 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffPatch: Generating Customizable Adversarial Patches using Diffusion Model
Dec 02, 2024
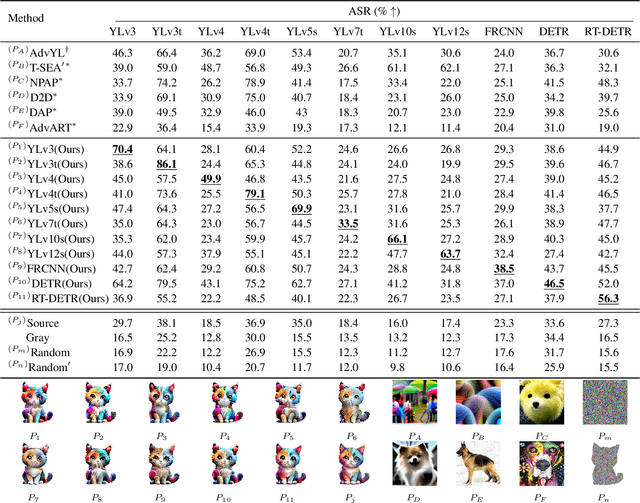
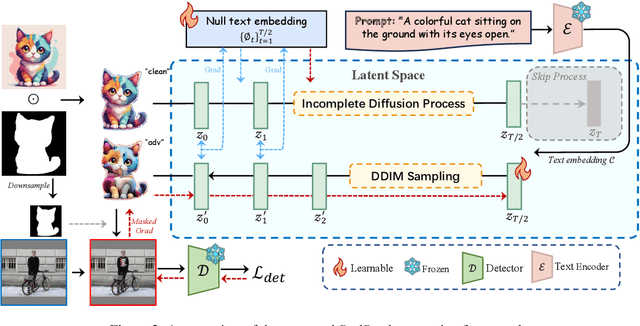
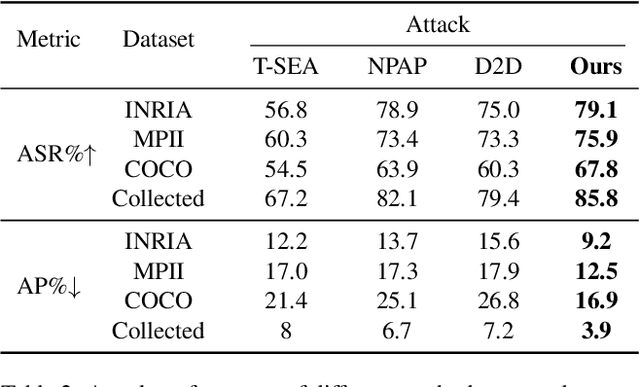
Physical adversarial patches printed on clothing can easily allow individuals to evade person detectors. However, most existing adversarial patch generation methods prioritize attack effectiveness over stealthiness, resulting in patches that are aesthetically unpleasing. Although existing methods using generative adversarial networks or diffusion models can produce more natural-looking patches, they often struggle to balance stealthiness with attack effectiveness and lack flexibility for user customization. To address these challenges, we propose a novel diffusion-based customizable patch generation framework termed DiffPatch, specifically tailored for creating naturalistic and customizable adversarial patches. Our approach enables users to utilize a reference image as the source, rather than starting from random noise, and incorporates masks to craft naturalistic patches of various shapes, not limited to squares. To prevent the original semantics from being lost during the diffusion process, we employ Null-text inversion to map random noise samples to a single input image and generate patches through Incomplete Diffusion Optimization (IDO). Notably, while maintaining a natural appearance, our method achieves a comparable attack performance to state-of-the-art non-naturalistic patches when using similarly sized attacks. Using DiffPatch, we have created a physical adversarial T-shirt dataset, AdvPatch-1K, specifically targeting YOLOv5s. This dataset includes over a thousand images across diverse scenarios, validating the effectiveness of our attack in real-world environments. Moreover, it provides a valuable resource for future research.
ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipulation Detection
Nov 29, 2024



Multimodal large language models have unlocked new possibilities for various multimodal tasks. However, their potential in image manipulation detection remains unexplored. When directly applied to the IMD task, M-LLMs often produce reasoning texts that suffer from hallucinations and overthinking. To address this, in this work, we propose ForgerySleuth, which leverages M-LLMs to perform comprehensive clue fusion and generate segmentation outputs indicating specific regions that are tampered with. Moreover, we construct the ForgeryAnalysis dataset through the Chain-of-Clues prompt, which includes analysis and reasoning text to upgrade the image manipulation detection task. A data engine is also introduced to build a larger-scale dataset for the pre-training phase. Our extensive experiments demonstrate the effectiveness of ForgeryAnalysis and show that ForgerySleuth significantly outperforms existing methods in generalization, robustness, and explainability.
LoRA of Change: Learning to Generate LoRA for the Editing Instruction from A Single Before-After Image Pair
Nov 28, 2024In this paper, we propose the LoRA of Change (LoC) framework for image editing with visual instructions, i.e., before-after image pairs. Compared to the ambiguities, insufficient specificity, and diverse interpretations of natural language, visual instructions can accurately reflect users' intent. Building on the success of LoRA in text-based image editing and generation, we dynamically learn an instruction-specific LoRA to encode the "change" in a before-after image pair, enhancing the interpretability and reusability of our model. Furthermore, generalizable models for image editing with visual instructions typically require quad data, i.e., a before-after image pair, along with query and target images. Due to the scarcity of such quad data, existing models are limited to a narrow range of visual instructions. To overcome this limitation, we introduce the LoRA Reverse optimization technique, enabling large-scale training with paired data alone. Extensive qualitative and quantitative experiments demonstrate that our model produces high-quality images that align with user intent and support a broad spectrum of real-world visual instructions.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024



Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition
Nov 24, 2024Connectionist temporal classification (CTC)-based scene text recognition (STR) methods, e.g., SVTR, are widely employed in OCR applications, mainly due to their simple architecture, which only contains a visual model and a CTC-aligned linear classifier, and therefore fast inference. However, they generally have worse accuracy than encoder-decoder-based methods (EDTRs), particularly in challenging scenarios. In this paper, we propose SVTRv2, a CTC model that beats leading EDTRs in both accuracy and inference speed. SVTRv2 introduces novel upgrades to handle text irregularity and utilize linguistic context, which endows it with the capability to deal with challenging and diverse text instances. First, a multi-size resizing (MSR) strategy is proposed to adaptively resize the text and maintain its readability. Meanwhile, we introduce a feature rearrangement module (FRM) to ensure that visual features accommodate the alignment requirement of CTC well, thus alleviating the alignment puzzle. Second, we propose a semantic guidance module (SGM). It integrates linguistic context into the visual model, allowing it to leverage language information for improved accuracy. Moreover, SGM can be omitted at the inference stage and would not increase the inference cost. We evaluate SVTRv2 in both standard and recent challenging benchmarks, where SVTRv2 is fairly compared with 24 mainstream STR models across multiple scenarios, including different types of text irregularity, languages, and long text. The results indicate that SVTRv2 surpasses all the EDTRs across the scenarios in terms of accuracy and speed. Code is available at https://github.com/Topdu/OpenOCR.
REDUCIO! Generating 1024$\times$1024 Video within 16 Seconds using Extremely Compressed Motion Latents
Nov 20, 2024



Commercial video generation models have exhibited realistic, high-fidelity results but are still restricted to limited access. One crucial obstacle for large-scale applications is the expensive training and inference cost. In this paper, we argue that videos contain much more redundant information than images, thus can be encoded by very few motion latents based on a content image. Towards this goal, we design an image-conditioned VAE to encode a video to an extremely compressed motion latent space. This magic Reducio charm enables 64x reduction of latents compared to a common 2D VAE, without sacrificing the quality. Training diffusion models on such a compact representation easily allows for generating 1K resolution videos. We then adopt a two-stage video generation paradigm, which performs text-to-image and text-image-to-video sequentially. Extensive experiments show that our Reducio-DiT achieves strong performance in evaluation, though trained with limited GPU resources. More importantly, our method significantly boost the efficiency of video LDMs both in training and inference. We train Reducio-DiT in around 3.2K training hours in total and generate a 16-frame 1024*1024 video clip within 15.5 seconds on a single A100 GPU. Code released at https://github.com/microsoft/Reducio-VAE .
Visual Cue Enhancement and Dual Low-Rank Adaptation for Efficient Visual Instruction Fine-Tuning
Nov 19, 2024Fine-tuning multimodal large language models (MLLMs) presents significant challenges, including a reliance on high-level visual features that limits fine-grained detail comprehension, and data conflicts that arise from task complexity. To address these issues, we propose an efficient fine-tuning framework with two novel approaches: Vision Cue Enhancement (VCE) and Dual Low-Rank Adaptation (Dual-LoRA). VCE enhances the vision projector by integrating multi-level visual cues, improving the model's ability to capture fine-grained visual features. Dual-LoRA introduces a dual low-rank structure for instruction tuning, decoupling learning into skill and task spaces to enable precise control and efficient adaptation across diverse tasks. Our method simplifies implementation, enhances visual comprehension, and improves adaptability. Experiments on both downstream tasks and general benchmarks demonstrate the effectiveness of our proposed approach.
Retrieval Augmented Recipe Generation
Nov 13, 2024Given the potential applications of generating recipes from food images, this area has garnered significant attention from researchers in recent years. Existing works for recipe generation primarily utilize a two-stage training method, first generating ingredients and then obtaining instructions from both the image and ingredients. Large Multi-modal Models (LMMs), which have achieved notable success across a variety of vision and language tasks, shed light to generating both ingredients and instructions directly from images. Nevertheless, LMMs still face the common issue of hallucinations during recipe generation, leading to suboptimal performance. To tackle this, we propose a retrieval augmented large multimodal model for recipe generation. We first introduce Stochastic Diversified Retrieval Augmentation (SDRA) to retrieve recipes semantically related to the image from an existing datastore as a supplement, integrating them into the prompt to add diverse and rich context to the input image. Additionally, Self-Consistency Ensemble Voting mechanism is proposed to determine the most confident prediction recipes as the final output. It calculates the consistency among generated recipe candidates, which use different retrieval recipes as context for generation. Extensive experiments validate the effectiveness of our proposed method, which demonstrates state-of-the-art (SOTA) performance in recipe generation tasks on the Recipe1M dataset.
Domain Expansion and Boundary Growth for Open-Set Single-Source Domain Generalization
Nov 05, 2024



Open-set single-source domain generalization aims to use a single-source domain to learn a robust model that can be generalized to unknown target domains with both domain shifts and label shifts. The scarcity of the source domain and the unknown data distribution of the target domain pose a great challenge for domain-invariant feature learning and unknown class recognition. In this paper, we propose a novel learning approach based on domain expansion and boundary growth to expand the scarce source samples and enlarge the boundaries across the known classes that indirectly broaden the boundary between the known and unknown classes. Specifically, we achieve domain expansion by employing both background suppression and style augmentation on the source data to synthesize new samples. Then we force the model to distill consistent knowledge from the synthesized samples so that the model can learn domain-invariant information. Furthermore, we realize boundary growth across classes by using edge maps as an additional modality of samples when training multi-binary classifiers. In this way, it enlarges the boundary between the inliers and outliers, and consequently improves the unknown class recognition during open-set generalization. Extensive experiments show that our approach can achieve significant improvements and reach state-of-the-art performance on several cross-domain image classification datasets.
IDEATOR: Jailbreaking VLMs Using VLMs
Oct 29, 2024



As large Vision-Language Models (VLMs) continue to gain prominence, ensuring their safety deployment in real-world applications has become a critical concern. Recently, significant research efforts have focused on evaluating the robustness of VLMs against jailbreak attacks. Due to challenges in obtaining multi-modal data, current studies often assess VLM robustness by generating adversarial or query-relevant images based on harmful text datasets. However, the jailbreak images generated this way exhibit certain limitations. Adversarial images require white-box access to the target VLM and are relatively easy to defend against, while query-relevant images must be linked to the target harmful content, limiting their diversity and effectiveness. In this paper, we propose a novel jailbreak method named IDEATOR, which autonomously generates malicious image-text pairs for black-box jailbreak attacks. IDEATOR is a VLM-based approach inspired by our conjecture that a VLM itself might be a powerful red team model for generating jailbreak prompts. Specifically, IDEATOR employs a VLM to generate jailbreak texts while leveraging a state-of-the-art diffusion model to create corresponding jailbreak images. Extensive experiments demonstrate the high effectiveness and transferability of IDEATOR. It successfully jailbreaks MiniGPT-4 with a 94% success rate and transfers seamlessly to LLaVA and InstructBLIP, achieving high success rates of 82% and 88%, respectively. IDEATOR uncovers previously unrecognized vulnerabilities in VLMs, calling for advanced safety mechanisms.