 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Retrieval-based Dialogue System via Syntax-Informed Attention
Mar 12, 2023Multi-turn response selection is a challenging task due to its high demands on efficient extraction of the matching features from abundant information provided by context utterances. Since incorporating syntactic information like dependency structures into neural models can promote a better understanding of the sentences, such a method has been widely used in NLP tasks. Though syntactic information helps models achieved pleasing results, its application in retrieval-based dialogue systems has not been fully explored. Meanwhile, previous works focus on intra-sentence syntax alone, which is far from satisfactory for the task of multi-turn response where dialogues usually contain multiple sentences. To this end, we propose SIA, Syntax-Informed Attention, considering both intra- and inter-sentence syntax information. While the former restricts attention scope to only between tokens and corresponding dependents in the syntax tree, the latter allows attention in cross-utterance pairs for those syntactically important tokens. We evaluate our method on three widely used benchmarks and experimental results demonstrate the general superiority of our method on dialogue response selection.
ZeroNLG: Aligning and Autoencoding Domains for Zero-Shot Multimodal and Multilingual Natural Language Generation
Mar 11, 2023Natural Language Generation (NLG) accepts input data in the form of images, videos, or text and generates corresponding natural language text as output. Existing NLG methods mainly adopt a supervised approach and rely heavily on coupled data-to-text pairs. However, for many targeted scenarios and for non-English languages, sufficient quantities of labeled data are often not available. To relax the dependency on labeled data of downstream tasks, we propose an intuitive and effective zero-shot learning framework, ZeroNLG, which can deal with multiple NLG tasks, including image-to-text (image captioning), video-to-text (video captioning), and text-to-text (neural machine translation), across English, Chinese, German, and French within a unified framework. ZeroNLG does not require any labeled downstream pairs for training. During training, ZeroNLG (i) projects different domains (across modalities and languages) to corresponding coordinates in a shared common latent space; (ii) bridges different domains by aligning their corresponding coordinates in this space; and (iii) builds an unsupervised multilingual auto-encoder to learn to generate text by reconstructing the input text given its coordinate in shared latent space. Consequently, during inference, based on the data-to-text pipeline, ZeroNLG can generate target sentences across different languages given the coordinate of input data in the common space. Within this unified framework, given visual (imaging or video) data as input, ZeroNLG can perform zero-shot visual captioning; given textual sentences as input, ZeroNLG can perform zero-shot machine translation. We present the results of extensive experiments on twelve NLG tasks, showing that, without using any labeled downstream pairs for training, ZeroNLG generates high-quality and believable outputs and significantly outperforms existing zero-shot methods.
Improving Weakly Supervised Sound Event Detection with Causal Intervention
Mar 10, 2023Existing weakly supervised sound event detection (WSSED) work has not explored both types of co-occurrences simultaneously, i.e., some sound events often co-occur, and their occurrences are usually accompanied by specific background sounds, so they would be inevitably entangled, causing misclassification and biased localization results with only clip-level supervision. To tackle this issue, we first establish a structural causal model (SCM) to reveal that the context is the main cause of co-occurrence confounders that mislead the model to learn spurious correlations between frames and clip-level labels. Based on the causal analysis, we propose a causal intervention (CI) method for WSSED to remove the negative impact of co-occurrence confounders by iteratively accumulating every possible context of each class and then re-projecting the contexts to the frame-level features for making the event boundary clearer. Experiments show that our method effectively improves the performance on multiple datasets and can generalize to various baseline models.
SSVMR: Saliency-based Self-training for Video-Music Retrieval
Feb 18, 2023With the rise of short videos, the demand for selecting appropriate background music (BGM) for a video has increased significantly, video-music retrieval (VMR) task gradually draws much attention by research community. As other cross-modal learning tasks, existing VMR approaches usually attempt to measure the similarity between the video and music in the feature space. However, they (1) neglect the inevitable label noise; (2) neglect to enhance the ability to capture critical video clips. In this paper, we propose a novel saliency-based self-training framework, which is termed SSVMR. Specifically, we first explore to fully make use of the information containing in the training dataset by applying a semi-supervised method to suppress the adverse impact of label noise problem, where a self-training approach is adopted. In addition, we propose to capture the saliency of the video by mixing two videos at span level and preserving the locality of the two original videos. Inspired by back translation in NLP, we also conduct back retrieval to obtain more training data. Experimental results on MVD dataset show that our SSVMR achieves the state-of-the-art performance by a large margin, obtaining a relative improvement of 34.8% over the previous best model in terms of R@1.
Generating Templated Caption for Video Grounding
Jan 15, 2023Video grounding aims to locate a moment of interest matching the given query sentence from an untrimmed video. Previous works ignore the \emph{sparsity dilemma} in video annotations, which fails to provide the context information between potential events and query sentences in the dataset. In this paper, we contend that providing easily available captions which describe general actions \ie, templated captions defined in our paper, will significantly boost the performance. To this end, we propose a Templated Caption Network (TCNet) for video grounding. Specifically, we first introduce dense video captioning to generate dense captions, and then obtain templated captions by Non-Templated Caption Suppression (NTCS). To utilize templated captions better, we propose Caption Guided Attention (CGA) project the semantic relations between templated captions and query sentences into temporal space and fuse them into visual representations. Considering the gap between templated captions and ground truth, we propose Asymmetric Dual Matching Supervised Contrastive Learning (ADMSCL) for constructing more negative pairs to maximize cross-modal mutual information. Without bells and whistles, extensive experiments on three public datasets (\ie, ActivityNet Captions, TACoS and ActivityNet-CG) demonstrate that our method significantly outperforms state-of-the-art methods.
Towards Unified All-Neural Beamforming for Time and Frequency Domain Speech Separation
Dec 24, 2022Recently, frequency domain all-neural beamforming methods have achieved remarkable progress for multichannel speech separation. In parallel, the integration of time domain network structure and beamforming also gains significant attention. This study proposes a novel all-neural beamforming method in time domain and makes an attempt to unify the all-neural beamforming pipelines for time domain and frequency domain multichannel speech separation. The proposed model consists of two modules: separation and beamforming. Both modules perform temporal-spectral-spatial modeling and are trained from end-to-end using a joint loss function. The novelty of this study lies in two folds. Firstly, a time domain directional feature conditioned on the direction of the target speaker is proposed, which can be jointly optimized within the time domain architecture to enhance target signal estimation. Secondly, an all-neural beamforming network in time domain is designed to refine the pre-separated results. This module features with parametric time-variant beamforming coefficient estimation, without explicitly following the derivation of optimal filters that may lead to an upper bound. The proposed method is evaluated on simulated reverberant overlapped speech data derived from the AISHELL-1 corpus. Experimental results demonstrate significant performance improvements over frequency domain state-of-the-arts, ideal magnitude masks and existing time domain neural beamforming methods.
M3ST: Mix at Three Levels for Speech Translation
Dec 07, 2022How to solve the data scarcity problem for end-to-end speech-to-text translation (ST)? It's well known that data augmentation is an efficient method to improve performance for many tasks by enlarging the dataset. In this paper, we propose Mix at three levels for Speech Translation (M^3ST) method to increase the diversity of the augmented training corpus. Specifically, we conduct two phases of fine-tuning based on a pre-trained model using external machine translation (MT) data. In the first stage of fine-tuning, we mix the training corpus at three levels, including word level, sentence level and frame level, and fine-tune the entire model with mixed data. At the second stage of fine-tuning, we take both original speech sequences and original text sequences in parallel into the model to fine-tune the network, and use Jensen-Shannon divergence to regularize their outputs. Experiments on MuST-C speech translation benchmark and analysis show that M^3ST outperforms current strong baselines and achieves state-of-the-art results on eight directions with an average BLEU of 29.9.
Aligning Source Visual and Target Language Domains for Unpaired Video Captioning
Nov 22, 2022Training supervised video captioning model requires coupled video-caption pairs. However, for many targeted languages, sufficient paired data are not available. To this end, we introduce the unpaired video captioning task aiming to train models without coupled video-caption pairs in target language. To solve the task, a natural choice is to employ a two-step pipeline system: first utilizing video-to-pivot captioning model to generate captions in pivot language and then utilizing pivot-to-target translation model to translate the pivot captions to the target language. However, in such a pipeline system, 1) visual information cannot reach the translation model, generating visual irrelevant target captions; 2) the errors in the generated pivot captions will be propagated to the translation model, resulting in disfluent target captions. To address these problems, we propose the Unpaired Video Captioning with Visual Injection system (UVC-VI). UVC-VI first introduces the Visual Injection Module (VIM), which aligns source visual and target language domains to inject the source visual information into the target language domain. Meanwhile, VIM directly connects the encoder of the video-to-pivot model and the decoder of the pivot-to-target model, allowing end-to-end inference by completely skipping the generation of pivot captions. To enhance the cross-modality injection of the VIM, UVC-VI further introduces a pluggable video encoder, i.e., Multimodal Collaborative Encoder (MCE). The experiments show that UVC-VI outperforms pipeline systems and exceeds several supervised systems. Furthermore, equipping existing supervised systems with our MCE can achieve 4% and 7% relative margins on the CIDEr scores to current state-of-the-art models on the benchmark MSVD and MSR-VTT datasets, respectively.
A Dynamic Graph Interactive Framework with Label-Semantic Injection for Spoken Language Understanding
Nov 08, 2022Multi-intent detection and slot filling joint models are gaining increasing traction since they are closer to complicated real-world scenarios. However, existing approaches (1) focus on identifying implicit correlations between utterances and one-hot encoded labels in both tasks while ignoring explicit label characteristics; (2) directly incorporate multi-intent information for each token, which could lead to incorrect slot prediction due to the introduction of irrelevant intent. In this paper, we propose a framework termed DGIF, which first leverages the semantic information of labels to give the model additional signals and enriched priors. Then, a multi-grain interactive graph is constructed to model correlations between intents and slots. Specifically, we propose a novel approach to construct the interactive graph based on the injection of label semantics, which can automatically update the graph to better alleviate error propagation. Experimental results show that our framework significantly outperforms existing approaches, obtaining a relative improvement of 13.7% over the previous best model on the MixATIS dataset in overall accuracy.
NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
Nov 04, 2022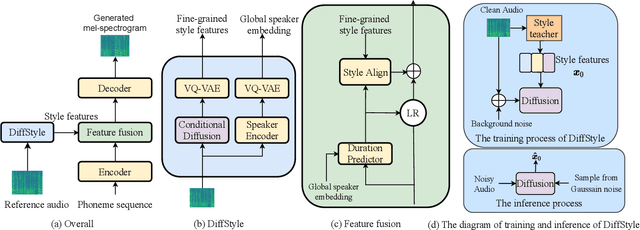
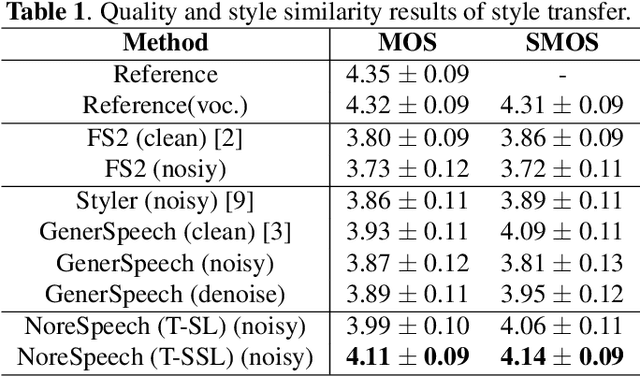

Expressive text-to-speech (TTS) can synthesize a new speaking style by imiating prosody and timbre from a reference audio, which faces the following challenges: (1) The highly dynamic prosody information in the reference audio is difficult to extract, especially, when the reference audio contains background noise. (2) The TTS systems should have good generalization for unseen speaking styles. In this paper, we present a \textbf{no}ise-\textbf{r}obust \textbf{e}xpressive TTS model (NoreSpeech), which can robustly transfer speaking style in a noisy reference utterance to synthesized speech. Specifically, our NoreSpeech includes several components: (1) a novel DiffStyle module, which leverages powerful probabilistic denoising diffusion models to learn noise-agnostic speaking style features from a teacher model by knowledge distillation; (2) a VQ-VAE block, which maps the style features into a controllable quantized latent space for improving the generalization of style transfer; and (3) a straight-forward but effective parameter-free text-style alignment module, which enables NoreSpeech to transfer style to a textual input from a length-mismatched reference utterance. Experiments demonstrate that NoreSpeech is more effective than previous expressive TTS models in noise environments. Audio samples and code are available at: \href{http://dongchaoyang.top/NoreSpeech\_demo/}{http://dongchaoyang.top/NoreSpeech\_demo/}