 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization then Neutralization: Gradient-guided Token Suppression against Visual Prompt Injection Attack
May 24, 2026Adversarial images pose a severe security threat to multimodal large language models through prompt injection. Existing defenses largely lack a principled understanding of the underlying mechanisms and struggle to balance efficiency and defense utility. In this work, we show that successful adversarial attacks do not rely on the entire image uniformly but instead depend on a small subset of critical image tokens. Based on this insight, we propose Gradient Token Masking (GTM), which localizes these tokens via gradient analysis and neutralizes them through masking. We find that attribution based on the first generated token's output probability fails when attacks preserve the predicted token. To overcome this, GTM utilizes the Hidden-State Gradient Norm score for generation-influence attribution under adversarial inputs. We prove that its ranking is consistent with that of the full adversarial loss gradient, providing a theoretical guarantee for accurate localization. Our method requires only a single forward-backward pass to identify and zero out a small number of high-scoring tokens, effectively disrupting the adversarial attack path. Extensive experiments on prompt injection and multimodal jailbreak attacks demonstrate that our approach reduces attack success rates (ASR) to near zero while preserving model utility with negligible computational overhead.
Enhancing Sample Utilization in Noise-Robust Deep Metric Learning With Subgroup-Based Positive-Pair Selection
Jan 19, 2025



The existence of noisy labels in real-world data negatively impacts the performance of deep learning models. Although much research effort has been devoted to improving the robustness towards noisy labels in classification tasks, the problem of noisy labels in deep metric learning (DML) remains under-explored. Existing noisy label learning methods designed for DML mainly discard suspicious noisy samples, resulting in a waste of the training data. To address this issue, we propose a noise-robust DML framework with SubGroup-based Positive-pair Selection (SGPS), which constructs reliable positive pairs for noisy samples to enhance the sample utilization. Specifically, SGPS first effectively identifies clean and noisy samples by a probability-based clean sample selectionstrategy. To further utilize the remaining noisy samples, we discover their potential similar samples based on the subgroup information given by a subgroup generation module and then aggregate them into informative positive prototypes for each noisy sample via a positive prototype generation module. Afterward, a new contrastive loss is tailored for the noisy samples with their selected positive pairs. SGPS can be easily integrated into the training process of existing pair-wise DML tasks, like image retrieval and face recognition. Extensive experiments on multiple synthetic and real-world large-scale label noise datasets demonstrate the effectiveness of our proposed method. Without any bells and whistles, our SGPS framework outperforms the state-of-the-art noisy label DML methods. Code is available at \url{https://github.com/smuelpeng/SGPS-NoiseFreeDML}.
* arXiv admin note: substantial text overlap with arXiv:2108.01431, arXiv:2103.16047 by other authors
AUCSeg: AUC-oriented Pixel-level Long-tail Semantic Segmentation
Sep 30, 2024



The Area Under the ROC Curve (AUC) is a well-known metric for evaluating instance-level long-tail learning problems. In the past two decades, many AUC optimization methods have been proposed to improve model performance under long-tail distributions. In this paper, we explore AUC optimization methods in the context of pixel-level long-tail semantic segmentation, a much more complicated scenario. This task introduces two major challenges for AUC optimization techniques. On one hand, AUC optimization in a pixel-level task involves complex coupling across loss terms, with structured inner-image and pairwise inter-image dependencies, complicating theoretical analysis. On the other hand, we find that mini-batch estimation of AUC loss in this case requires a larger batch size, resulting in an unaffordable space complexity. To address these issues, we develop a pixel-level AUC loss function and conduct a dependency-graph-based theoretical analysis of the algorithm's generalization ability. Additionally, we design a Tail-Classes Memory Bank (T-Memory Bank) to manage the significant memory demand. Finally, comprehensive experiments across various benchmarks confirm the effectiveness of our proposed AUCSeg method. The code is available at https://github.com/boyuh/AUCSeg.
Regularized Contrastive Partial Multi-view Outlier Detection
Aug 02, 2024



In recent years, multi-view outlier detection (MVOD) methods have advanced significantly, aiming to identify outliers within multi-view datasets. A key point is to better detect class outliers and class-attribute outliers, which only exist in multi-view data. However, existing methods either is not able to reduce the impact of outliers when learning view-consistent information, or struggle in cases with varying neighborhood structures. Moreover, most of them do not apply to partial multi-view data in real-world scenarios. To overcome these drawbacks, we propose a novel method named Regularized Contrastive Partial Multi-view Outlier Detection (RCPMOD). In this framework, we utilize contrastive learning to learn view-consistent information and distinguish outliers by the degree of consistency. Specifically, we propose (1) An outlier-aware contrastive loss with a potential outlier memory bank to eliminate their bias motivated by a theoretical analysis. (2) A neighbor alignment contrastive loss to capture the view-shared local structural correlation. (3) A spreading regularization loss to prevent the model from overfitting over outliers. With the Cross-view Relation Transfer technique, we could easily impute the missing view samples based on the features of neighbors. Experimental results on four benchmark datasets demonstrate that our proposed approach could outperform state-of-the-art competitors under different settings.
HGOE: Hybrid External and Internal Graph Outlier Exposure for Graph Out-of-Distribution Detection
Jul 31, 2024With the progressive advancements in deep graph learning, out-of-distribution (OOD) detection for graph data has emerged as a critical challenge. While the efficacy of auxiliary datasets in enhancing OOD detection has been extensively studied for image and text data, such approaches have not yet been explored for graph data. Unlike Euclidean data, graph data exhibits greater diversity but lower robustness to perturbations, complicating the integration of outliers. To tackle these challenges, we propose the introduction of \textbf{H}ybrid External and Internal \textbf{G}raph \textbf{O}utlier \textbf{E}xposure (HGOE) to improve graph OOD detection performance. Our framework involves using realistic external graph data from various domains and synthesizing internal outliers within ID subgroups to address the poor robustness and presence of OOD samples within the ID class. Furthermore, we develop a boundary-aware OE loss that adaptively assigns weights to outliers, maximizing the use of high-quality OOD samples while minimizing the impact of low-quality ones. Our proposed HGOE framework is model-agnostic and designed to enhance the effectiveness of existing graph OOD detection models. Experimental results demonstrate that our HGOE framework can significantly improve the performance of existing OOD detection models across all 8 real datasets.
ADA-GAD: Anomaly-Denoised Autoencoders for Graph Anomaly Detection
Dec 22, 2023



Graph anomaly detection is crucial for identifying nodes that deviate from regular behavior within graphs, benefiting various domains such as fraud detection and social network. Although existing reconstruction-based methods have achieved considerable success, they may face the \textit{Anomaly Overfitting} and \textit{Homophily Trap} problems caused by the abnormal patterns in the graph, breaking the assumption that normal nodes are often better reconstructed than abnormal ones. Our observations indicate that models trained on graphs with fewer anomalies exhibit higher detection performance. Based on this insight, we introduce a novel two-stage framework called Anomaly-Denoised Autoencoders for Graph Anomaly Detection (ADA-GAD). In the first stage, we design a learning-free anomaly-denoised augmentation method to generate graphs with reduced anomaly levels. We pretrain graph autoencoders on these augmented graphs at multiple levels, which enables the graph autoencoders to capture normal patterns. In the next stage, the decoders are retrained for detection on the original graph, benefiting from the multi-level representations learned in the previous stage. Meanwhile, we propose the node anomaly distribution regularization to further alleviate \textit{Anomaly Overfitting}. We validate the effectiveness of our approach through extensive experiments on both synthetic and real-world datasets.
* Accepted to AAAI-2024
Dist-PU: Positive-Unlabeled Learning from a Label Distribution Perspective
Dec 06, 2022

Positive-Unlabeled (PU) learning tries to learn binary classifiers from a few labeled positive examples with many unlabeled ones. Compared with ordinary semi-supervised learning, this task is much more challenging due to the absence of any known negative labels. While existing cost-sensitive-based methods have achieved state-of-the-art performances, they explicitly minimize the risk of classifying unlabeled data as negative samples, which might result in a negative-prediction preference of the classifier. To alleviate this issue, we resort to a label distribution perspective for PU learning in this paper. Noticing that the label distribution of unlabeled data is fixed when the class prior is known, it can be naturally used as learning supervision for the model. Motivated by this, we propose to pursue the label distribution consistency between predicted and ground-truth label distributions, which is formulated by aligning their expectations. Moreover, we further adopt the entropy minimization and Mixup regularization to avoid the trivial solution of the label distribution consistency on unlabeled data and mitigate the consequent confirmation bias. Experiments on three benchmark datasets validate the effectiveness of the proposed method.Code available at: https://github.com/Ray-rui/Dist-PU-Positive-Unlabeled-Learning-from-a-Label-Distribution-Perspective.
MaxMatch: Semi-Supervised Learning with Worst-Case Consistency
Sep 26, 2022
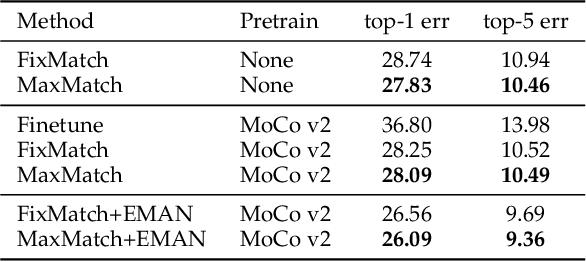

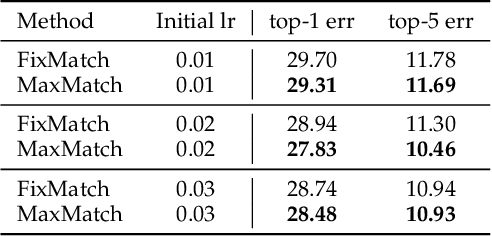
In recent years, great progress has been made to incorporate unlabeled data to overcome the inefficiently supervised problem via semi-supervised learning (SSL). Most state-of-the-art models are based on the idea of pursuing consistent model predictions over unlabeled data toward the input noise, which is called consistency regularization. Nonetheless, there is a lack of theoretical insights into the reason behind its success. To bridge the gap between theoretical and practical results, we propose a worst-case consistency regularization technique for SSL in this paper. Specifically, we first present a generalization bound for SSL consisting of the empirical loss terms observed on labeled and unlabeled training data separately. Motivated by this bound, we derive an SSL objective that minimizes the largest inconsistency between an original unlabeled sample and its multiple augmented variants. We then provide a simple but effective algorithm to solve the proposed minimax problem, and theoretically prove that it converges to a stationary point. Experiments on five popular benchmark datasets validate the effectiveness of our proposed method.
Seeking the Shape of Sound: An Adaptive Framework for Learning Voice-Face Association
Mar 12, 2021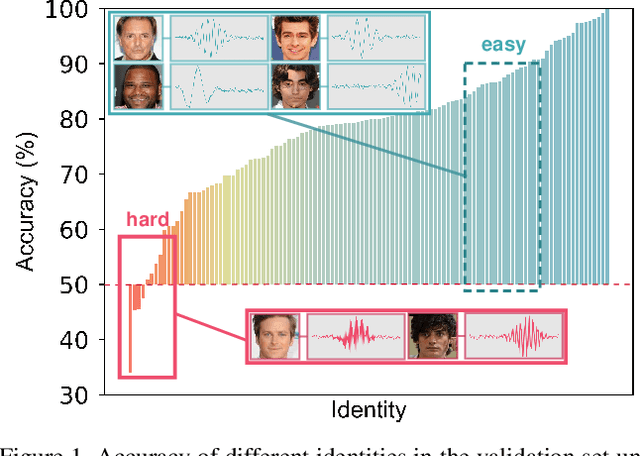
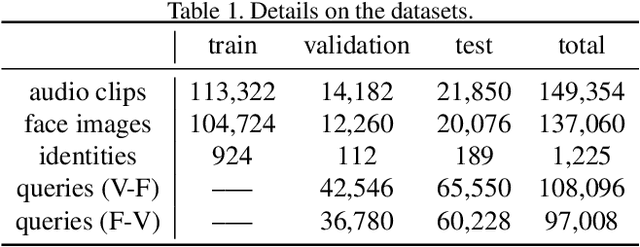
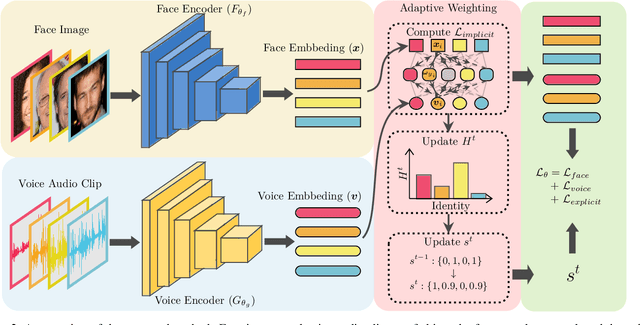
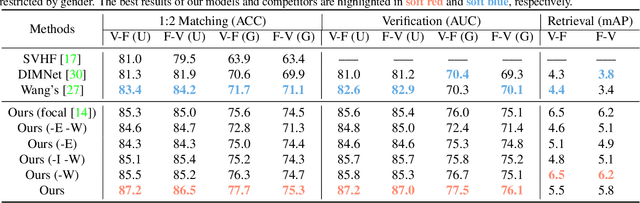
Nowadays, we have witnessed the early progress on learning the association between voice and face automatically, which brings a new wave of studies to the computer vision community. However, most of the prior arts along this line (a) merely adopt local information to perform modality alignment and (b) ignore the diversity of learning difficulty across different subjects. In this paper, we propose a novel framework to jointly address the above-mentioned issues. Targeting at (a), we propose a two-level modality alignment loss where both global and local information are considered. Compared with the existing methods, we introduce a global loss into the modality alignment process. The global component of the loss is driven by the identity classification. Theoretically, we show that minimizing the loss could maximize the distance between embeddings across different identities while minimizing the distance between embeddings belonging to the same identity, in a global sense (instead of a mini-batch). Targeting at (b), we propose a dynamic reweighting scheme to better explore the hard but valuable identities while filtering out the unlearnable identities. Experiments show that the proposed method outperforms the previous methods in multiple settings, including voice-face matching, verification and retrieval.
Deep Robust Subjective Visual Property Prediction in Crowdsourcing
Mar 10, 2019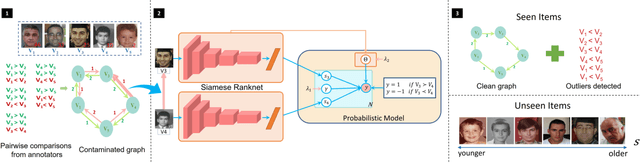
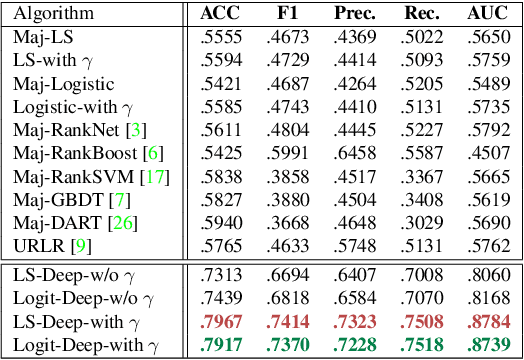

The problem of estimating subjective visual properties (SVP) of images (e.g., Shoes A is more comfortable than B) is gaining rising attention. Due to its highly subjective nature, different annotators often exhibit different interpretations of scales when adopting absolute value tests. Therefore, recent investigations turn to collect pairwise comparisons via crowdsourcing platforms. However, crowdsourcing data usually contains outliers. For this purpose, it is desired to develop a robust model for learning SVP from crowdsourced noisy annotations. In this paper, we construct a deep SVP prediction model which not only leads to better detection of annotation outliers but also enables learning with extremely sparse annotations. Specifically, we construct a comparison multi-graph based on the collected annotations, where different labeling results correspond to edges with different directions between two vertexes. Then, we propose a generalized deep probabilistic framework which consists of an SVP prediction module and an outlier modeling module that work collaboratively and are optimized jointly. Extensive experiments on various benchmark datasets demonstrate that our new approach guarantees promising results.