 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Spatial-Frequency Fusion Mamba for Multi-Modal Image Fusion
Feb 04, 2026Multi-Modal Image Fusion (MMIF) aims to combine images from different modalities to produce fused images, retaining texture details and preserving significant information. Recently, some MMIF methods incorporate frequency domain information to enhance spatial features. However, these methods typically rely on simple serial or parallel spatial-frequency fusion without interaction. In this paper, we propose a novel Interactive Spatial-Frequency Fusion Mamba (ISFM) framework for MMIF. Specifically, we begin with a Modality-Specific Extractor (MSE) to extract features from different modalities. It models long-range dependencies across the image with linear computational complexity. To effectively leverage frequency information, we then propose a Multi-scale Frequency Fusion (MFF). It adaptively integrates low-frequency and high-frequency components across multiple scales, enabling robust representations of frequency features. More importantly, we further propose an Interactive Spatial-Frequency Fusion (ISF). It incorporates frequency features to guide spatial features across modalities, enhancing complementary representations. Extensive experiments are conducted on six MMIF datasets. The experimental results demonstrate that our ISFM can achieve better performances than other state-of-the-art methods. The source code is available at https://github.com/Namn23/ISFM.
MambaTrack3D: A State Space Model Framework for LiDAR-Based Object Tracking under High Temporal Variation
Nov 19, 2025Dynamic outdoor environments with high temporal variation (HTV) pose significant challenges for 3D single object tracking in LiDAR point clouds. Existing memory-based trackers often suffer from quadratic computational complexity, temporal redundancy, and insufficient exploitation of geometric priors. To address these issues, we propose MambaTrack3D, a novel HTV-oriented tracking framework built upon the state space model Mamba. Specifically, we design a Mamba-based Inter-frame Propagation (MIP) module that replaces conventional single-frame feature extraction with efficient inter-frame propagation, achieving near-linear complexity while explicitly modeling spatial relations across historical frames. Furthermore, a Grouped Feature Enhancement Module (GFEM) is introduced to separate foreground and background semantics at the channel level, thereby mitigating temporal redundancy in the memory bank. Extensive experiments on KITTI-HTV and nuScenes-HTV benchmarks demonstrate that MambaTrack3D consistently outperforms both HTV-oriented and normal-scenario trackers, achieving improvements of up to 6.5 success and 9.5 precision over HVTrack under moderate temporal gaps. On the standard KITTI dataset, MambaTrack3D remains highly competitive with state-of-the-art normal-scenario trackers, confirming its strong generalization ability. Overall, MambaTrack3D achieves a superior accuracy-efficiency trade-off, delivering robust performance across both specialized HTV and conventional tracking scenarios.
Unity is Strength: Unifying Convolutional and Transformeral Features for Better Person Re-Identification
Dec 23, 2024Person Re-identification (ReID) aims to retrieve the specific person across non-overlapping cameras, which greatly helps intelligent transportation systems. As we all know, Convolutional Neural Networks (CNNs) and Transformers have the unique strengths to extract local and global features, respectively. Considering this fact, we focus on the mutual fusion between them to learn more comprehensive representations for persons. In particular, we utilize the complementary integration of deep features from different model structures. We propose a novel fusion framework called FusionReID to unify the strengths of CNNs and Transformers for image-based person ReID. More specifically, we first deploy a Dual-branch Feature Extraction (DFE) to extract features through CNNs and Transformers from a single image. Moreover, we design a novel Dual-attention Mutual Fusion (DMF) to achieve sufficient feature fusions. The DMF comprises Local Refinement Units (LRU) and Heterogenous Transmission Modules (HTM). LRU utilizes depth-separable convolutions to align deep features in channel dimensions and spatial sizes. HTM consists of a Shared Encoding Unit (SEU) and two Mutual Fusion Units (MFU). Through the continuous stacking of HTM, deep features after LRU are repeatedly utilized to generate more discriminative features. Extensive experiments on three public ReID benchmarks demonstrate that our method can attain superior performances than most state-of-the-arts. The source code is available at https://github.com/924973292/FusionReID.
MambaPro: Multi-Modal Object Re-Identification with Mamba Aggregation and Synergistic Prompt
Dec 14, 2024



Multi-modal object Re-IDentification (ReID) aims to retrieve specific objects by utilizing complementary image information from different modalities. Recently, large-scale pre-trained models like CLIP have demonstrated impressive performance in traditional single-modal object ReID tasks. However, they remain unexplored for multi-modal object ReID. Furthermore, current multi-modal aggregation methods have obvious limitations in dealing with long sequences from different modalities. To address above issues, we introduce a novel framework called MambaPro for multi-modal object ReID. To be specific, we first employ a Parallel Feed-Forward Adapter (PFA) for adapting CLIP to multi-modal object ReID. Then, we propose the Synergistic Residual Prompt (SRP) to guide the joint learning of multi-modal features. Finally, leveraging Mamba's superior scalability for long sequences, we introduce Mamba Aggregation (MA) to efficiently model interactions between different modalities. As a result, MambaPro could extract more robust features with lower complexity. Extensive experiments on three multi-modal object ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) validate the effectiveness of our proposed methods. The source code is available at https://github.com/924973292/MambaPro.
TF-CLIP: Learning Text-free CLIP for Video-based Person Re-Identification
Dec 15, 2023



Large-scale language-image pre-trained models (e.g., CLIP) have shown superior performances on many cross-modal retrieval tasks. However, the problem of transferring the knowledge learned from such models to video-based person re-identification (ReID) has barely been explored. In addition, there is a lack of decent text descriptions in current ReID benchmarks. To address these issues, in this work, we propose a novel one-stage text-free CLIP-based learning framework named TF-CLIP for video-based person ReID. More specifically, we extract the identity-specific sequence feature as the CLIP-Memory to replace the text feature. Meanwhile, we design a Sequence-Specific Prompt (SSP) module to update the CLIP-Memory online. To capture temporal information, we further propose a Temporal Memory Diffusion (TMD) module, which consists of two key components: Temporal Memory Construction (TMC) and Memory Diffusion (MD). Technically, TMC allows the frame-level memories in a sequence to communicate with each other, and to extract temporal information based on the relations within the sequence. MD further diffuses the temporal memories to each token in the original features to obtain more robust sequence features. Extensive experiments demonstrate that our proposed method shows much better results than other state-of-the-art methods on MARS, LS-VID and iLIDS-VID. The code is available at https://github.com/AsuradaYuci/TF-CLIP.
TOP-ReID: Multi-spectral Object Re-Identification with Token Permutation
Dec 15, 2023



Multi-spectral object Re-identification (ReID) aims to retrieve specific objects by leveraging complementary information from different image spectra. It delivers great advantages over traditional single-spectral ReID in complex visual environment. However, the significant distribution gap among different image spectra poses great challenges for effective multi-spectral feature representations. In addition, most of current Transformer-based ReID methods only utilize the global feature of class tokens to achieve the holistic retrieval, ignoring the local discriminative ones. To address the above issues, we step further to utilize all the tokens of Transformers and propose a cyclic token permutation framework for multi-spectral object ReID, dubbled TOP-ReID. More specifically, we first deploy a multi-stream deep network based on vision Transformers to preserve distinct information from different image spectra. Then, we propose a Token Permutation Module (TPM) for cyclic multi-spectral feature aggregation. It not only facilitates the spatial feature alignment across different image spectra, but also allows the class token of each spectrum to perceive the local details of other spectra. Meanwhile, we propose a Complementary Reconstruction Module (CRM), which introduces dense token-level reconstruction constraints to reduce the distribution gap across different image spectra. With the above modules, our proposed framework can generate more discriminative multi-spectral features for robust object ReID. Extensive experiments on three ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) verify the effectiveness of our methods. The code is available at https://github.com/924973292/TOP-ReID.
Video-based Person Re-identification with Long Short-Term Representation Learning
Aug 07, 2023



Video-based person Re-Identification (V-ReID) aims to retrieve specific persons from raw videos captured by non-overlapped cameras. As a fundamental task, it spreads many multimedia and computer vision applications. However, due to the variations of persons and scenes, there are still many obstacles that must be overcome for high performance. In this work, we notice that both the long-term and short-term information of persons are important for robust video representations. Thus, we propose a novel deep learning framework named Long Short-Term Representation Learning (LSTRL) for effective V-ReID. More specifically, to extract long-term representations, we propose a Multi-granularity Appearance Extractor (MAE), in which four granularity appearances are effectively captured across multiple frames. Meanwhile, to extract short-term representations, we propose a Bi-direction Motion Estimator (BME), in which reciprocal motion information is efficiently extracted from consecutive frames. The MAE and BME are plug-and-play and can be easily inserted into existing networks for efficient feature learning. As a result, they significantly improve the feature representation ability for V-ReID. Extensive experiments on three widely used benchmarks show that our proposed approach can deliver better performances than most state-of-the-arts.
Deeply-Coupled Convolution-Transformer with Spatial-temporal Complementary Learning for Video-based Person Re-identification
Apr 27, 2023



Advanced deep Convolutional Neural Networks (CNNs) have shown great success in video-based person Re-Identification (Re-ID). However, they usually focus on the most obvious regions of persons with a limited global representation ability. Recently, it witnesses that Transformers explore the inter-patch relations with global observations for performance improvements. In this work, we take both sides and propose a novel spatial-temporal complementary learning framework named Deeply-Coupled Convolution-Transformer (DCCT) for high-performance video-based person Re-ID. Firstly, we couple CNNs and Transformers to extract two kinds of visual features and experimentally verify their complementarity. Further, in spatial, we propose a Complementary Content Attention (CCA) to take advantages of the coupled structure and guide independent features for spatial complementary learning. In temporal, a Hierarchical Temporal Aggregation (HTA) is proposed to progressively capture the inter-frame dependencies and encode temporal information. Besides, a gated attention is utilized to deliver aggregated temporal information into the CNN and Transformer branches for temporal complementary learning. Finally, we introduce a self-distillation training strategy to transfer the superior spatial-temporal knowledge to backbone networks for higher accuracy and more efficiency. In this way, two kinds of typical features from same videos are integrated mechanically for more informative representations. Extensive experiments on four public Re-ID benchmarks demonstrate that our framework could attain better performances than most state-of-the-art methods.
A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification
Apr 05, 2021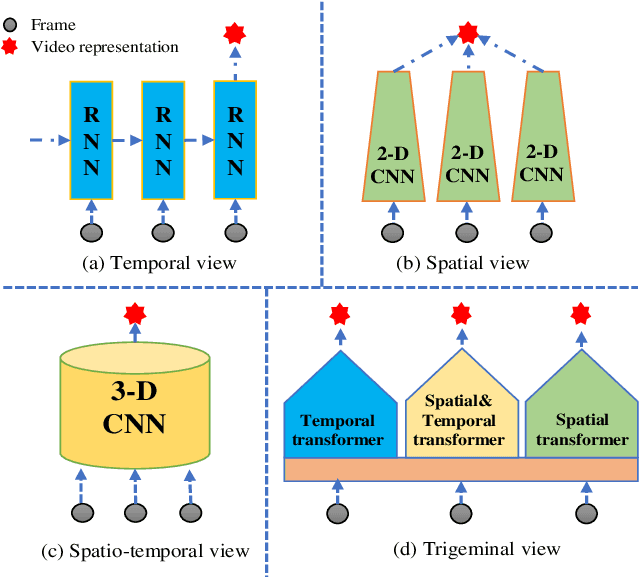
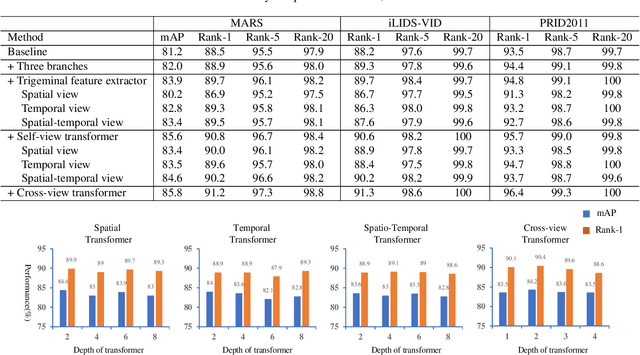
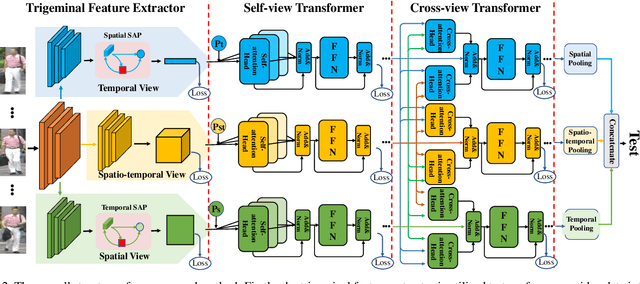
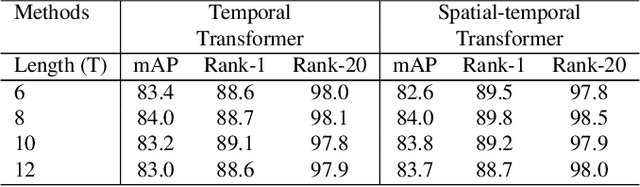
Video-based person re-identification (Re-ID) aims to retrieve video sequences of the same person under non-overlapping cameras. Previous methods usually focus on limited views, such as spatial, temporal or spatial-temporal view, which lack of the observations in different feature domains. To capture richer perceptions and extract more comprehensive video representations, in this paper we propose a novel framework named Trigeminal Transformers (TMT) for video-based person Re-ID. More specifically, we design a trigeminal feature extractor to jointly transform raw video data into spatial, temporal and spatial-temporal domain. Besides, inspired by the great success of vision transformer, we introduce the transformer structure for video-based person Re-ID. In our work, three self-view transformers are proposed to exploit the relationships between local features for information enhancement in spatial, temporal and spatial-temporal domains. Moreover, a cross-view transformer is proposed to aggregate the multi-view features for comprehensive video representations. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches on public Re-ID benchmarks. We will release the code for model reproduction.
Watching You: Global-guided Reciprocal Learning for Video-based Person Re-identification
Apr 01, 2021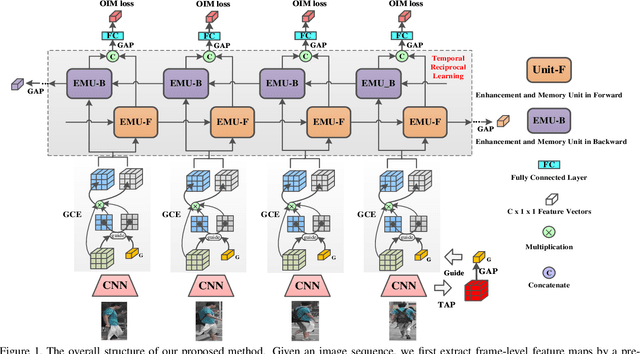
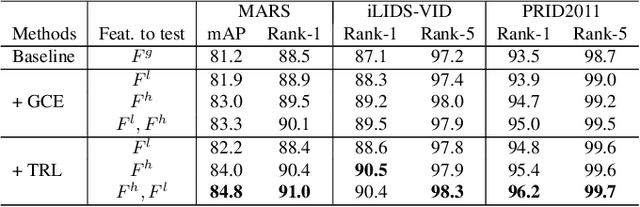
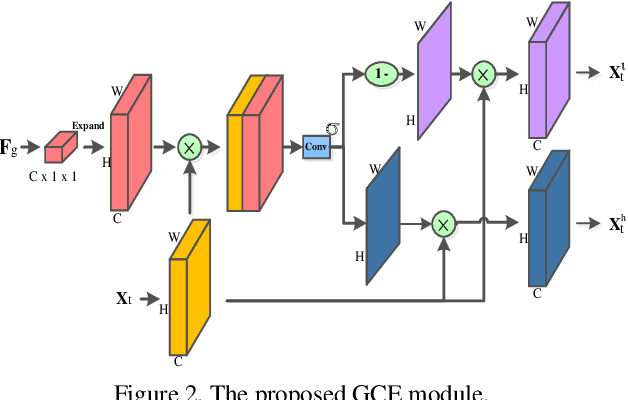
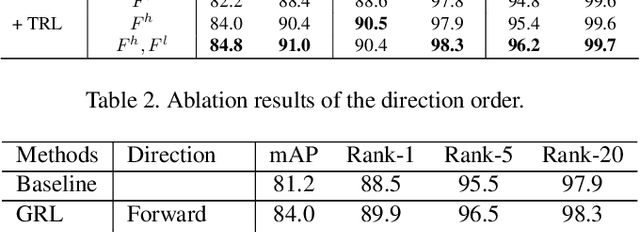
Video-based person re-identification (Re-ID) aims to automatically retrieve video sequences of the same person under non-overlapping cameras. To achieve this goal, it is the key to fully utilize abundant spatial and temporal cues in videos. Existing methods usually focus on the most conspicuous image regions, thus they may easily miss out fine-grained clues due to the person varieties in image sequences. To address above issues, in this paper, we propose a novel Global-guided Reciprocal Learning (GRL) framework for video-based person Re-ID. Specifically, we first propose a Global-guided Correlation Estimation (GCE) to generate feature correlation maps of local features and global features, which help to localize the high- and low-correlation regions for identifying the same person. After that, the discriminative features are disentangled into high-correlation features and low-correlation features under the guidance of the global representations. Moreover, a novel Temporal Reciprocal Learning (TRL) mechanism is designed to sequentially enhance the high-correlation semantic information and accumulate the low-correlation sub-critical clues. Extensive experiments are conducted on three public benchmarks. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches. The code is released at https://github.com/flysnowtiger/GRL.