 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan, Eliminate, and Track -- Language Models are Good Teachers for Embodied Agents
May 07, 2023Pre-trained large language models (LLMs) capture procedural knowledge about the world. Recent work has leveraged LLM's ability to generate abstract plans to simplify challenging control tasks, either by action scoring, or action modeling (fine-tuning). However, the transformer architecture inherits several constraints that make it difficult for the LLM to directly serve as the agent: e.g. limited input lengths, fine-tuning inefficiency, bias from pre-training, and incompatibility with non-text environments. To maintain compatibility with a low-level trainable actor, we propose to instead use the knowledge in LLMs to simplify the control problem, rather than solving it. We propose the Plan, Eliminate, and Track (PET) framework. The Plan module translates a task description into a list of high-level sub-tasks. The Eliminate module masks out irrelevant objects and receptacles from the observation for the current sub-task. Finally, the Track module determines whether the agent has accomplished each sub-task. On the AlfWorld instruction following benchmark, the PET framework leads to a significant 15% improvement over SOTA for generalization to human goal specifications.
Weighted Tallying Bandits: Overcoming Intractability via Repeated Exposure Optimality
May 04, 2023



In recommender system or crowdsourcing applications of online learning, a human's preferences or abilities are often a function of the algorithm's recent actions. Motivated by this, a significant line of work has formalized settings where an action's loss is a function of the number of times that action was recently played in the prior $m$ timesteps, where $m$ corresponds to a bound on human memory capacity. To more faithfully capture decay of human memory with time, we introduce the Weighted Tallying Bandit (WTB), which generalizes this setting by requiring that an action's loss is a function of a \emph{weighted} summation of the number of times that arm was played in the last $m$ timesteps. This WTB setting is intractable without further assumption. So we study it under Repeated Exposure Optimality (REO), a condition motivated by the literature on human physiology, which requires the existence of an action that when repetitively played will eventually yield smaller loss than any other sequence of actions. We study the minimization of the complete policy regret (CPR), which is the strongest notion of regret, in WTB under REO. Since $m$ is typically unknown, we assume we only have access to an upper bound $M$ on $m$. We show that for problems with $K$ actions and horizon $T$, a simple modification of the successive elimination algorithm has $O \left( \sqrt{KT} + (m+M)K \right)$ CPR. Interestingly, upto an additive (in lieu of mutliplicative) factor in $(m+M)K$, this recovers the classical guarantee for the simpler stochastic multi-armed bandit with traditional regret. We additionally show that in our setting, any algorithm will suffer additive CPR of $\Omega \left( mK + M \right)$, demonstrating our result is nearly optimal. Our algorithm is computationally efficient, and we experimentally demonstrate its practicality and superiority over natural baselines.
On the Importance of Contrastive Loss in Multimodal Learning
Apr 07, 2023

Recently, contrastive learning approaches (e.g., CLIP (Radford et al., 2021)) have received huge success in multimodal learning, where the model tries to minimize the distance between the representations of different views (e.g., image and its caption) of the same data point while keeping the representations of different data points away from each other. However, from a theoretical perspective, it is unclear how contrastive learning can learn the representations from different views efficiently, especially when the data is not isotropic. In this work, we analyze the training dynamics of a simple multimodal contrastive learning model and show that contrastive pairs are important for the model to efficiently balance the learned representations. In particular, we show that the positive pairs will drive the model to align the representations at the cost of increasing the condition number, while the negative pairs will reduce the condition number, keeping the learned representations balanced.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023



Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
The Benefits of Mixup for Feature Learning
Mar 15, 2023Mixup, a simple data augmentation method that randomly mixes two data points via linear interpolation, has been extensively applied in various deep learning applications to gain better generalization. However, the theoretical underpinnings of its efficacy are not yet fully understood. In this paper, we aim to seek a fundamental understanding of the benefits of Mixup. We first show that Mixup using different linear interpolation parameters for features and labels can still achieve similar performance to the standard Mixup. This indicates that the intuitive linearity explanation in Zhang et al., (2018) may not fully explain the success of Mixup. Then we perform a theoretical study of Mixup from the feature learning perspective. We consider a feature-noise data model and show that Mixup training can effectively learn the rare features (appearing in a small fraction of data) from its mixture with the common features (appearing in a large fraction of data). In contrast, standard training can only learn the common features but fails to learn the rare features, thus suffering from bad generalization performance. Moreover, our theoretical analysis also shows that the benefits of Mixup for feature learning are mostly gained in the early training phase, based on which we propose to apply early stopping in Mixup. Experimental results verify our theoretical findings and demonstrate the effectiveness of the early-stopped Mixup training.
How Do Transformers Learn Topic Structure: Towards a Mechanistic Understanding
Mar 07, 2023While the successes of transformers across many domains are indisputable, accurate understanding of the learning mechanics is still largely lacking. Their capabilities have been probed on benchmarks which include a variety of structured and reasoning tasks -- but mathematical understanding is lagging substantially behind. Recent lines of work have begun studying representational aspects of this question: that is, the size/depth/complexity of attention-based networks to perform certain tasks. However, there is no guarantee the learning dynamics will converge to the constructions proposed. In our paper, we provide fine-grained mechanistic understanding of how transformers learn "semantic structure", understood as capturing co-occurrence structure of words. Precisely, we show, through a combination of experiments on synthetic data modeled by Latent Dirichlet Allocation (LDA), Wikipedia data, and mathematical analysis that the embedding layer and the self-attention layer encode the topical structure. In the former case, this manifests as higher average inner product of embeddings between same-topic words. In the latter, it manifests as higher average pairwise attention between same-topic words. The mathematical results involve several assumptions to make the analysis tractable, which we verify on data, and might be of independent interest as well.
Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals
Feb 12, 2023High sample complexity has long been a challenge for RL. On the other hand, humans learn to perform tasks not only from interaction or demonstrations, but also by reading unstructured text documents, e.g., instruction manuals. Instruction manuals and wiki pages are among the most abundant data that could inform agents of valuable features and policies or task-specific environmental dynamics and reward structures. Therefore, we hypothesize that the ability to utilize human-written instruction manuals to assist learning policies for specific tasks should lead to a more efficient and better-performing agent. We propose the Read and Reward framework. Read and Reward speeds up RL algorithms on Atari games by reading manuals released by the Atari game developers. Our framework consists of a QA Extraction module that extracts and summarizes relevant information from the manual and a Reasoning module that evaluates object-agent interactions based on information from the manual. Auxiliary reward is then provided to a standard A2C RL agent, when interaction is detected. When assisted by our design, A2C improves on 4 games in the Atari environment with sparse rewards, and requires 1000x less training frames compared to the previous SOTA Agent 57 on Skiing, the hardest game in Atari.
What Matters In The Structured Pruning of Generative Language Models?
Feb 07, 2023



Auto-regressive large language models such as GPT-3 require enormous computational resources to use. Traditionally, structured pruning methods are employed to reduce resource usage. However, their application to and efficacy for generative language models is heavily under-explored. In this paper we conduct an comprehensive evaluation of common structured pruning methods, including magnitude, random, and movement pruning on the feed-forward layers in GPT-type models. Unexpectedly, random pruning results in performance that is comparable to the best established methods, across multiple natural language generation tasks. To understand these results, we provide a framework for measuring neuron-level redundancy of models pruned by different methods, and discover that established structured pruning methods do not take into account the distinctiveness of neurons, leaving behind excess redundancies. In view of this, we introduce Globally Unique Movement (GUM) to improve the uniqueness of neurons in pruned models. We then discuss the effects of our techniques on different redundancy metrics to explain the improved performance.
How Does Adaptive Optimization Impact Local Neural Network Geometry?
Nov 04, 2022



Adaptive optimization methods are well known to achieve superior convergence relative to vanilla gradient methods. The traditional viewpoint in optimization, particularly in convex optimization, explains this improved performance by arguing that, unlike vanilla gradient schemes, adaptive algorithms mimic the behavior of a second-order method by adapting to the global geometry of the loss function. We argue that in the context of neural network optimization, this traditional viewpoint is insufficient. Instead, we advocate for a local trajectory analysis. For iterate trajectories produced by running a generic optimization algorithm OPT, we introduce $R^{\text{OPT}}_{\text{med}}$, a statistic that is analogous to the condition number of the loss Hessian evaluated at the iterates. Through extensive experiments, we show that adaptive methods such as Adam bias the trajectories towards regions where $R^{\text{Adam}}_{\text{med}}$ is small, where one might expect faster convergence. By contrast, vanilla gradient methods like SGD bias the trajectories towards regions where $R^{\text{SGD}}_{\text{med}}$ is comparatively large. We complement these empirical observations with a theoretical result that provably demonstrates this phenomenon in the simplified setting of a two-layer linear network. We view our findings as evidence for the need of a new explanation of the success of adaptive methods, one that is different than the conventional wisdom.
Vision Transformers provably learn spatial structure
Oct 13, 2022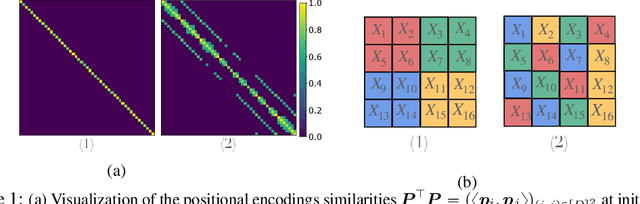
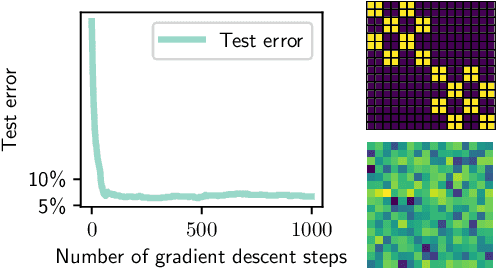
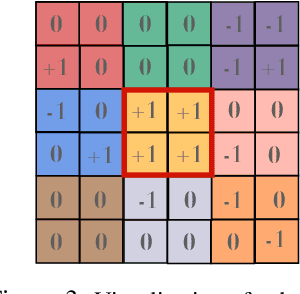
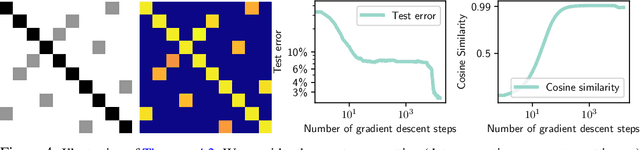
Vision Transformers (ViTs) have achieved comparable or superior performance than Convolutional Neural Networks (CNNs) in computer vision. This empirical breakthrough is even more remarkable since, in contrast to CNNs, ViTs do not embed any visual inductive bias of spatial locality. Yet, recent works have shown that while minimizing their training loss, ViTs specifically learn spatially localized patterns. This raises a central question: how do ViTs learn these patterns by solely minimizing their training loss using gradient-based methods from random initialization? In this paper, we provide some theoretical justification of this phenomenon. We propose a spatially structured dataset and a simplified ViT model. In this model, the attention matrix solely depends on the positional encodings. We call this mechanism the positional attention mechanism. On the theoretical side, we consider a binary classification task and show that while the learning problem admits multiple solutions that generalize, our model implicitly learns the spatial structure of the dataset while generalizing: we call this phenomenon patch association. We prove that patch association helps to sample-efficiently transfer to downstream datasets that share the same structure as the pre-training one but differ in the features. Lastly, we empirically verify that a ViT with positional attention performs similarly to the original one on CIFAR-10/100, SVHN and ImageNet.