 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Active Attacks: Red-teaming LLMs via Adaptive Environments
Sep 26, 2025



We address the challenge of generating diverse attack prompts for large language models (LLMs) that elicit harmful behaviors (e.g., insults, sexual content) and are used for safety fine-tuning. Rather than relying on manual prompt engineering, attacker LLMs can be trained with reinforcement learning (RL) to automatically generate such prompts using only a toxicity classifier as a reward. However, capturing a wide range of harmful behaviors is a significant challenge that requires explicit diversity objectives. Existing diversity-seeking RL methods often collapse to limited modes: once high-reward prompts are found, exploration of new regions is discouraged. Inspired by the active learning paradigm that encourages adaptive exploration, we introduce \textit{Active Attacks}, a novel RL-based red-teaming algorithm that adapts its attacks as the victim evolves. By periodically safety fine-tuning the victim LLM with collected attack prompts, rewards in exploited regions diminish, which forces the attacker to seek unexplored vulnerabilities. This process naturally induces an easy-to-hard exploration curriculum, where the attacker progresses beyond easy modes toward increasingly difficult ones. As a result, Active Attacks uncovers a wide range of local attack modes step by step, and their combination achieves wide coverage of the multi-mode distribution. Active Attacks, a simple plug-and-play module that seamlessly integrates into existing RL objectives, unexpectedly outperformed prior RL-based methods -- including GFlowNets, PPO, and REINFORCE -- by improving cross-attack success rates against GFlowNets, the previous state-of-the-art, from 0.07% to 31.28% (a relative gain greater than $400\ \times$) with only a 6% increase in computation. Our code is publicly available \href{https://github.com/dbsxodud-11/active_attacks}{here}.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025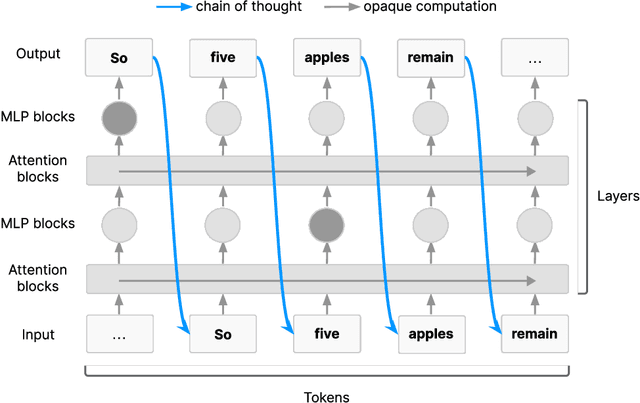
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Torsional-GFN: a conditional conformation generator for small molecules
Jul 15, 2025Generating stable molecular conformations is crucial in several drug discovery applications, such as estimating the binding affinity of a molecule to a target. Recently, generative machine learning methods have emerged as a promising, more efficient method than molecular dynamics for sampling of conformations from the Boltzmann distribution. In this paper, we introduce Torsional-GFN, a conditional GFlowNet specifically designed to sample conformations of molecules proportionally to their Boltzmann distribution, using only a reward function as training signal. Conditioned on a molecular graph and its local structure (bond lengths and angles), Torsional-GFN samples rotations of its torsion angles. Our results demonstrate that Torsional-GFN is able to sample conformations approximately proportional to the Boltzmann distribution for multiple molecules with a single model, and allows for zero-shot generalization to unseen bond lengths and angles coming from the MD simulations for such molecules. Our work presents a promising avenue for scaling the proposed approach to larger molecular systems, achieving zero-shot generalization to unseen molecules, and including the generation of the local structure into the GFlowNet model.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Fast Monte Carlo Tree Diffusion: 100x Speedup via Parallel Sparse Planning
Jun 11, 2025Diffusion models have recently emerged as a powerful approach for trajectory planning. However, their inherently non-sequential nature limits their effectiveness in long-horizon reasoning tasks at test time. The recently proposed Monte Carlo Tree Diffusion (MCTD) offers a promising solution by combining diffusion with tree-based search, achieving state-of-the-art performance on complex planning problems. Despite its strengths, our analysis shows that MCTD incurs substantial computational overhead due to the sequential nature of tree search and the cost of iterative denoising. To address this, we propose Fast-MCTD, a more efficient variant that preserves the strengths of MCTD while significantly improving its speed and scalability. Fast-MCTD integrates two techniques: Parallel MCTD, which enables parallel rollouts via delayed tree updates and redundancy-aware selection; and Sparse MCTD, which reduces rollout length through trajectory coarsening. Experiments show that Fast-MCTD achieves up to 100x speedup over standard MCTD while maintaining or improving planning performance. Remarkably, it even outperforms Diffuser in inference speed on some tasks, despite Diffuser requiring no search and yielding weaker solutions. These results position Fast-MCTD as a practical and scalable solution for diffusion-based inference-time reasoning.
Bringing SAM to new heights: Leveraging elevation data for tree crown segmentation from drone imagery
Jun 05, 2025Information on trees at the individual level is crucial for monitoring forest ecosystems and planning forest management. Current monitoring methods involve ground measurements, requiring extensive cost, time and labor. Advances in drone remote sensing and computer vision offer great potential for mapping individual trees from aerial imagery at broad-scale. Large pre-trained vision models, such as the Segment Anything Model (SAM), represent a particularly compelling choice given limited labeled data. In this work, we compare methods leveraging SAM for the task of automatic tree crown instance segmentation in high resolution drone imagery in three use cases: 1) boreal plantations, 2) temperate forests and 3) tropical forests. We also study the integration of elevation data into models, in the form of Digital Surface Model (DSM) information, which can readily be obtained at no additional cost from RGB drone imagery. We present BalSAM, a model leveraging SAM and DSM information, which shows potential over other methods, particularly in the context of plantations. We find that methods using SAM out-of-the-box do not outperform a custom Mask R-CNN, even with well-designed prompts. However, efficiently tuning SAM end-to-end and integrating DSM information are both promising avenues for tree crown instance segmentation models.
Structure-Aligned Protein Language Model
May 22, 2025Protein language models (pLMs) pre-trained on vast protein sequence databases excel at various downstream tasks but lack the structural knowledge essential for many biological applications. To address this, we integrate structural insights from pre-trained protein graph neural networks (pGNNs) into pLMs through a latent-level contrastive learning task. This task aligns residue representations from pLMs with those from pGNNs across multiple proteins, enriching pLMs with inter-protein structural knowledge. Additionally, we incorporate a physical-level task that infuses intra-protein structural knowledge by optimizing pLMs to predict structural tokens. The proposed dual-task framework effectively incorporates both inter-protein and intra-protein structural knowledge into pLMs. Given the variability in the quality of protein structures in PDB, we further introduce a residue loss selection module, which uses a small model trained on high-quality structures to select reliable yet challenging residue losses for the pLM to learn. Applying our structure alignment method to the state-of-the-art ESM2 and AMPLIFY results in notable performance gains across a wide range of tasks, including a 12.7% increase in ESM2 contact prediction. The data, code, and resulting SaESM2 and SaAMPLIFY models will be released on Hugging Face.
Self-Evolving Curriculum for LLM Reasoning
May 20, 2025



Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
Adaptive Cyclic Diffusion for Inference Scaling
May 20, 2025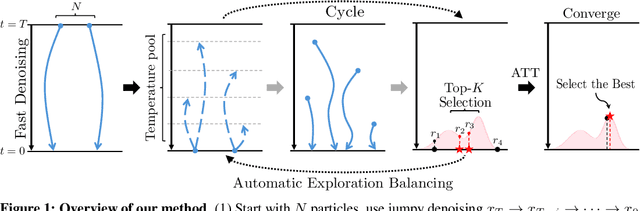

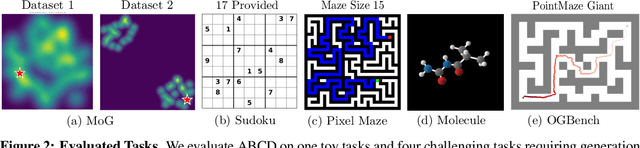
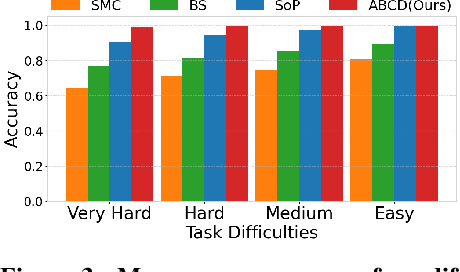
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.