 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Dynamic Modeling of Cable-Driven Continuum Robots Based on Actuation-Space Energy Formulation
Dec 15, 2025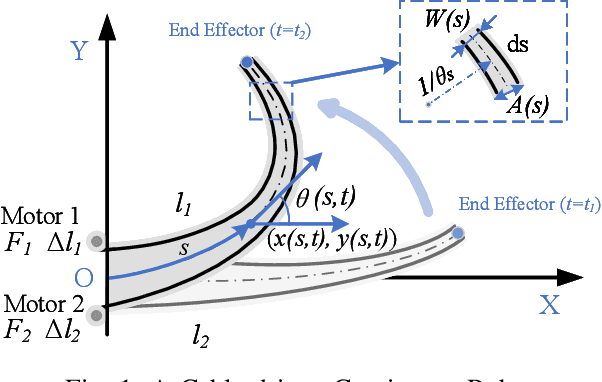
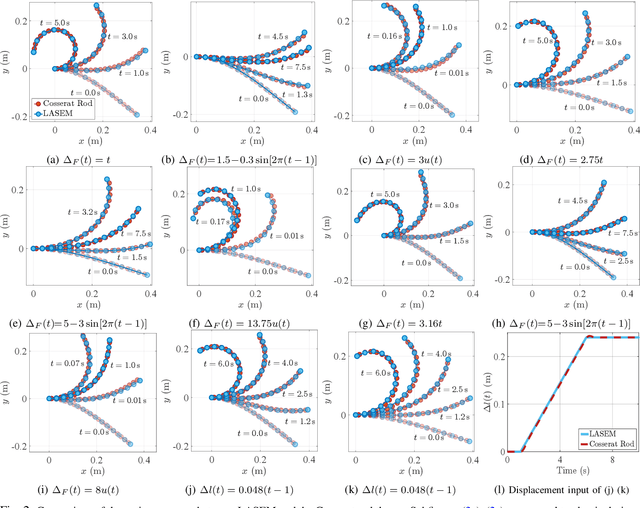
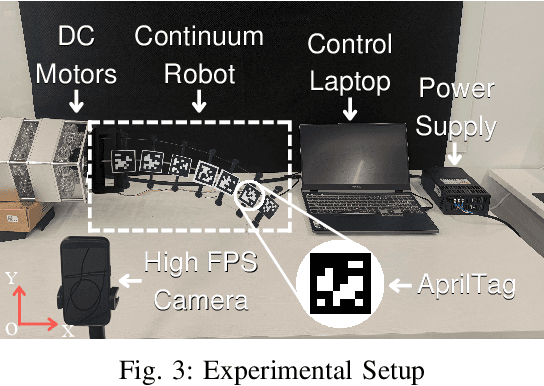
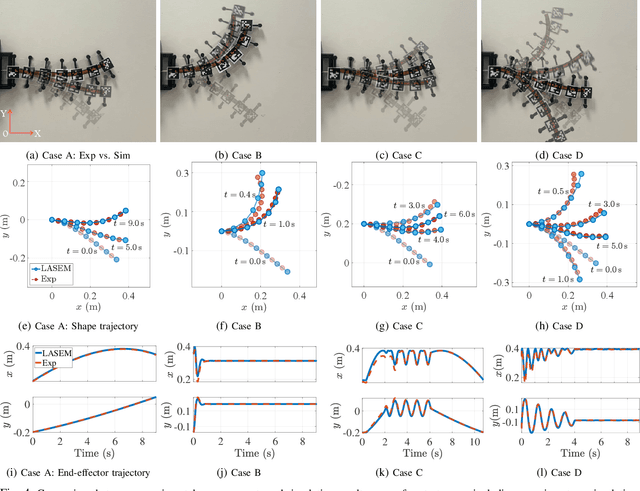
Cable-driven continuum robots (CDCRs) require accurate, real-time dynamic models for high-speed dynamics prediction or model-based control, making such capability an urgent need. In this paper, we propose the Lightweight Actuation-Space Energy Modeling (LASEM) framework for CDCRs, which formulates actuation potential energy directly in actuation space to enable lightweight yet accurate dynamic modeling. Through a unified variational derivation, the governing dynamics reduce to a single partial differential equation (PDE), requiring only the Euler moment balance while implicitly incorporating the Newton force balance. By also avoiding explicit computation of cable-backbone contact forces, the formulation simplifies the model structure and improves computational efficiency while preserving geometric accuracy and physical consistency. Importantly, the proposed framework for dynamic modeling natively supports both force-input and displacement-input actuation modes, a capability seldom achieved in existing dynamic formulations. Leveraging this lightweight structure, a Galerkin space-time modal discretization with analytical time-domain derivatives of the reduced state further enables an average 62.3% computational speedup over state-of-the-art real-time dynamic modeling approaches.
VocalBench-zh: Decomposing and Benchmarking the Speech Conversational Abilities in Mandarin Context
Nov 17, 2025



The development of multi-modal large language models (LLMs) leads to intelligent approaches capable of speech interactions. As one of the most widely spoken languages globally, Mandarin is supported by most models to enhance their applicability and reach. However, the scarcity of comprehensive speech-to-speech (S2S) benchmarks in Mandarin contexts impedes systematic evaluation for developers and hinders fair model comparison for users. In this work, we propose VocalBench-zh, an ability-level divided evaluation suite adapted to Mandarin context consisting of 10 well-crafted subsets and over 10K high-quality instances, covering 12 user-oriented characters. The evaluation experiment on 14 mainstream models reveals the common challenges for current routes, and highlights the need for new insights into next-generation speech interactive systems. The evaluation codes and datasets will be available at https://github.com/SJTU-OmniAgent/VocalBench-zh.
W2S-AlignTree: Weak-to-Strong Inference-Time Alignment for Large Language Models via Monte Carlo Tree Search
Nov 14, 2025



Large Language Models (LLMs) demonstrate impressive capabilities, yet their outputs often suffer from misalignment with human preferences due to the inadequacy of weak supervision and a lack of fine-grained control. Training-time alignment methods like Reinforcement Learning from Human Feedback (RLHF) face prohibitive costs in expert supervision and inherent scalability limitations, offering limited dynamic control during inference. Consequently, there is an urgent need for scalable and adaptable alignment mechanisms. To address this, we propose W2S-AlignTree, a pioneering plug-and-play inference-time alignment framework that synergistically combines Monte Carlo Tree Search (MCTS) with the Weak-to-Strong Generalization paradigm for the first time. W2S-AlignTree formulates LLM alignment as an optimal heuristic search problem within a generative search tree. By leveraging weak model's real-time, step-level signals as alignment proxies and introducing an Entropy-Aware exploration mechanism, W2S-AlignTree enables fine-grained guidance during strong model's generation without modifying its parameters. The approach dynamically balances exploration and exploitation in high-dimensional generation search trees. Experiments across controlled sentiment generation, summarization, and instruction-following show that W2S-AlignTree consistently outperforms strong baselines. Notably, W2S-AlignTree raises the performance of Llama3-8B from 1.89 to 2.19, a relative improvement of 15.9 on the summarization task.
VocalNet-M2: Advancing Low-Latency Spoken Language Modeling via Integrated Multi-Codebook Tokenization and Multi-Token Prediction
Nov 13, 2025Current end-to-end spoken language models (SLMs) have made notable progress, yet they still encounter considerable response latency. This delay primarily arises from the autoregressive generation of speech tokens and the reliance on complex flow-matching models for speech synthesis. To overcome this, we introduce VocalNet-M2, a novel low-latency SLM that integrates a multi-codebook tokenizer and a multi-token prediction (MTP) strategy. Our model directly generates multi-codebook speech tokens, thus eliminating the need for a latency-inducing flow-matching model. Furthermore, our MTP strategy enhances generation efficiency and improves overall performance. Extensive experiments demonstrate that VocalNet-M2 achieves a substantial reduction in first chunk latency (from approximately 725ms to 350ms) while maintaining competitive performance across mainstream SLMs. This work also provides a comprehensive comparison of single-codebook and multi-codebook strategies, offering valuable insights for developing efficient and high-performance SLMs for real-time interactive applications.
Efficient Reasoning via Reward Model
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has been shown to enhance the reasoning capabilities of large language models (LLMs), enabling the development of large reasoning models (LRMs). However, LRMs such as DeepSeek-R1 and OpenAI o1 often generate verbose responses containing redundant or irrelevant reasoning step-a phenomenon known as overthinking-which substantially increases computational costs. Prior efforts to mitigate this issue commonly incorporate length penalties into the reward function, but we find they frequently suffer from two critical issues: length collapse and training collapse, resulting in sub-optimal performance. To address them, we propose a pipeline for training a Conciseness Reward Model (CRM) that scores the conciseness of reasoning path. Additionally, we introduce a novel reward formulation named Conciseness Reward Function (CRF) with explicit dependency between the outcome reward and conciseness score, thereby fostering both more effective and more efficient reasoning. From a theoretical standpoint, we demonstrate the superiority of the new reward from the perspective of variance reduction and improved convergence properties. Besides, on the practical side, extensive experiments on five mathematical benchmark datasets demonstrate the method's effectiveness and token efficiency, which achieves an 8.1% accuracy improvement and a 19.9% reduction in response token length on Qwen2.5-7B. Furthermore, the method generalizes well to other LLMs including Llama and Mistral. The implementation code and datasets are publicly available for reproduction: https://anonymous.4open.science/r/CRM.
PEOD: A Pixel-Aligned Event-RGB Benchmark for Object Detection under Challenging Conditions
Nov 11, 2025Robust object detection for challenging scenarios increasingly relies on event cameras, yet existing Event-RGB datasets remain constrained by sparse coverage of extreme conditions and low spatial resolution (<= 640 x 480), which prevents comprehensive evaluation of detectors under challenging scenarios. To address these limitations, we propose PEOD, the first large-scale, pixel-aligned and high-resolution (1280 x 720) Event-RGB dataset for object detection under challenge conditions. PEOD contains 130+ spatiotemporal-aligned sequences and 340k manual bounding boxes, with 57% of data captured under low-light, overexposure, and high-speed motion. Furthermore, we benchmark 14 methods across three input configurations (Event-based, RGB-based, and Event-RGB fusion) on PEOD. On the full test set and normal subset, fusion-based models achieve the excellent performance. However, in illumination challenge subset, the top event-based model outperforms all fusion models, while fusion models still outperform their RGB-based counterparts, indicating limits of existing fusion methods when the frame modality is severely degraded. PEOD establishes a realistic, high-quality benchmark for multimodal perception and facilitates future research.
TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
Nov 07, 2025Retrieval-Augmented Generation (RAG) utilizes external knowledge to augment Large Language Models' (LLMs) reliability. For flexibility, agentic RAG employs autonomous, multi-round retrieval and reasoning to resolve queries. Although recent agentic RAG has improved via reinforcement learning, they often incur substantial token overhead from search and reasoning processes. This trade-off prioritizes accuracy over efficiency. To address this issue, this work proposes TeaRAG, a token-efficient agentic RAG framework capable of compressing both retrieval content and reasoning steps. 1) First, the retrieved content is compressed by augmenting chunk-based semantic retrieval with a graph retrieval using concise triplets. A knowledge association graph is then built from semantic similarity and co-occurrence. Finally, Personalized PageRank is leveraged to highlight key knowledge within this graph, reducing the number of tokens per retrieval. 2) Besides, to reduce reasoning steps, Iterative Process-aware Direct Preference Optimization (IP-DPO) is proposed. Specifically, our reward function evaluates the knowledge sufficiency by a knowledge matching mechanism, while penalizing excessive reasoning steps. This design can produce high-quality preference-pair datasets, supporting iterative DPO to improve reasoning conciseness. Across six datasets, TeaRAG improves the average Exact Match by 4% and 2% while reducing output tokens by 61% and 59% on Llama3-8B-Instruct and Qwen2.5-14B-Instruct, respectively. Code is available at https://github.com/Applied-Machine-Learning-Lab/TeaRAG.
AdaDoS: Adaptive DoS Attack via Deep Adversarial Reinforcement Learning in SDN
Oct 23, 2025Existing defence mechanisms have demonstrated significant effectiveness in mitigating rule-based Denial-of-Service (DoS) attacks, leveraging predefined signatures and static heuristics to identify and block malicious traffic. However, the emergence of AI-driven techniques presents new challenges to SDN security, potentially compromising the efficacy of existing defence mechanisms. In this paper, we introduce~AdaDoS, an adaptive attack model that disrupt network operations while evading detection by existing DoS-based detectors through adversarial reinforcement learning (RL). Specifically, AdaDoS models the problem as a competitive game between an attacker, whose goal is to obstruct network traffic without being detected, and a detector, which aims to identify malicious traffic. AdaDoS can solve this game by dynamically adjusting its attack strategy based on feedback from the SDN and the detector. Additionally, recognising that attackers typically have less information than defenders, AdaDoS formulates the DoS-like attack as a partially observed Markov decision process (POMDP), with the attacker having access only to delay information between attacker and victim nodes. We address this challenge with a novel reciprocal learning module, where the student agent, with limited observations, enhances its performance by learning from the teacher agent, who has full observational capabilities in the SDN environment. AdaDoS represents the first application of RL to develop DoS-like attack sequences, capable of adaptively evading both machine learning-based and rule-based DoS-like attack detectors.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
CS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Oct 09, 2025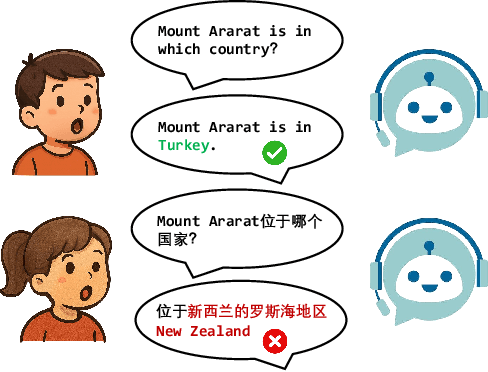

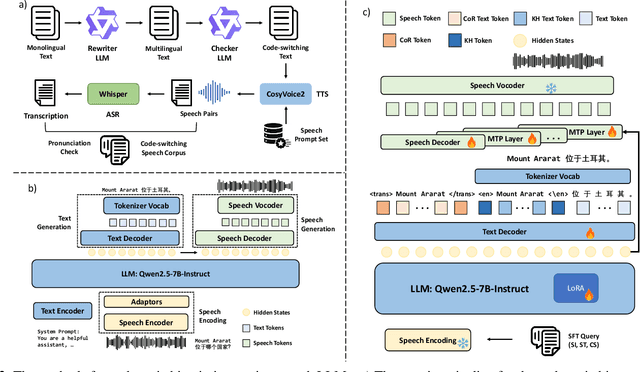
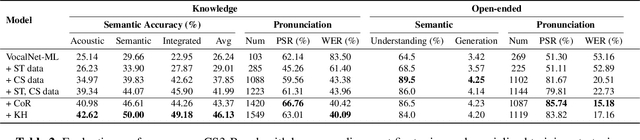
The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.