 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearFit+: Personalized Fitness Monitoring via Audio Signals on Smart Speakers
Mar 30, 2025



Fitness can help to strengthen muscles, increase resistance to diseases, and improve body shape. Nowadays, a great number of people choose to exercise at home/office rather than at the gym due to lack of time. However, it is difficult for them to get good fitness effects without professional guidance. Motivated by this, we propose the first personalized fitness monitoring system, HearFit+, using smart speakers at home/office. We explore the feasibility of using acoustic sensing to monitor fitness. We design a fitness detection method based on Doppler shift and adopt the short time energy to segment fitness actions. Based on deep learning, HearFit+ can perform fitness classification and user identification at the same time. Combined with incremental learning, users can easily add new actions. We design 4 evaluation metrics (i.e., duration, intensity, continuity, and smoothness) to help users to improve fitness effects. Through extensive experiments including over 9,000 actions of 10 types of fitness from 12 volunteers, HearFit+ can achieve an average accuracy of 96.13% on fitness classification and 91% accuracy for user identification. All volunteers confirm that HearFit+ can help improve the fitness effect in various environments.
HearSmoking: Smoking Detection in Driving Environment via Acoustic Sensing on Smartphones
Mar 30, 2025



Driving safety has drawn much public attention in recent years due to the fast-growing number of cars. Smoking is one of the threats to driving safety but is often ignored by drivers. Existing works on smoking detection either work in contact manner or need additional devices. This motivates us to explore the practicability of using smartphones to detect smoking events in driving environment. In this paper, we propose a cigarette smoking detection system, named HearSmoking, which only uses acoustic sensors on smartphones to improve driving safety. After investigating typical smoking habits of drivers, including hand movement and chest fluctuation, we design an acoustic signal to be emitted by the speaker and received by the microphone. We calculate Relative Correlation Coefficient of received signals to obtain movement patterns of hands and chest. The processed data is sent into a trained Convolutional Neural Network for classification of hand movement. We also design a method to detect respiration at the same time. To improve system performance, we further analyse the periodicity of the composite smoking motion. Through extensive experiments in real driving environments, HearSmoking detects smoking events with an average total accuracy of 93.44 percent in real-time.
Temporal Consistency for LLM Reasoning Process Error Identification
Mar 18, 2025



Verification is crucial for effective mathematical reasoning. We present a new temporal consistency method where verifiers iteratively refine their judgments based on the previous assessment. Unlike one-round verification or multi-model debate approaches, our method leverages consistency in a sequence of self-reflection actions to improve verification accuracy. Empirical evaluations across diverse mathematical process error identification benchmarks (Mathcheck, ProcessBench, and PRM800K) show consistent performance improvements over baseline methods. When applied to the recent DeepSeek R1 distilled models, our method demonstrates strong performance, enabling 7B/8B distilled models to outperform all 70B/72B models and GPT-4o on ProcessBench. Notably, the distilled 14B model with our method achieves performance comparable to Deepseek-R1. Our codes are available at https://github.com/jcguo123/Temporal-Consistency
DeepSeek-R1 Outperforms Gemini 2.0 Pro, OpenAI o1, and o3-mini in Bilingual Complex Ophthalmology Reasoning
Feb 25, 2025Purpose: To evaluate the accuracy and reasoning ability of DeepSeek-R1 and three other recently released large language models (LLMs) in bilingual complex ophthalmology cases. Methods: A total of 130 multiple-choice questions (MCQs) related to diagnosis (n = 39) and management (n = 91) were collected from the Chinese ophthalmology senior professional title examination and categorized into six topics. These MCQs were translated into English using DeepSeek-R1. The responses of DeepSeek-R1, Gemini 2.0 Pro, OpenAI o1 and o3-mini were generated under default configurations between February 15 and February 20, 2025. Accuracy was calculated as the proportion of correctly answered questions, with omissions and extra answers considered incorrect. Reasoning ability was evaluated through analyzing reasoning logic and the causes of reasoning error. Results: DeepSeek-R1 demonstrated the highest overall accuracy, achieving 0.862 in Chinese MCQs and 0.808 in English MCQs. Gemini 2.0 Pro, OpenAI o1, and OpenAI o3-mini attained accuracies of 0.715, 0.685, and 0.692 in Chinese MCQs (all P<0.001 compared with DeepSeek-R1), and 0.746 (P=0.115), 0.723 (P=0.027), and 0.577 (P<0.001) in English MCQs, respectively. DeepSeek-R1 achieved the highest accuracy across five topics in both Chinese and English MCQs. It also excelled in management questions conducted in Chinese (all P<0.05). Reasoning ability analysis showed that the four LLMs shared similar reasoning logic. Ignoring key positive history, ignoring key positive signs, misinterpretation medical data, and too aggressive were the most common causes of reasoning errors. Conclusion: DeepSeek-R1 demonstrated superior performance in bilingual complex ophthalmology reasoning tasks than three other state-of-the-art LLMs. While its clinical applicability remains challenging, it shows promise for supporting diagnosis and clinical decision-making.
Instance-Dependent Regret Bounds for Learning Two-Player Zero-Sum Games with Bandit Feedback
Feb 24, 2025

No-regret self-play learning dynamics have become one of the premier ways to solve large-scale games in practice. Accelerating their convergence via improving the regret of the players over the naive $O(\sqrt{T})$ bound after $T$ rounds has been extensively studied in recent years, but almost all studies assume access to exact gradient feedback. We address the question of whether acceleration is possible under bandit feedback only and provide an affirmative answer for two-player zero-sum normal-form games. Specifically, we show that if both players apply the Tsallis-INF algorithm of Zimmert and Seldin (2018, arXiv:1807.07623), then their regret is at most $O(c_1 \log T + \sqrt{c_2 T})$, where $c_1$ and $c_2$ are game-dependent constants that characterize the difficulty of learning -- $c_1$ resembles the complexity of learning a stochastic multi-armed bandit instance and depends inversely on some gap measures, while $c_2$ can be much smaller than the number of actions when the Nash equilibria have a small support or are close to the boundary. In particular, for the case when a pure strategy Nash equilibrium exists, $c_2$ becomes zero, leading to an optimal instance-dependent regret bound as we show. We additionally prove that in this case, our algorithm also enjoys last-iterate convergence and can identify the pure strategy Nash equilibrium with near-optimal sample complexity.
Fundus2Globe: Generative AI-Driven 3D Digital Twins for Personalized Myopia Management
Feb 18, 2025



Myopia, projected to affect 50% population globally by 2050, is a leading cause of vision loss. Eyes with pathological myopia exhibit distinctive shape distributions, which are closely linked to the progression of vision-threatening complications. Recent understanding of eye-shape-based biomarkers requires magnetic resonance imaging (MRI), however, it is costly and unrealistic in routine ophthalmology clinics. We present Fundus2Globe, the first AI framework that synthesizes patient-specific 3D eye globes from ubiquitous 2D color fundus photographs (CFPs) and routine metadata (axial length, spherical equivalent), bypassing MRI dependency. By integrating a 3D morphable eye model (encoding biomechanical shape priors) with a latent diffusion model, our approach achieves submillimeter accuracy in reconstructing posterior ocular anatomy efficiently. Fundus2Globe uniquely quantifies how vision-threatening lesions (e.g., staphylomas) in CFPs correlate with MRI-validated 3D shape abnormalities, enabling clinicians to simulate posterior segment changes in response to refractive shifts. External validation demonstrates its robust generation performance, ensuring fairness across underrepresented groups. By transforming 2D fundus imaging into 3D digital replicas of ocular structures, Fundus2Globe is a gateway for precision ophthalmology, laying the foundation for AI-driven, personalized myopia management.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
Self-Regulation and Requesting Interventions
Feb 07, 2025



Human intelligence involves metacognitive abilities like self-regulation, recognizing limitations, and seeking assistance only when needed. While LLM Agents excel in many domains, they often lack this awareness. Overconfident agents risk catastrophic failures, while those that seek help excessively hinder efficiency. A key challenge is enabling agents with a limited intervention budget $C$ is to decide when to request assistance. In this paper, we propose an offline framework that trains a "helper" policy to request interventions, such as more powerful models or test-time compute, by combining LLM-based process reward models (PRMs) with tabular reinforcement learning. Using state transitions collected offline, we score optimal intervention timing with PRMs and train the helper model on these labeled trajectories. This offline approach significantly reduces costly intervention calls during training. Furthermore, the integration of PRMs with tabular RL enhances robustness to off-policy data while avoiding the inefficiencies of deep RL. We empirically find that our method delivers optimal helper behavior.
Phi-4 Technical Report
Dec 12, 2024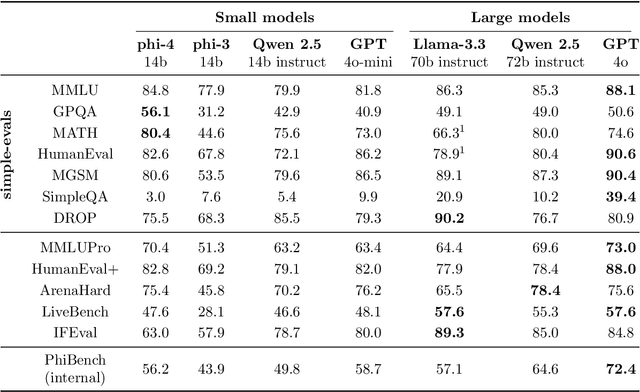
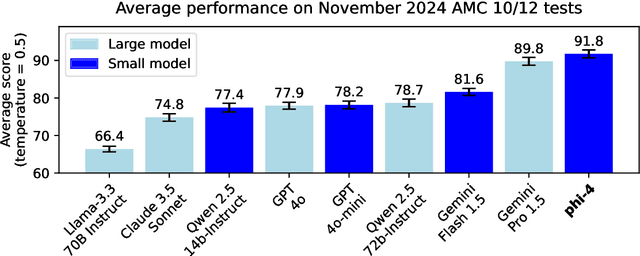

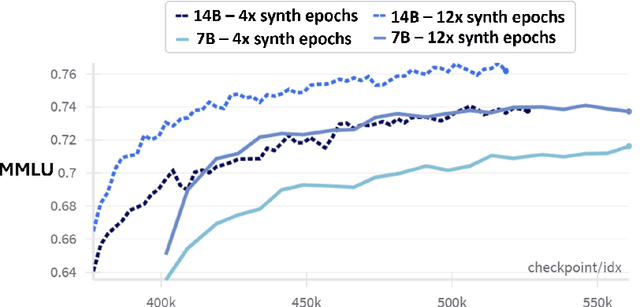
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
NODE-AdvGAN: Improving the transferability and perceptual similarity of adversarial examples by dynamic-system-driven adversarial generative model
Dec 04, 2024



Understanding adversarial examples is crucial for improving the model's robustness, as they introduce imperceptible perturbations that deceive models. Effective adversarial examples, therefore, offer the potential to train more robust models by removing their singularities. We propose NODE-AdvGAN, a novel approach that treats adversarial generation as a continuous process and employs a Neural Ordinary Differential Equation (NODE) for simulating the dynamics of the generator. By mimicking the iterative nature of traditional gradient-based methods, NODE-AdvGAN generates smoother and more precise perturbations that preserve high perceptual similarity when added to benign images. We also propose a new training strategy, NODE-AdvGAN-T, which enhances transferability in black-box attacks by effectively tuning noise parameters during training. Experiments demonstrate that NODE-AdvGAN and NODE-AdvGAN-T generate more effective adversarial examples that achieve higher attack success rates while preserving better perceptual quality than traditional GAN-based methods.