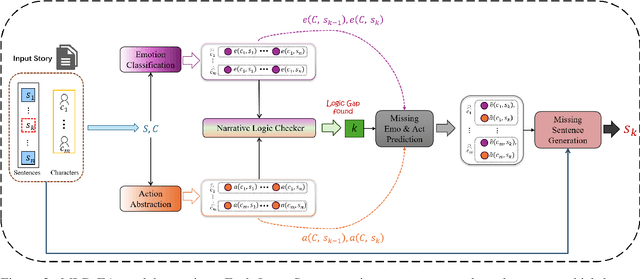

Narrative understanding and story generation are critical challenges in natural language processing (NLP), with much of the existing research focused on summarization and question-answering tasks. While previous studies have explored predicting plot endings and generating extended narratives, they often neglect the logical coherence within stories, leaving a significant gap in the field. To address this, we introduce the Missing Logic Detector by Emotion and Action (MLD-EA) model, which leverages large language models (LLMs) to identify narrative gaps and generate coherent sentences that integrate seamlessly with the story's emotional and logical flow. The experimental results demonstrate that the MLD-EA model enhances narrative understanding and story generation, highlighting LLMs' potential as effective logic checkers in story writing with logical coherence and emotional consistency. This work fills a gap in NLP research and advances border goals of creating more sophisticated and reliable story-generation systems.
Key Issues in Wireless Transmission for NTN-Assisted Internet of Things
Nov 25, 2023



Non-terrestrial networks (NTNs) have become appealing resolutions for seamless coverage in the next-generation wireless transmission, where a large number of Internet of Things (IoT) devices diversely distributed can be efficiently served. The explosively growing number of IoT devices brings a new challenge for massive connection. The long-distance wireless signal propagation in NTNs leads to severe path loss and large latency, where the accurate acquisition of channel state information (CSI) is another challenge, especially for fast-moving non-terrestrial base stations (NTBSs). Moreover, the scarcity of on-board resources of NTBSs is also a challenge for resource allocation. To this end, we investigate three key issues, where the existing schemes and emerging resolutions for these three key issues have been comprehensively presented. The first issue is to enable the massive connection by designing random access to establish the wireless link and multiple access to transmit data streams. The second issue is to accurately acquire CSI in various channel conditions by channel estimation and beam training, where orthogonal time frequency space modulation and dynamic codebooks are on focus. The third issue is to efficiently allocate the wireless resources, including power allocation, spectrum sharing, beam hopping, and beamforming. At the end of this article, some future research topics are identified.
Improving Generalization with Domain Convex Game
Mar 23, 2023Domain generalization (DG) tends to alleviate the poor generalization capability of deep neural networks by learning model with multiple source domains. A classical solution to DG is domain augmentation, the common belief of which is that diversifying source domains will be conducive to the out-of-distribution generalization. However, these claims are understood intuitively, rather than mathematically. Our explorations empirically reveal that the correlation between model generalization and the diversity of domains may be not strictly positive, which limits the effectiveness of domain augmentation. This work therefore aim to guarantee and further enhance the validity of this strand. To this end, we propose a new perspective on DG that recasts it as a convex game between domains. We first encourage each diversified domain to enhance model generalization by elaborately designing a regularization term based on supermodularity. Meanwhile, a sample filter is constructed to eliminate low-quality samples, thereby avoiding the impact of potentially harmful information. Our framework presents a new avenue for the formal analysis of DG, heuristic analysis and extensive experiments demonstrate the rationality and effectiveness.