 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023



With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking
Feb 28, 2023



The robustness of deep neural networks is usually lacking under adversarial examples, common corruptions, and distribution shifts, which becomes an important research problem in the development of deep learning. Although new deep learning methods and robustness improvement techniques have been constantly proposed, the robustness evaluations of existing methods are often inadequate due to their rapid development, diverse noise patterns, and simple evaluation metrics. Without thorough robustness evaluations, it is hard to understand the advances in the field and identify the effective methods. In this paper, we establish a comprehensive robustness benchmark called \textbf{ARES-Bench} on the image classification task. In our benchmark, we evaluate the robustness of 55 typical deep learning models on ImageNet with diverse architectures (e.g., CNNs, Transformers) and learning algorithms (e.g., normal supervised training, pre-training, adversarial training) under numerous adversarial attacks and out-of-distribution (OOD) datasets. Using robustness curves as the major evaluation criteria, we conduct large-scale experiments and draw several important findings, including: 1) there is an inherent trade-off between adversarial and natural robustness for the same model architecture; 2) adversarial training effectively improves adversarial robustness, especially when performed on Transformer architectures; 3) pre-training significantly improves natural robustness based on more training data or self-supervised learning. Based on ARES-Bench, we further analyze the training tricks in large-scale adversarial training on ImageNet. By designing the training settings accordingly, we achieve the new state-of-the-art adversarial robustness. We have made the benchmarking results and code platform publicly available.
Rethinking Out-of-Distribution Detection From a Human-Centric Perspective
Nov 30, 2022



Out-Of-Distribution (OOD) detection has received broad attention over the years, aiming to ensure the reliability and safety of deep neural networks (DNNs) in real-world scenarios by rejecting incorrect predictions. However, we notice a discrepancy between the conventional evaluation vs. the essential purpose of OOD detection. On the one hand, the conventional evaluation exclusively considers risks caused by label-space distribution shifts while ignoring the risks from input-space distribution shifts. On the other hand, the conventional evaluation reward detection methods for not rejecting the misclassified image in the validation dataset. However, the misclassified image can also cause risks and should be rejected. We appeal to rethink OOD detection from a human-centric perspective, that a proper detection method should reject the case that the deep model's prediction mismatches the human expectations and adopt the case that the deep model's prediction meets the human expectations. We propose a human-centric evaluation and conduct extensive experiments on 45 classifiers and 8 test datasets. We find that the simple baseline OOD detection method can achieve comparable and even better performance than the recently proposed methods, which means that the development in OOD detection in the past years may be overestimated. Additionally, our experiments demonstrate that model selection is non-trivial for OOD detection and should be considered as an integral of the proposed method, which differs from the claim in existing works that proposed methods are universal across different models.
Context-Aware Robust Fine-Tuning
Nov 29, 2022Contrastive Language-Image Pre-trained (CLIP) models have zero-shot ability of classifying an image belonging to "[CLASS]" by using similarity between the image and the prompt sentence "a [CONTEXT] of [CLASS]". Based on exhaustive text cues in "[CONTEXT]", CLIP model is aware of different contexts, e.g. background, style, viewpoint, and exhibits unprecedented robustness against a wide range of distribution shifts. However, recent works find further fine-tuning of CLIP models improves accuracy but sacrifices the robustness on downstream tasks. We conduct an empirical investigation to show fine-tuning will corrupt the context-aware ability of pre-trained CLIP features. To solve this problem, we propose Context-Aware Robust Fine-tuning (CAR-FT). CAR-FT regularizes the model during fine-tuning to capture the context information. Specifically, we use zero-shot prompt weights to get the context distribution contained in the image. By minimizing the Kullback-Leibler Divergence (KLD) between context distributions induced by original/fine-tuned CLIP models, CAR-FT makes the context-aware ability of CLIP inherited into downstream tasks, and achieves both higher In-Distribution (ID) and Out-Of-Distribution (OOD) accuracy. The experimental results show CAR-FT achieves superior robustness on five OOD test datasets of ImageNet, and meanwhile brings accuracy gains on nine downstream tasks. Additionally, CAR-FT surpasses previous Domain Generalization (DG) methods and gets 78.5% averaged accuracy on DomainBed benchmark, building the new state-of-the-art.
Defects of Convolutional Decoder Networks in Frequency Representation
Oct 17, 2022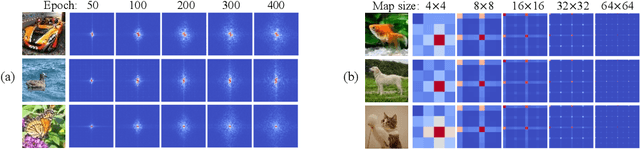
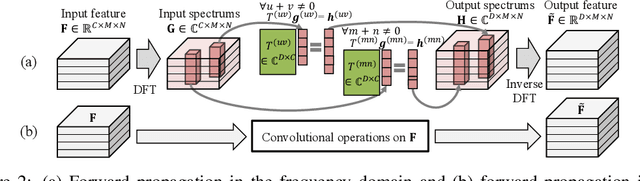


In this paper, we prove representation bottlenecks of a cascaded convolutional decoder network, considering the capacity of representing different frequency components of an input sample. We conduct the discrete Fourier transform on each channel of the feature map in an intermediate layer of the decoder network. Then, we introduce the rule of the forward propagation of such intermediate-layer spectrum maps, which is equivalent to the forward propagation of feature maps through a convolutional layer. Based on this, we find that each frequency component in the spectrum map is forward propagated independently with other frequency components. Furthermore, we prove two bottlenecks in representing feature spectrums. First, we prove that the convolution operation, the zero-padding operation, and a set of other settings all make a convolutional decoder network more likely to weaken high-frequency components. Second, we prove that the upsampling operation generates a feature spectrum, in which strong signals repetitively appears at certain frequencies.
Prompt-based Connective Prediction Method for Fine-grained Implicit Discourse Relation Recognition
Oct 16, 2022

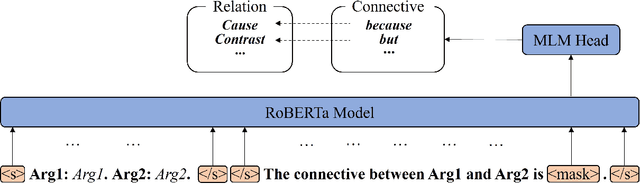
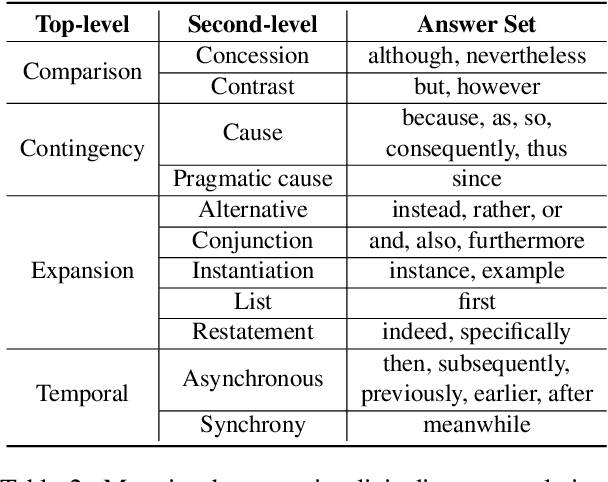
Due to the absence of connectives, implicit discourse relation recognition (IDRR) is still a challenging and crucial task in discourse analysis. Most of the current work adopted multi-task learning to aid IDRR through explicit discourse relation recognition (EDRR) or utilized dependencies between discourse relation labels to constrain model predictions. But these methods still performed poorly on fine-grained IDRR and even utterly misidentified on most of the few-shot discourse relation classes. To address these problems, we propose a novel Prompt-based Connective Prediction (PCP) method for IDRR. Our method instructs large-scale pre-trained models to use knowledge relevant to discourse relation and utilizes the strong correlation between connectives and discourse relation to help the model recognize implicit discourse relations. Experimental results show that our method surpasses the current state-of-the-art model and achieves significant improvements on those fine-grained few-shot discourse relation. Moreover, our approach is able to be transferred to EDRR and obtain acceptable results. Our code is released in https://github.com/zh-i9/PCP-for-IDRR.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
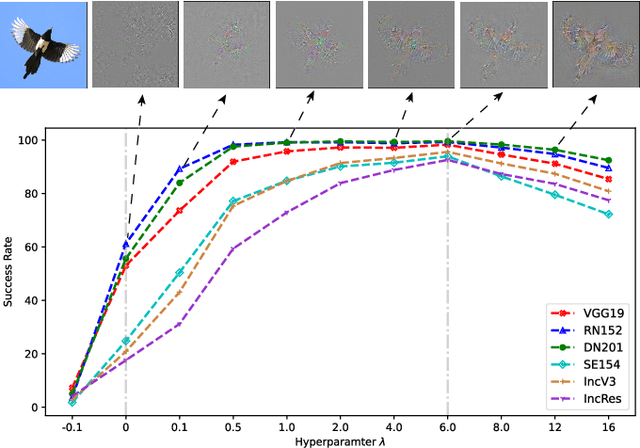
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
MaxMatch: Semi-Supervised Learning with Worst-Case Consistency
Sep 26, 2022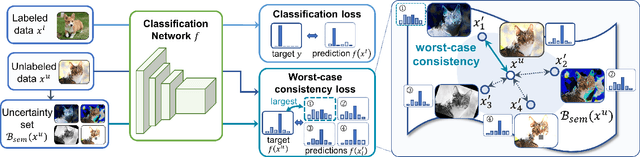
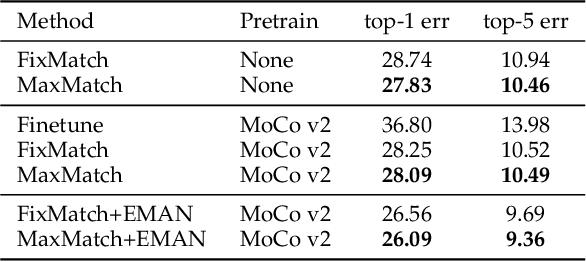

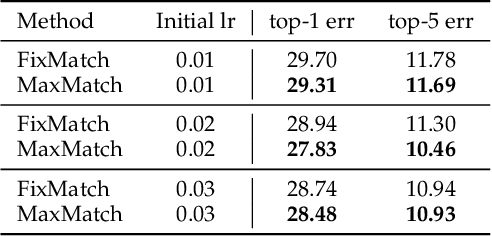
In recent years, great progress has been made to incorporate unlabeled data to overcome the inefficiently supervised problem via semi-supervised learning (SSL). Most state-of-the-art models are based on the idea of pursuing consistent model predictions over unlabeled data toward the input noise, which is called consistency regularization. Nonetheless, there is a lack of theoretical insights into the reason behind its success. To bridge the gap between theoretical and practical results, we propose a worst-case consistency regularization technique for SSL in this paper. Specifically, we first present a generalization bound for SSL consisting of the empirical loss terms observed on labeled and unlabeled training data separately. Motivated by this bound, we derive an SSL objective that minimizes the largest inconsistency between an original unlabeled sample and its multiple augmented variants. We then provide a simple but effective algorithm to solve the proposed minimax problem, and theoretically prove that it converges to a stationary point. Experiments on five popular benchmark datasets validate the effectiveness of our proposed method.
Enhance the Visual Representation via Discrete Adversarial Training
Sep 16, 2022



Adversarial Training (AT), which is commonly accepted as one of the most effective approaches defending against adversarial examples, can largely harm the standard performance, thus has limited usefulness on industrial-scale production and applications. Surprisingly, this phenomenon is totally opposite in Natural Language Processing (NLP) task, where AT can even benefit for generalization. We notice the merit of AT in NLP tasks could derive from the discrete and symbolic input space. For borrowing the advantage from NLP-style AT, we propose Discrete Adversarial Training (DAT). DAT leverages VQGAN to reform the image data to discrete text-like inputs, i.e. visual words. Then it minimizes the maximal risk on such discrete images with symbolic adversarial perturbations. We further give an explanation from the perspective of distribution to demonstrate the effectiveness of DAT. As a plug-and-play technique for enhancing the visual representation, DAT achieves significant improvement on multiple tasks including image classification, object detection and self-supervised learning. Especially, the model pre-trained with Masked Auto-Encoding (MAE) and fine-tuned by our DAT without extra data can get 31.40 mCE on ImageNet-C and 32.77% top-1 accuracy on Stylized-ImageNet, building the new state-of-the-art. The code will be available at https://github.com/alibaba/easyrobust.
D^2ETR: Decoder-Only DETR with Computationally Efficient Cross-Scale Attention
Mar 02, 2022
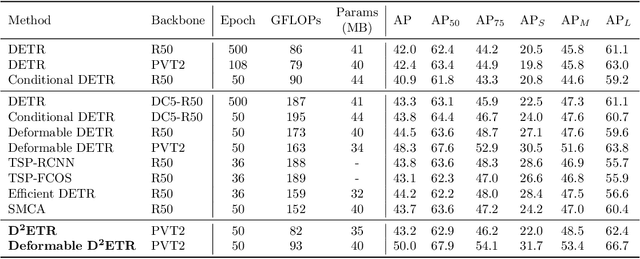
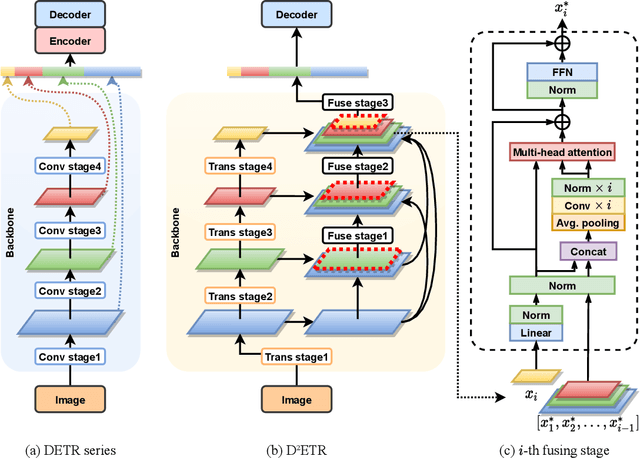
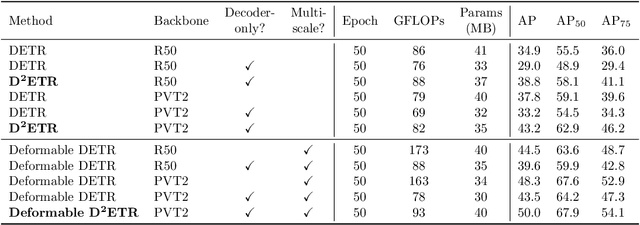
DETR is the first fully end-to-end detector that predicts a final set of predictions without post-processing. However, it suffers from problems such as low performance and slow convergence. A series of works aim to tackle these issues in different ways, but the computational cost is yet expensive due to the sophisticated encoder-decoder architecture. To alleviate this issue, we propose a decoder-only detector called D^2ETR. In the absence of encoder, the decoder directly attends to the fine-fused feature maps generated by the Transformer backbone with a novel computationally efficient cross-scale attention module. D^2ETR demonstrates low computational complexity and high detection accuracy in evaluations on the COCO benchmark, outperforming DETR and its variants.