 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Mapping Sparse Vector Transmission for Short Packet URLLC
Jan 22, 2026Sparse vector coding (SVC) is a promising short-packet transmission method for ultra reliable low latency communication (URLLC) in next generation communication systems. In this paper, a dual-mapping SVC (DM-SVC) based short packet transmission scheme is proposed to further enhance the transmission performance of SVC. The core idea behind the proposed scheme lies in mapping the transmitted information bits onto sparse vectors via block and single-element sparse mappings. The block sparse mapping pattern is able to concentrate the transmit power in a small number of non-zero blocks thus improving the decoding accuracy, while the single-element sparse mapping pattern ensures that the code length does not increase dramatically with the number of transmitted information bits. At the receiver, a two-stage decoding algorithm is proposed to sequentially identify non-zero block indexes and single-element non-zero indexes. Extensive simulation results verify that proposed DM-SVC scheme outperforms the existing SVC schemes in terms of block error rate and spectral efficiency.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
Automating Hardware Design and Verification from Architectural Papers via a Neural-Symbolic Graph Framework
Nov 08, 2025The reproduction of hardware architectures from academic papers remains a significant challenge due to the lack of publicly available source code and the complexity of hardware description languages (HDLs). To this end, we propose \textbf{ArchCraft}, a Framework that converts abstract architectural descriptions from academic papers into synthesizable Verilog projects with register-transfer level (RTL) verification. ArchCraft introduces a structured workflow, which uses formal graphs to capture the Architectural Blueprint and symbols to define the Functional Specification, translating unstructured academic papers into verifiable, hardware-aware designs. The framework then generates RTL and testbench (TB) code decoupled via these symbols to facilitate verification and debugging, ultimately reporting the circuit's Power, Area, and Performance (PPA). Moreover, we propose the first benchmark, \textbf{ArchSynthBench}, for synthesizing hardware from architectural descriptions, with a complete set of evaluation indicators, 50 project-level circuits, and around 600 circuit blocks. We systematically assess ArchCraft on ArchSynthBench, where the experiment results demonstrate the superiority of our proposed method, surpassing direct generation methods and the VerilogCoder framework in both paper understanding and code completion. Furthermore, evaluation and physical implementation of the generated executable RTL code show that these implementations meet all timing constraints without violations, and their performance metrics are consistent with those reported in the original papers.
DFT-s-OFDM with Chirp Modulation
Aug 06, 2025


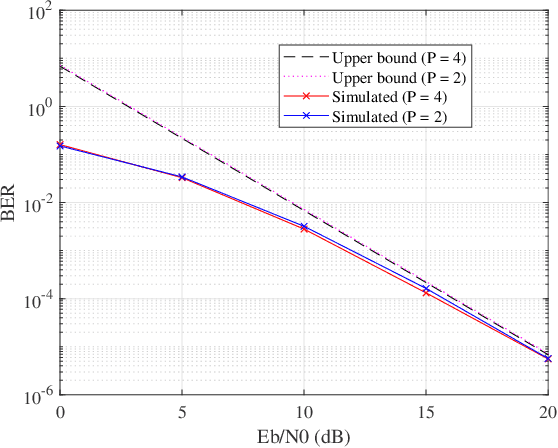
In this paper, a new waveform called discrete Fourier transform spread orthogonal frequency division multiplexing with chirp modulation (DFT-s-OFDM-CM) is proposed for the next generation of wireless communications. The information bits are conveyed by not only Q-ary constellation symbols but also the starting frequency of chirp signal. It could maintain the benefits provided by the chirped discrete Fourier transform spread orthogonal frequency division multiplexing (DFT-s-OFDM), e.g., low peak-to-average power ratio (PAPR), full frequency diversity exploitation, etc. Simulation results confirm that the proposed DFT-s-OFDM-CM could achieve higher spectral efficiency while keeping the similar bit error rate (BER) to that of chirped DFT-s-OFDM. In addition, when maintaining the same spectral efficiency, the proposed DFT-s-OFDM-CM with the splitting of information bits into two streams enables the use of lower-order constellation modulation and offers greater resilience to noise, resulting in a lower BER than the chirped DFT-s-OFDM.
Attributed Graph Clustering with Multi-Scale Weight-Based Pairwise Coarsening and Contrastive Learning
Jul 28, 2025



This study introduces the Multi-Scale Weight-Based Pairwise Coarsening and Contrastive Learning (MPCCL) model, a novel approach for attributed graph clustering that effectively bridges critical gaps in existing methods, including long-range dependency, feature collapse, and information loss. Traditional methods often struggle to capture high-order graph features due to their reliance on low-order attribute information, while contrastive learning techniques face limitations in feature diversity by overemphasizing local neighborhood structures. Similarly, conventional graph coarsening methods, though reducing graph scale, frequently lose fine-grained structural details. MPCCL addresses these challenges through an innovative multi-scale coarsening strategy, which progressively condenses the graph while prioritizing the merging of key edges based on global node similarity to preserve essential structural information. It further introduces a one-to-many contrastive learning paradigm, integrating node embeddings with augmented graph views and cluster centroids to enhance feature diversity, while mitigating feature masking issues caused by the accumulation of high-frequency node weights during multi-scale coarsening. By incorporating a graph reconstruction loss and KL divergence into its self-supervised learning framework, MPCCL ensures cross-scale consistency of node representations. Experimental evaluations reveal that MPCCL achieves a significant improvement in clustering performance, including a remarkable 15.24% increase in NMI on the ACM dataset and notable robust gains on smaller-scale datasets such as Citeseer, Cora and DBLP.
* The source code for this study is available at https://github.com/YF-W/MPCCL
Basis Expansion Extrapolation based Long-Term Channel Prediction for Massive MIMO OTFS Systems
Jul 02, 2025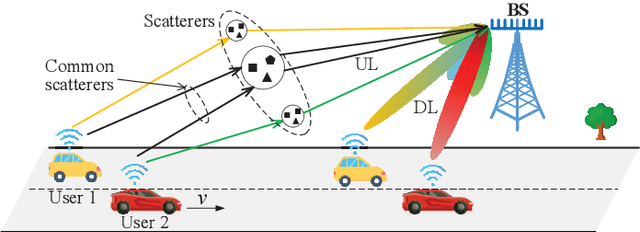
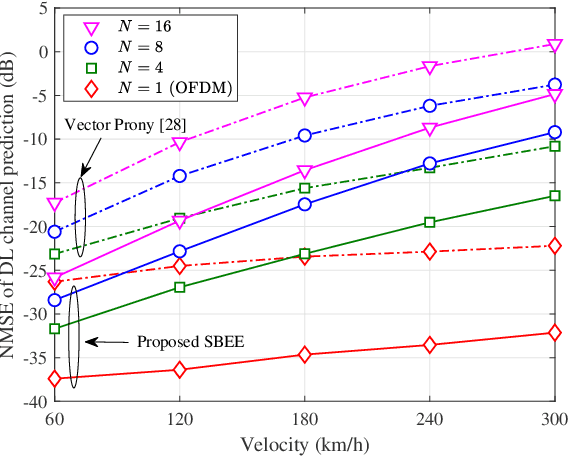
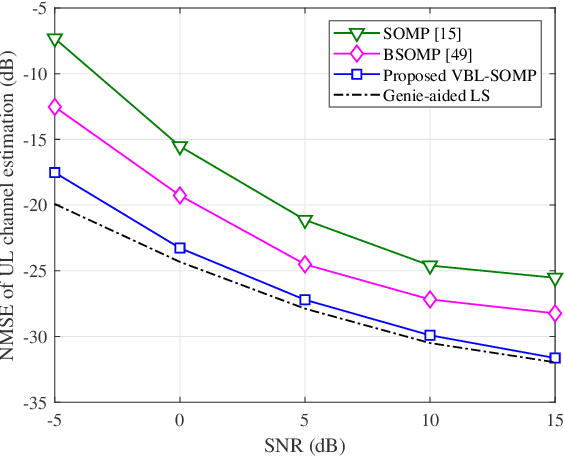
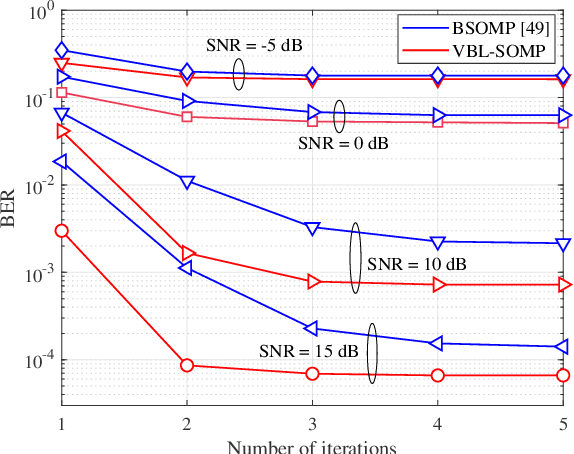
Massive multi-input multi-output (MIMO) combined with orthogonal time frequency space (OTFS) modulation has emerged as a promising technique for high-mobility scenarios. However, its performance could be severely degraded due to channel aging caused by user mobility and high processing latency. In this paper, an integrated scheme of uplink (UL) channel estimation and downlink (DL) channel prediction is proposed to alleviate channel aging in time division duplex (TDD) massive MIMO-OTFS systems. Specifically, first, an iterative basis expansion model (BEM) based UL channel estimation scheme is proposed to accurately estimate UL channels with the aid of carefully designed OTFS frame pattern. Then a set of Slepian sequences are used to model the estimated UL channels, and the dynamic Slepian coefficients are fitted by a set of orthogonal polynomials. A channel predictor is derived to predict DL channels by iteratively extrapolating the Slepian coefficients. Simulation results verify that the proposed UL channel estimation and DL channel prediction schemes outperform the existing schemes in terms of normalized mean square error of channel estimation/prediction and DL spectral efficiency, with less pilot overhead.
MOOSE-Chem2: Exploring LLM Limits in Fine-Grained Scientific Hypothesis Discovery via Hierarchical Search
May 25, 2025



Large language models (LLMs) have shown promise in automating scientific hypothesis generation, yet existing approaches primarily yield coarse-grained hypotheses lacking critical methodological and experimental details. We introduce and formally define the novel task of fine-grained scientific hypothesis discovery, which entails generating detailed, experimentally actionable hypotheses from coarse initial research directions. We frame this as a combinatorial optimization problem and investigate the upper limits of LLMs' capacity to solve it when maximally leveraged. Specifically, we explore four foundational questions: (1) how to best harness an LLM's internal heuristics to formulate the fine-grained hypothesis it itself would judge as the most promising among all the possible hypotheses it might generate, based on its own internal scoring-thus defining a latent reward landscape over the hypothesis space; (2) whether such LLM-judged better hypotheses exhibit stronger alignment with ground-truth hypotheses; (3) whether shaping the reward landscape using an ensemble of diverse LLMs of similar capacity yields better outcomes than defining it with repeated instances of the strongest LLM among them; and (4) whether an ensemble of identical LLMs provides a more reliable reward landscape than a single LLM. To address these questions, we propose a hierarchical search method that incrementally proposes and integrates details into the hypothesis, progressing from general concepts to specific experimental configurations. We show that this hierarchical process smooths the reward landscape and enables more effective optimization. Empirical evaluations on a new benchmark of expert-annotated fine-grained hypotheses from recent chemistry literature show that our method consistently outperforms strong baselines.
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Mar 27, 2025



Large language models (LLMs) have demonstrated potential in assisting scientific research, yet their ability to discover high-quality research hypotheses remains unexamined due to the lack of a dedicated benchmark. To address this gap, we introduce the first large-scale benchmark for evaluating LLMs with a near-sufficient set of sub-tasks of scientific discovery: inspiration retrieval, hypothesis composition, and hypothesis ranking. We develop an automated framework that extracts critical components - research questions, background surveys, inspirations, and hypotheses - from scientific papers across 12 disciplines, with expert validation confirming its accuracy. To prevent data contamination, we focus exclusively on papers published in 2024, ensuring minimal overlap with LLM pretraining data. Our evaluation reveals that LLMs perform well in retrieving inspirations, an out-of-distribution task, suggesting their ability to surface novel knowledge associations. This positions LLMs as "research hypothesis mines", capable of facilitating automated scientific discovery by generating innovative hypotheses at scale with minimal human intervention.
Neural Network Surrogate Model for Junction Temperature and Hotspot Position in $3$D Multi-Layer High Bandwidth Memory (HBM) Chiplets under Varying Thermal Conditions
Mar 06, 2025As the demand for computational power increases, high-bandwidth memory (HBM) has become a critical technology for next-generation computing systems. However, the widespread adoption of HBM presents significant thermal management challenges, particularly in multilayer through-silicon-via (TSV) stacked structures under varying thermal conditions, where accurate prediction of junction temperature and hotspot position is essential during the early design. This work develops a data-driven neural network model for the fast prediction of junction temperature and hotspot position in 3D HBM chiplets. The model, trained with a data set of $13,494$ different combinations of thermal condition parameters, sampled from a vast parameter space characterized by high-dimensional combination (up to $3^{27}$), can accurately and quickly infer the junction temperature and hotspot position for any thermal conditions in the parameter space. Moreover, it shows good generalizability for other thermal conditions not considered in the parameter space. The data set is constructed using accurate finite element solvers. This method not only minimizes the reliance on costly experimental tests and extensive computational resources for finite element analysis but also accelerates the design and optimization of complex HBM systems, making it a valuable tool for improving thermal management and performance in high-performance computing applications.
XRAG: eXamining the Core -- Benchmarking Foundational Components in Advanced Retrieval-Augmented Generation
Dec 24, 2024Retrieval-augmented generation (RAG) synergizes the retrieval of pertinent data with the generative capabilities of Large Language Models (LLMs), ensuring that the generated output is not only contextually relevant but also accurate and current. We introduce XRAG, an open-source, modular codebase that facilitates exhaustive evaluation of the performance of foundational components of advanced RAG modules. These components are systematically categorized into four core phases: pre-retrieval, retrieval, post-retrieval, and generation. We systematically analyse them across reconfigured datasets, providing a comprehensive benchmark for their effectiveness. As the complexity of RAG systems continues to escalate, we underscore the critical need to identify potential failure points in RAG systems. We formulate a suite of experimental methodologies and diagnostic testing protocols to dissect the failure points inherent in RAG engineering. Subsequently, we proffer bespoke solutions aimed at bolstering the overall performance of these modules. Our work thoroughly evaluates the performance of advanced core components in RAG systems, providing insights into optimizations for prevalent failure points.