 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023



Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020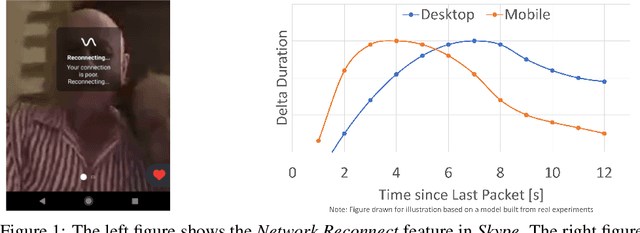


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
Programming by Rewards
Jul 14, 2020



We formalize and study ``programming by rewards'' (PBR), a new approach for specifying and synthesizing subroutines for optimizing some quantitative metric such as performance, resource utilization, or correctness over a benchmark. A PBR specification consists of (1) input features $x$, and (2) a reward function $r$, modeled as a black-box component (which we can only run), that assigns a reward for each execution. The goal of the synthesizer is to synthesize a "decision function" $f$ which transforms the features to a decision value for the black-box component so as to maximize the expected reward $E[r \circ f (x)]$ for executing decisions $f(x)$ for various values of $x$. We consider a space of decision functions in a DSL of loop-free if-then-else programs, which can branch on linear functions of the input features in a tree-structure and compute a linear function of the inputs in the leaves of the tree. We find that this DSL captures decision functions that are manually written in practice by programmers. Our technical contribution is the use of continuous-optimization techniques to perform synthesis of such decision functions as if-then-else programs. We also show that the framework is theoretically-founded ---in cases when the rewards satisfy nice properties, the synthesized code is optimal in a precise sense. We have leveraged PBR to synthesize non-trivial decision functions related to search and ranking heuristics in the PROSE codebase (an industrial strength program synthesis framework) and achieve competitive results to manually written procedures over multiple man years of tuning. We present empirical evaluation against other baseline techniques over real-world case studies (including PROSE) as well on simple synthetic benchmarks.
Lumos: A Library for Diagnosing Metric Regressions in Web-Scale Applications
Jun 23, 2020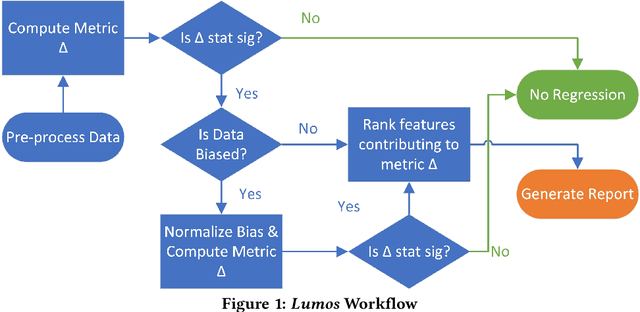

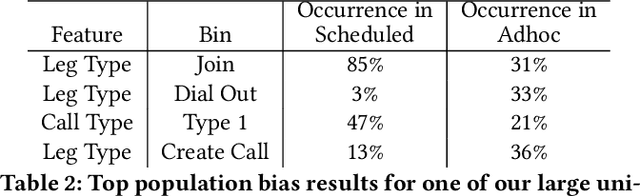
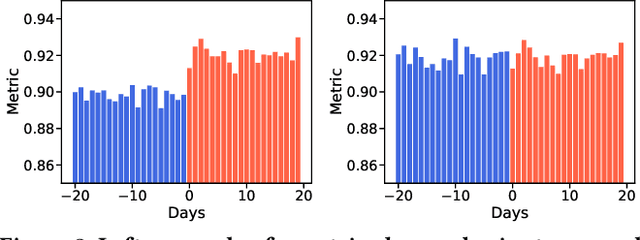
Web-scale applications can ship code on a daily to weekly cadence. These applications rely on online metrics to monitor the health of new releases. Regressions in metric values need to be detected and diagnosed as early as possible to reduce the disruption to users and product owners. Regressions in metrics can surface due to a variety of reasons: genuine product regressions, changes in user population, and bias due to telemetry loss (or processing) are among the common causes. Diagnosing the cause of these metric regressions is costly for engineering teams as they need to invest time in finding the root cause of the issue as soon as possible. We present Lumos, a Python library built using the principles of AB testing to systematically diagnose metric regressions to automate such analysis. Lumos has been deployed across the component teams in Microsoft's Real-Time Communication applications Skype and Microsoft Teams. It has enabled engineering teams to detect 100s of real changes in metrics and reject 1000s of false alarms detected by anomaly detectors. The application of Lumos has resulted in freeing up as much as 95% of the time allocated to metric-based investigations. In this work, we open source Lumos and present our results from applying it to two different components within the RTC group over millions of sessions. This general library can be coupled with any production system to manage the volume of alerting efficiently.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results
May 29, 2020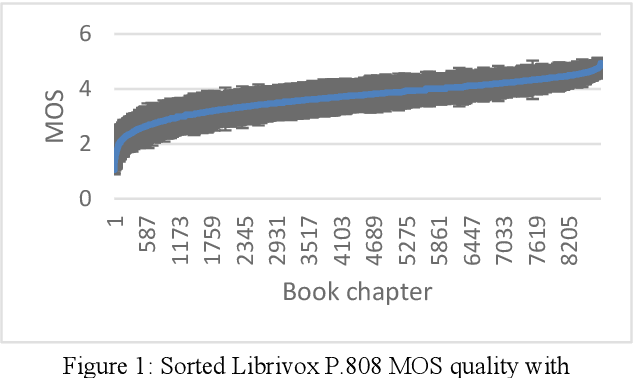

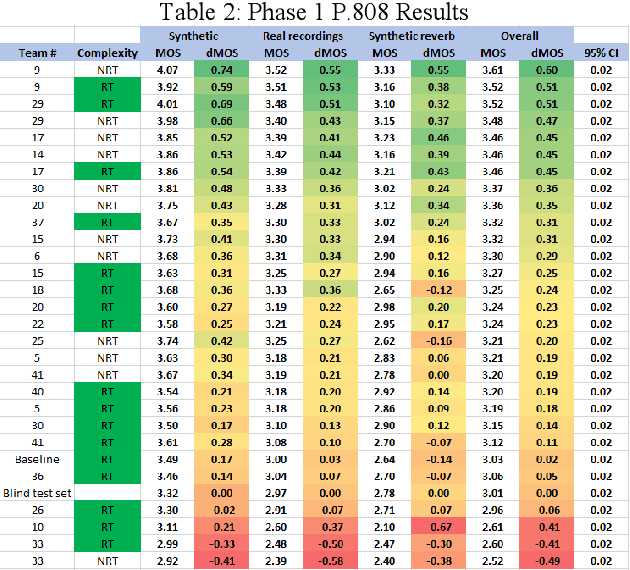
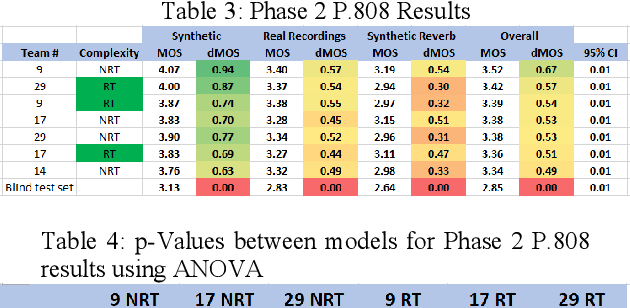
The INTERSPEECH 2020 Deep Noise Suppression (DNS) Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. While the performance is good on the synthetic test set, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-sourced a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open-sourced an online subjective test framework based on ITU-T P.808 for researchers to reliably test their developments. We evaluated the results using P.808 on a blind test set. The results and the key learnings from the challenge are discussed. The datasets and scripts can be found here for quick access https://github.com/microsoft/DNS-Challenge.
Qd-tree: Learning Data Layouts for Big Data Analytics
Apr 22, 2020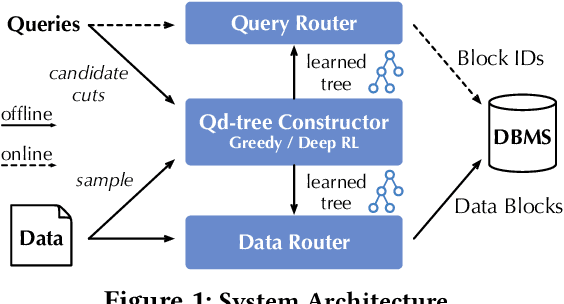

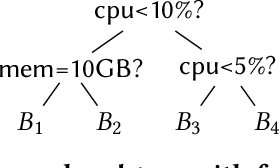
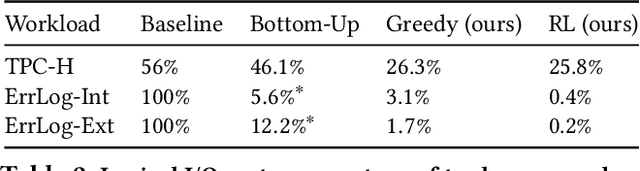
Corporations today collect data at an unprecedented and accelerating scale, making the need to run queries on large datasets increasingly important. Technologies such as columnar block-based data organization and compression have become standard practice in most commercial database systems. However, the problem of best assigning records to data blocks on storage is still open. For example, today's systems usually partition data by arrival time into row groups, or range/hash partition the data based on selected fields. For a given workload, however, such techniques are unable to optimize for the important metric of the number of blocks accessed by a query. This metric directly relates to the I/O cost, and therefore performance, of most analytical queries. Further, they are unable to exploit additional available storage to drive this metric down further. In this paper, we propose a new framework called a query-data routing tree, or qd-tree, to address this problem, and propose two algorithms for their construction based on greedy and deep reinforcement learning techniques. Experiments over benchmark and real workloads show that a qd-tree can provide physical speedups of more than an order of magnitude compared to current blocking schemes, and can reach within 2X of the lower bound for data skipping based on selectivity, while providing complete semantic descriptions of created blocks.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework
Jan 23, 2020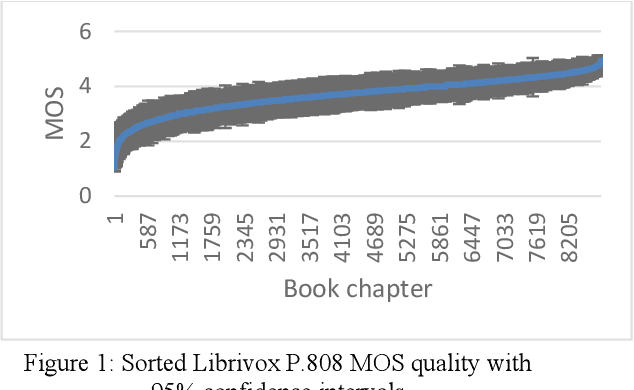

The INTERSPEECH 2020 Deep Noise Suppression Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. Many publications report reasonable performance on the synthetic test set drawn from the same distribution as that of the training set. However, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-source a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open source an online subjective test framework based on ITU-T P.808 for researchers to quickly test their developments. The winners of this challenge will be selected based on subjective evaluation on a representative test set using P.808 framework.
Reinforcement learning for bandwidth estimation and congestion control in real-time communications
Dec 04, 2019

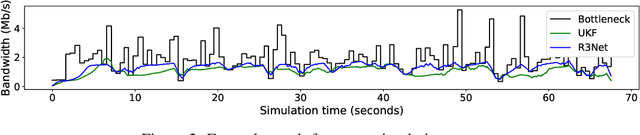
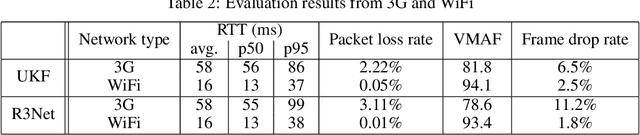
Bandwidth estimation and congestion control for real-time communications (i.e., audio and video conferencing) remains a difficult problem, despite many years of research. Achieving high quality of experience (QoE) for end users requires continual updates due to changing network architectures and technologies. In this paper, we apply reinforcement learning for the first time to the problem of real-time communications (RTC), where we seek to optimize user-perceived quality. We present initial proof-of-concept results, where we learn an agent to control sending rate in an RTC system, evaluating using both network simulation and real Internet video calls. We discuss the challenges we observed, particularly in designing realistic reward functions that reflect QoE, and in bridging the gap between the training environment and real-world networks.
A scalable noisy speech dataset and online subjective test framework
Sep 17, 2019
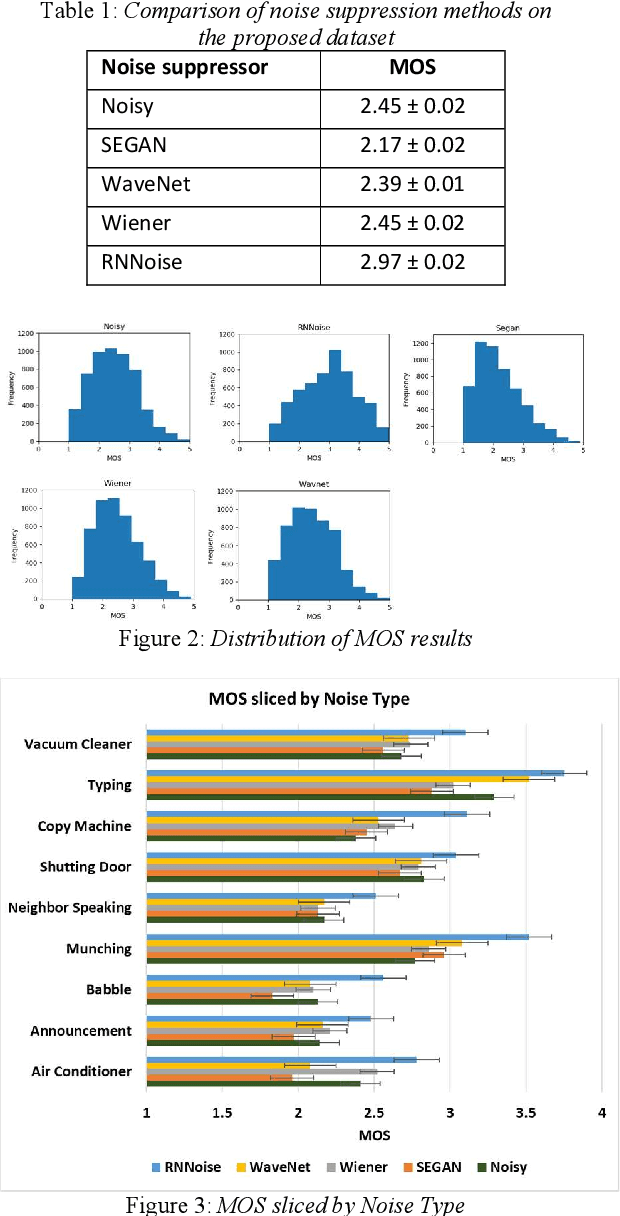
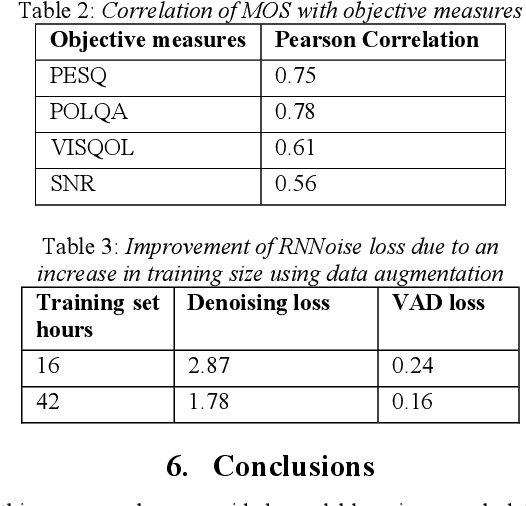
Background noise is a major source of quality impairments in Voice over Internet Protocol (VoIP) and Public Switched Telephone Network (PSTN) calls. Recent work shows the efficacy of deep learning for noise suppression, but the datasets have been relatively small compared to those used in other domains (e.g., ImageNet) and the associated evaluations have been more focused. In order to better facilitate deep learning research in Speech Enhancement, we present a noisy speech dataset (MS-SNSD) that can scale to arbitrary sizes depending on the number of speakers, noise types, and Speech to Noise Ratio (SNR) levels desired. We show that increasing dataset sizes increases noise suppression performance as expected. In addition, we provide an open-source evaluation methodology to evaluate the results subjectively at scale using crowdsourcing, with a reference algorithm to normalize the results. To demonstrate the dataset and evaluation framework we apply it to several noise suppressors and compare the subjective Mean Opinion Score (MOS) with objective quality measures such as SNR, PESQ, POLQA, and VISQOL and show why MOS is still required. Our subjective MOS evaluation is the first large scale evaluation of Speech Enhancement algorithms that we are aware of.
Supervised Classifiers for Audio Impairments with Noisy Labels
Jul 03, 2019
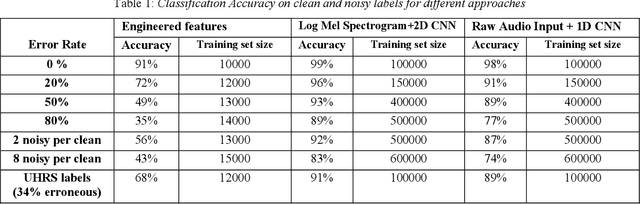
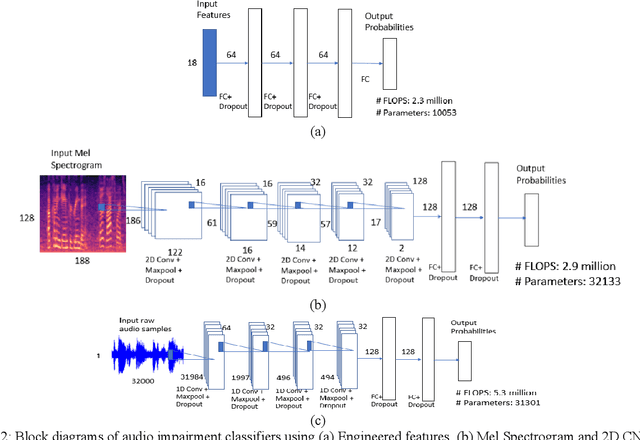
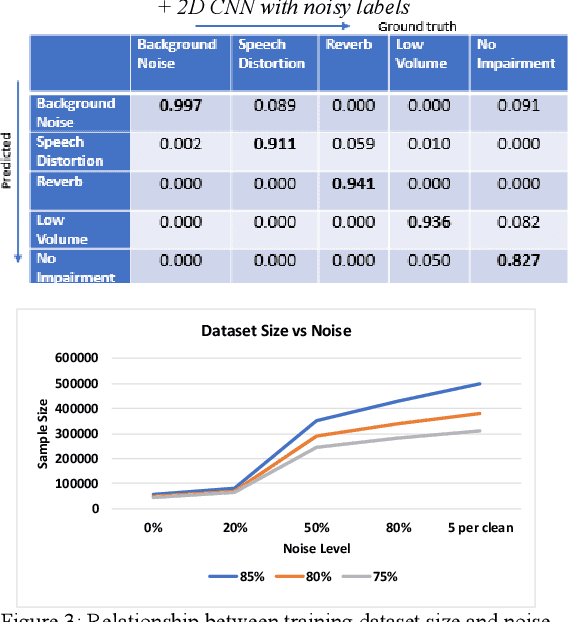
Voice-over-Internet-Protocol (VoIP) calls are prone to various speech impairments due to environmental and network conditions resulting in bad user experience. A reliable audio impairment classifier helps to identify the cause for bad audio quality. The user feedback after the call can act as the ground truth labels for training a supervised classifier on a large audio dataset. However, the labels are noisy as most of the users lack the expertise to precisely articulate the impairment in the perceived speech. In this paper, we analyze the effects of massive noise in labels in training dense networks and Convolutional Neural Networks (CNN) using engineered features, spectrograms and raw audio samples as inputs. We demonstrate that CNN can generalize better on the training data with a large number of noisy labels and gives remarkably higher test performance. The classifiers were trained both on randomly generated label noise and the label noise introduced by human errors. We also show that training with noisy labels requires a significant increase in the training dataset size, which is in proportion to the amount of noise in the labels.