 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Task Tree Generation from a Knowledge Graph to Solve Unseen Problems
Dec 04, 2021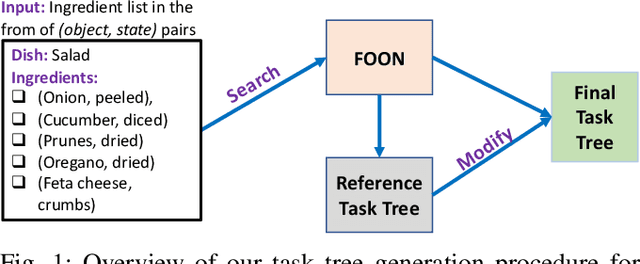
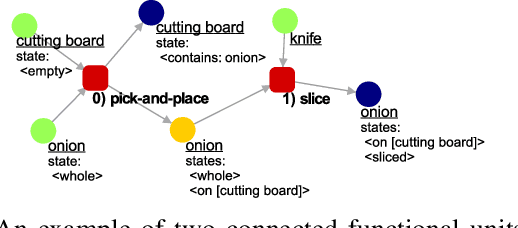
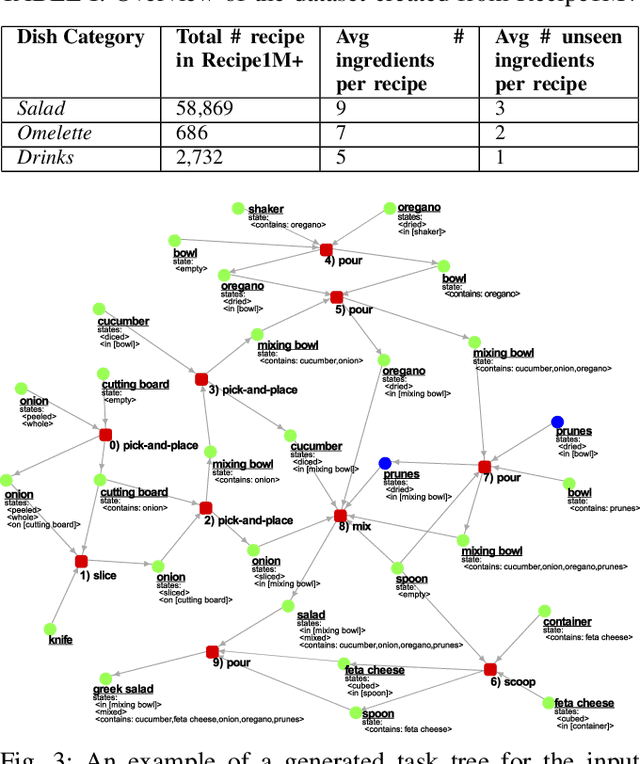

A major component for developing intelligent and autonomous robots is a suitable knowledge representation, from which a robot can acquire knowledge about its actions or world. However, unlike humans, robots cannot creatively adapt to novel scenarios, as their knowledge and environment are rigidly defined. To address the problem of producing novel and flexible task plans called task trees, we explore how we can derive plans with concepts not originally in the robot's knowledge base. Existing knowledge in the form of a knowledge graph is used as a base of reference to create task trees that are modified with new object or state combinations. To demonstrate the flexibility of our method, we randomly selected recipes from the Recipe1M+ dataset and generated their task trees. The task trees were then thoroughly checked with a visualization tool that portrays how each ingredient changes with each action to produce the desired meal. Our results indicate that the proposed method can produce task plans with high accuracy even for never-before-seen ingredient combinations.
Multi-Object Grasping -- Estimating the Number of Objects in a Robotic Grasp
Nov 30, 2021

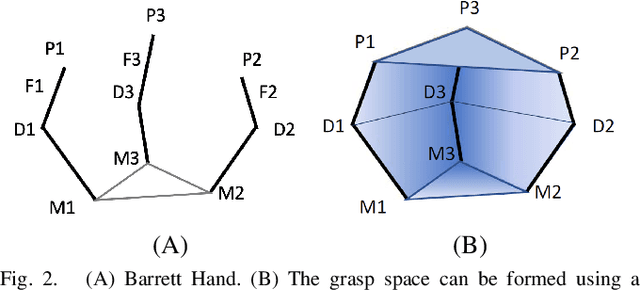

A human hand can grasp a desired number of objects at once from a pile based solely on tactile sensing. To do so, a robot needs to grasp within a pile, sense the number of objects in the grasp before lifting, and predict the number of objects that will remain in the grasp after lifting. It is a challenging problem because when making the prediction, the robotic hand is still in the pile and the objects in the grasp are not observable to vision systems. Moreover, some objects that are grasped by the hand before lifting from the pile may fall out of the grasp when the hand is lifted. This occurs because they were supported by other objects in the pile instead of the fingers of the hand. Therefore, a robotic hand should sense the number of objects in a grasp using its tactile sensors before lifting. This paper presents novel multi-object grasping analyzing methods for solving this problem. They include a grasp volume calculation, tactile force analysis, and a data-driven deep learning approach. The methods have been implemented on a Barrett hand and then evaluated in simulations and a real setup with a robotic system. The evaluation results conclude that once the Barrett hand grasps multiple objects in the pile, the data-driven model can predict, before lifting, the number of objects that will remain in the hand after lifting. The root-mean-square errors for our approach are 0.74 for balls and 0.58 for cubes in simulations, and 1.06 for balls, and 1.45 for cubes in the real system.
Zero-Shot Learning of Continuous 3D Refractive Index Maps from Discrete Intensity-Only Measurements
Nov 27, 2021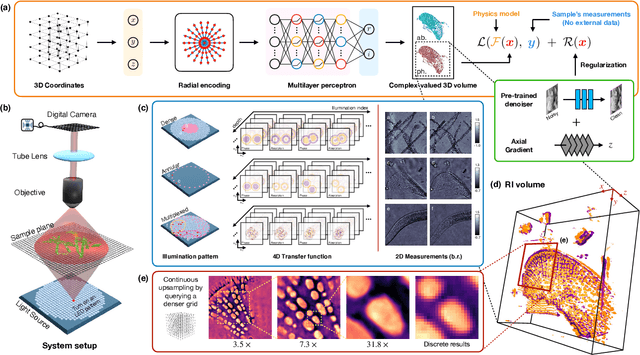

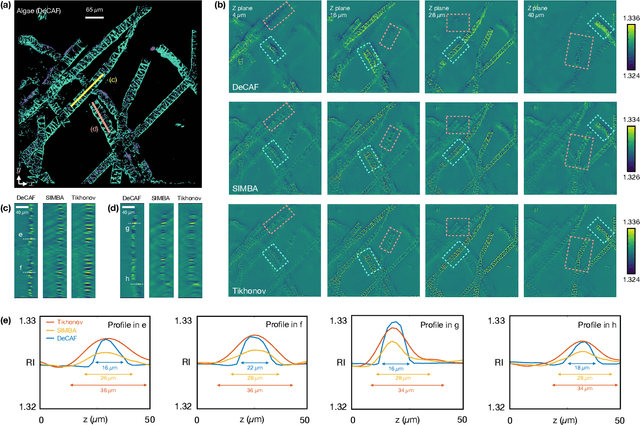
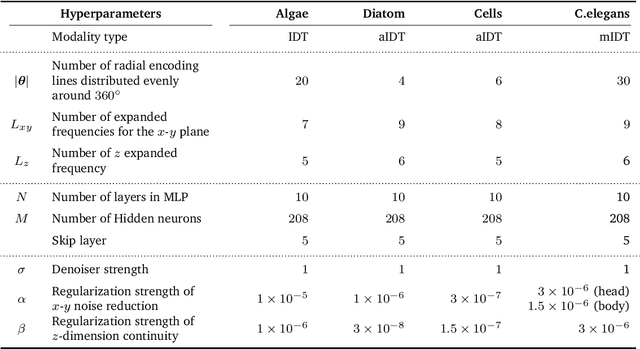
Intensity diffraction tomography (IDT) refers to a class of optical microscopy techniques for imaging the 3D refractive index (RI) distribution of a sample from a set of 2D intensity-only measurements. The reconstruction of artifact-free RI maps is a fundamental challenge in IDT due to the loss of phase information and the missing cone problem. Neural fields (NF) has recently emerged as a new deep learning (DL) paradigm for learning continuous representations of complex 3D scenes without external training datasets. We present DeCAF as the first NF-based IDT method that can learn a high-quality continuous representation of a RI volume directly from its intensity-only and limited-angle measurements. We show on three different IDT modalities and multiple biological samples that DeCAF can generate high-contrast and artifact-free RI maps.
Hierarchical Graph Networks for 3D Human Pose Estimation
Nov 23, 2021
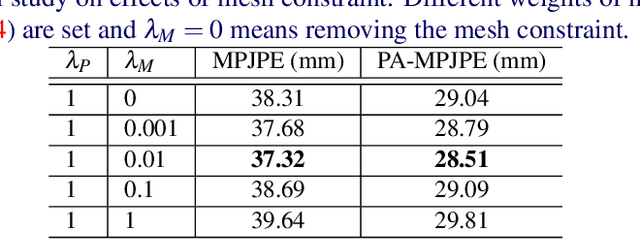
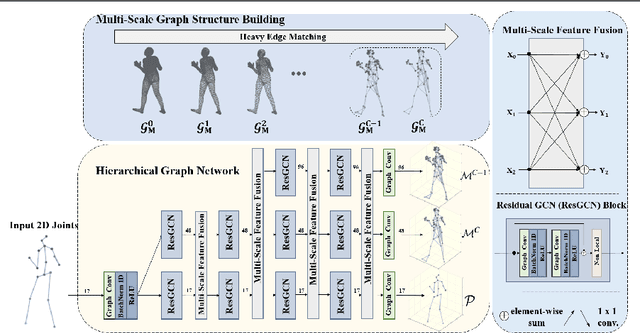
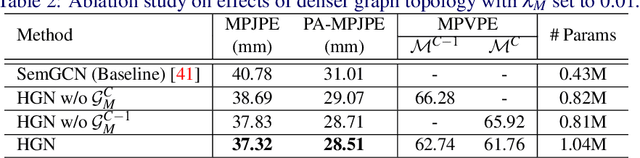
Recent 2D-to-3D human pose estimation works tend to utilize the graph structure formed by the topology of the human skeleton. However, we argue that this skeletal topology is too sparse to reflect the body structure and suffer from serious 2D-to-3D ambiguity problem. To overcome these weaknesses, we propose a novel graph convolution network architecture, Hierarchical Graph Networks (HGN). It is based on denser graph topology generated by our multi-scale graph structure building strategy, thus providing more delicate geometric information. The proposed architecture contains three sparse-to-fine representation subnetworks organized in parallel, in which multi-scale graph-structured features are processed and exchange information through a novel feature fusion strategy, leading to rich hierarchical representations. We also introduce a 3D coarse mesh constraint to further boost detail-related feature learning. Extensive experiments demonstrate that our HGN achieves the state-of-the art performance with reduced network parameters
Pattern Recognition in Vital Signs Using Spectrograms
Sep 02, 2021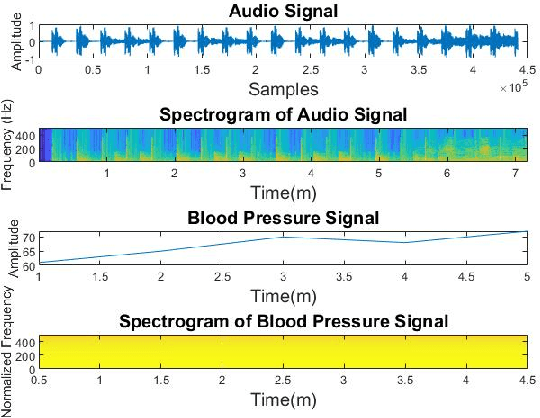
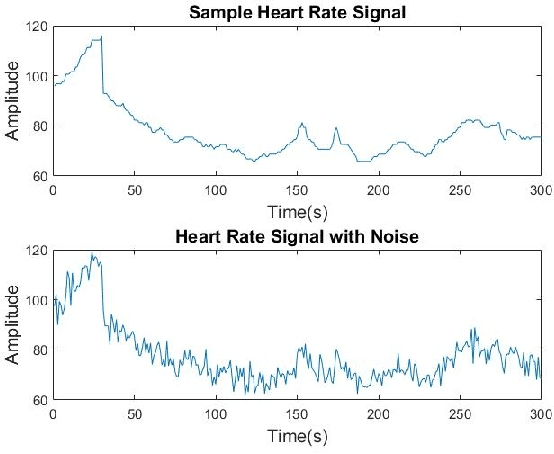
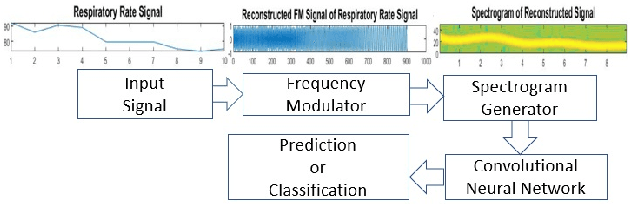
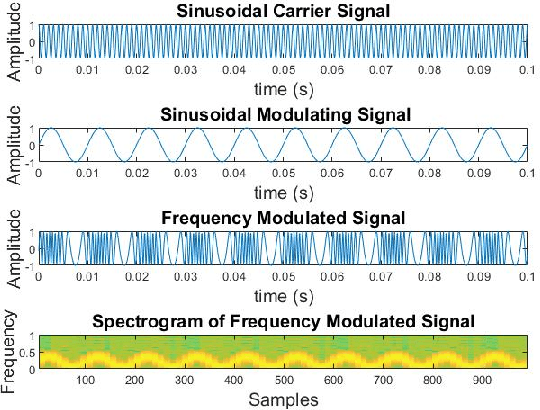
Spectrograms visualize the frequency components of a given signal which may be an audio signal or even a time-series signal. Audio signals have higher sampling rate and high variability of frequency with time. Spectrograms can capture such variations well. But, vital signs which are time-series signals have less sampling frequency and low-frequency variability due to which, spectrograms fail to express variations and patterns. In this paper, we propose a novel solution to introduce frequency variability using frequency modulation on vital signs. Then we apply spectrograms on frequency modulated signals to capture the patterns. The proposed approach has been evaluated on 4 different medical datasets across both prediction and classification tasks. Significant results are found showing the efficacy of the approach for vital sign signals. The results from the proposed approach are promising with an accuracy of 91.55% and 91.67% in prediction and classification tasks respectively.
Research Challenges and Progress in Robotic Grasping and Manipulation Competitions
Aug 03, 2021


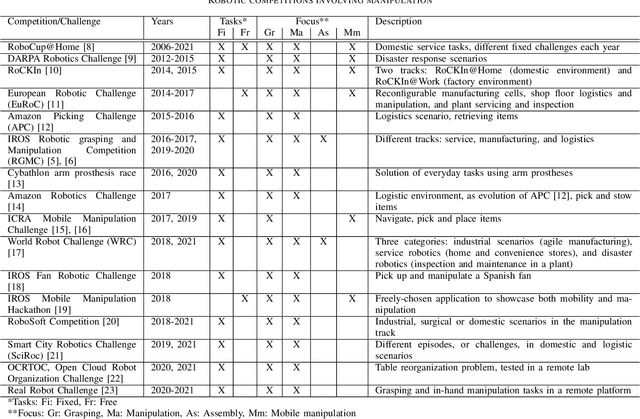
This paper discusses recent research progress in robotic grasping and manipulation in the light of the latest Robotic Grasping and Manipulation Competitions (RGMCs). We first provide an overview of past benchmarks and competitions related to the robotics manipulation field. Then, we discuss the methodology behind designing the manipulation tasks in RGMCs. We provide a detailed analysis of key challenges for each task and identify the most difficult aspects based on the competing teams' performance in recent years. We believe that such an analysis is insightful to determine the future research directions for the robotic manipulation domain.
MoDIR: Motion-Compensated Training for Deep Image Reconstruction without Ground Truth
Jul 12, 2021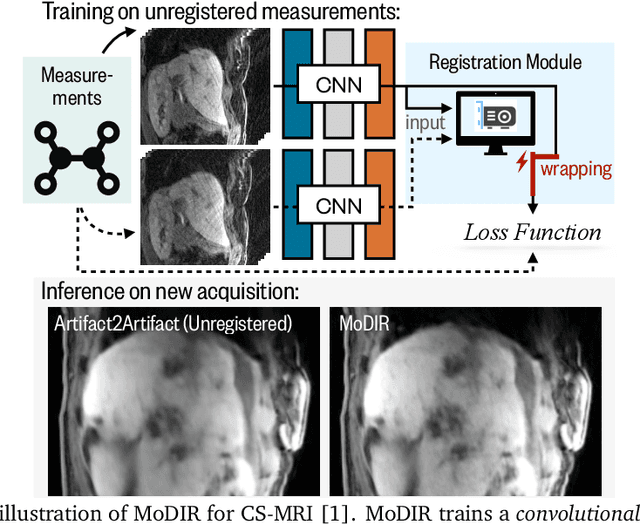
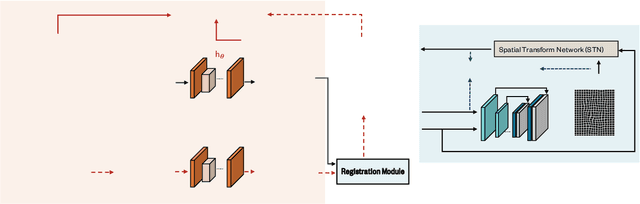
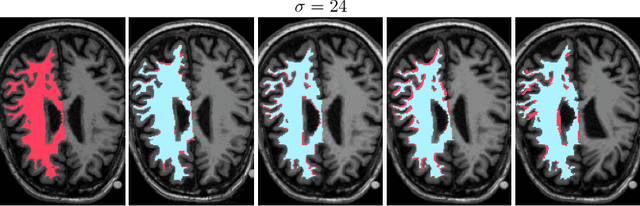
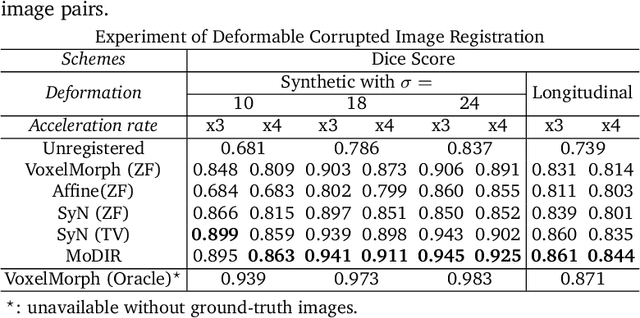
Deep neural networks for medical image reconstruction are traditionally trained using high-quality ground-truth images as training targets. Recent work onNoise2Noise (N2N) has shown the potential of using multiple noisy measurements of the same object as an alternative to having a ground truth. However, existing N2N-based methods cannot exploit information from various motion states, limiting their ability to learn on moving objects. This paper addresses this issue by proposing a novel motion-compensated deep image reconstruction (MoDIR) method that can use information from several unregistered and noisy measurements for training. MoDIR deals with object motion by including a deep registration module jointly trained with the deep reconstruction network without any ground-truth supervision. We validate MoDIR on both simulated and experimentally collected magnetic resonance imaging (MRI) data and show that it significantly improves imaging quality.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021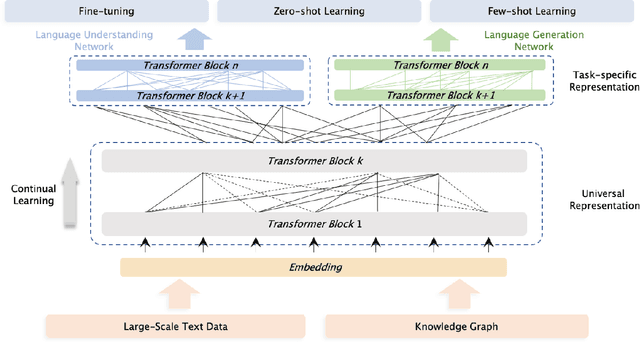

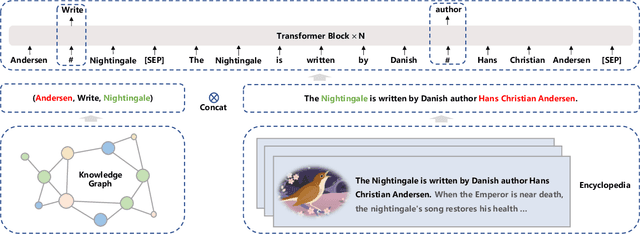
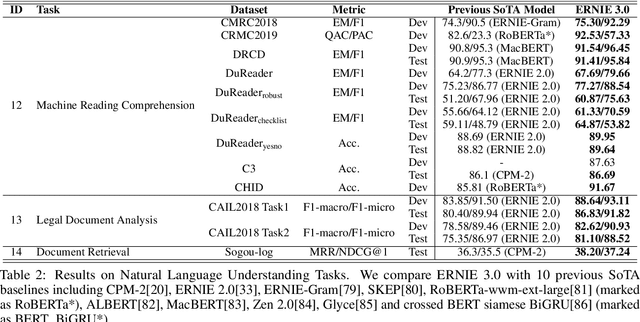
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
ERNIE-Tiny : A Progressive Distillation Framework for Pretrained Transformer Compression
Jun 04, 2021
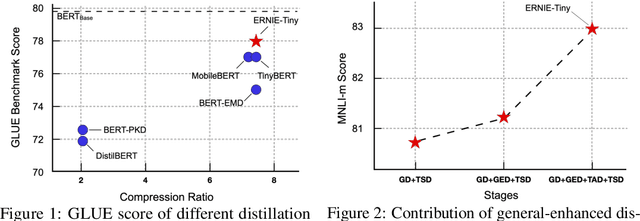
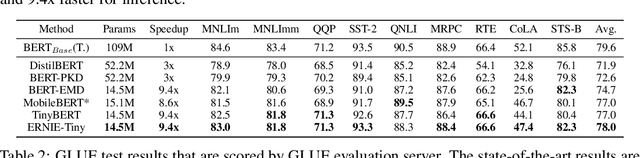
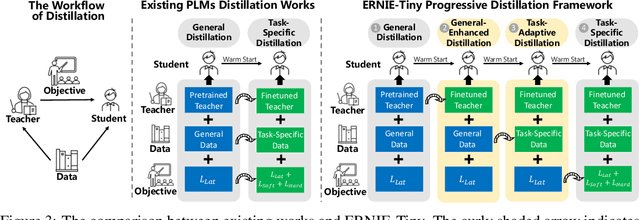
Pretrained language models (PLMs) such as BERT adopt a training paradigm which first pretrain the model in general data and then finetune the model on task-specific data, and have recently achieved great success. However, PLMs are notorious for their enormous parameters and hard to be deployed on real-life applications. Knowledge distillation has been prevailing to address this problem by transferring knowledge from a large teacher to a much smaller student over a set of data. We argue that the selection of thee three key components, namely teacher, training data, and learning objective, is crucial to the effectiveness of distillation. We, therefore, propose a four-stage progressive distillation framework ERNIE-Tiny to compress PLM, which varies the three components gradually from general level to task-specific level. Specifically, the first stage, General Distillation, performs distillation with guidance from pretrained teacher, gerenal data and latent distillation loss. Then, General-Enhanced Distillation changes teacher model from pretrained teacher to finetuned teacher. After that, Task-Adaptive Distillation shifts training data from general data to task-specific data. In the end, Task-Specific Distillation, adds two additional losses, namely Soft-Label and Hard-Label loss onto the last stage. Empirical results demonstrate the effectiveness of our framework and generalization gain brought by ERNIE-Tiny.In particular, experiments show that a 4-layer ERNIE-Tiny maintains over 98.0%performance of its 12-layer teacher BERT base on GLUE benchmark, surpassing state-of-the-art (SOTA) by 1.0% GLUE score with the same amount of parameters. Moreover, ERNIE-Tiny achieves a new compression SOTA on five Chinese NLP tasks, outperforming BERT base by 0.4% accuracy with 7.5x fewer parameters and9.4x faster inference speed.
Evaluating Recipes Generated from Functional Object-Oriented Network
Jun 01, 2021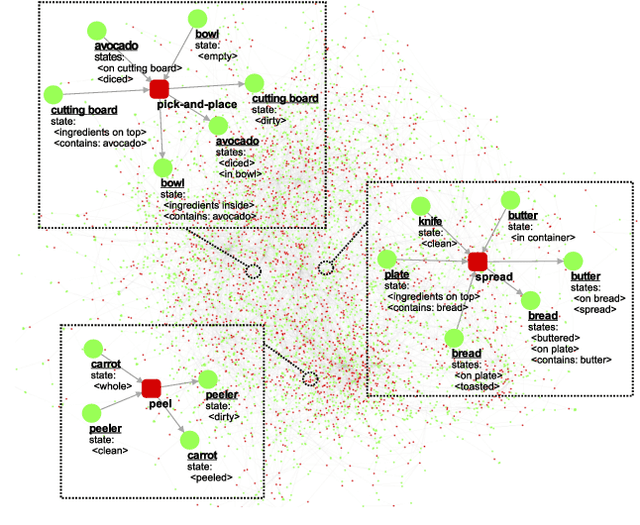
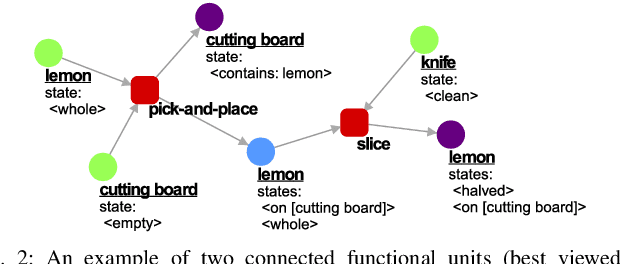
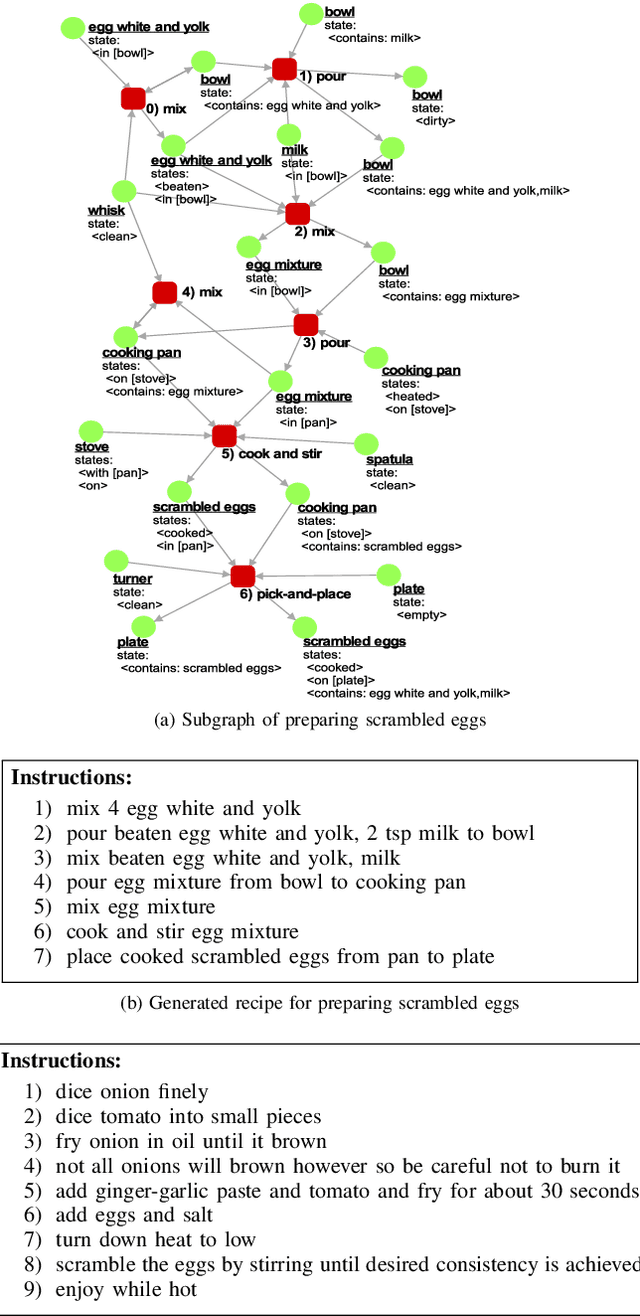

The functional object-oriented network (FOON) has been introduced as a knowledge representation, which takes the form of a graph, for symbolic task planning. To get a sequential plan for a manipulation task, a robot can obtain a task tree through a knowledge retrieval process from the FOON. To evaluate the quality of an acquired task tree, we compare it with a conventional form of task knowledge, such as recipes or manuals. We first automatically convert task trees to recipes, and we then compare them with the human-created recipes in the Recipe1M+ dataset via a survey. Our preliminary study finds no significant difference between the recipes in Recipe1M+ and the recipes generated from FOON task trees in terms of correctness, completeness, and clarity.